欢迎关注公众号-AI圈终身学习。
公众号首页回复“机器学习”查看所有系列文章。
上节主要介绍了:
- 二元分类(Yes/No)问题
- 线性可分数据的感知器演算法(PLA)
- 针对线性不可分数据改进的贪心算法Pocket Algorithm。
本节笔记Lecture 3包含内容如下:
- 机器学习类型划分(Types of Learning)
- 根据不同的输出空间Y(Learning with Different Output Space Y)
- 根据不同的数据标签 (Learning with Different Data Label )
- 根据不同的协议(Learning with Different Protocol )
- 根据不同的输入(Learning with Different Input Space X)
一、根据不同的输出空间Y(Learning with Different Output Space Y)
这一节是概念性知识,很简单。不同的输出空间Y对应不一样的问题。目前我们只学了二分类问题,比如:是否批准信用卡,是否垃圾邮件,是否生病,广告是否赚钱,答案是否正确。这里的输出空间Y取值只有+1和-1两种情况。如果有:
- 识别数字0到9,则输出空间有10种,这叫多分类问题(Multiclass Classification)
- 预测病人需要多少天康复,则输出空间有无限种,这叫回归问题(Regression)
归纳一下,如果我们输出空间对应有:
- 两种,叫二分类问题(Binary Classification)
- 多种,叫多分类问题(Multiclass Classification)
- 无限种,叫回归问题(Regression)
二、根据不同的数据标签 (Learning with Different Data Label )
这一节也是概念性知识,很简单。不同的数据标签 对应不一样的学习方式。本节主要概念性讲:
- 监督学习(Supervised)
- 非监督学习(Unsupervised)
- 半监督学习(Semi-supervised)
- 强化学习(Reinforcement Learning)
目前我们学习的数据 一一对应,这种叫监督学习(supervised);
如果数据没有标签,则叫非监督学习(unsupervised),一般的应用场景都是聚类问题;
半监督学习(semi-supervised)数据有部分标签,一般也是聚类场景,相比于非监督学习,类别种类更确定;
强化学习是一种自然的学习方式,比如训练一条狗,叫它“
sit down”,如果它做了
就喂他饼干奖励它,否则就惩罚它。

其他的有比如广告系统、或者围棋等应用场景。通常用于学习顺序的’隐含’信息。
本节小总结如下:

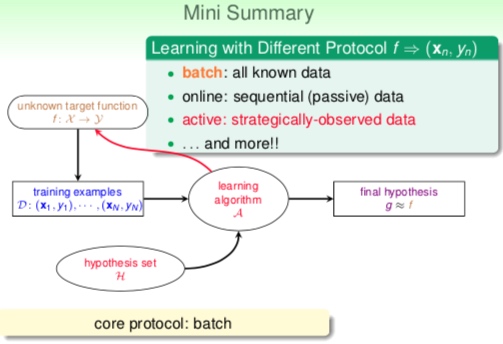
三、根据不同的协议(Learning with Different Protocol )
根据不同的协议可以把机器学习划分成三种:
- 批学习(Batch Learning)
- 在线学习(Online Learning)
- 主动学习(Active Learning)
批学习(Batch Learning)是比较常见的方式,直接喂给模型一批数学,让它直接学习。
在线学习(Online Learning)是通过一条条的数据慢慢学习。如果我们要提升垃圾邮件系统性能,则他们的流程如下:

PLA和强化学习可以轻松的使用在线学习协议,因为他们都是通过一条一条的数据不断的从假设集中选择更好的假设。
而主动学习(Active Learning)是去主动问问题,即通过某种策略(strategy)选择一条自己不确定数据,询问这条数据的标签。
本节总结就是根据协议可以把机器学习分成三种:Batch、Online、Acitve。他们可以类比成:填鸭式教育、举例教育、主动问问题。目前最重要的协议是Batch Learning。
思考一下这个问题:
一个摄影师有10W张图片,标记了1000张,现在对剩下的图片分类。对于算法认为确定的图片系统直接输出它的类别,如果不确定的询问人类,这是什么协议?

四、根据不同的输入(Learning with Different Input Space X)
在机器学习领域,输入特征一般分成三种类别:
- 具体的特征(concrete)
- 原始的特征(raw)
- 抽象的特征(abstract)
非常容易理解。
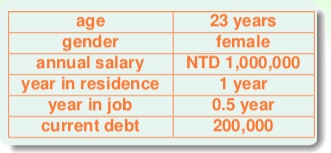
具体的特征(concrete)有复杂的物理意义,相对而言机器学习比较容易学习这类数据,比如银行客户的信息:
原始的特征(raw)如图像的原始像素,通常需要人为的转化成具体的特征,再喂给模型,比如识别手写数字的图像输入:

抽象的特征(abstract)比如数据里面每条数据的ID,通常没有物理含义,我们需要进行特征转换/提取/构造。
本节总结:

思考一下这个问题:
假设构建一个在线图片广告系统,推送与用户最相关的图片,我们能用哪些输入特征?

五、总结
本节主要讨论了机器学习的类型划分,比较轻松简单的一节:

文中思考题答案


