1 启动HDFS并运行MapReduce程序
a)配置:hadoop-env.sh
Linux系统中获取JDK的安装路径:
[root@hadoop001 hadoop-2.7.2]# echo $JAVA_HOME /opt/module/jdk1.8.0_144 [root@hadoop001 hadoop]# vim hadoop-env.sh
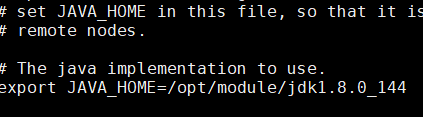
修改JAVA_HOME 路径:
(b)配置:core-site.xml
[root@hadoop001 hadoop]# cat core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property> </configuration> [root@hadoop001 hadoop]#
(c)配置:hdfs-site.xml
[root@hadoop001 hadoop]# cat hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> [root@hadoop001 hadoop]#
(2)启动集群
(a)格式化NameNode(第一次启动时格式化,以后就不要总格式化)
[root@hadoop001 hadoop-2.7.2]# bin/hdfs namenode -format 20/01/14 16:29:01 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = iZbp1efx14jd8471u20gpaZ/172.16.233.215 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.7.2 STARTUP_MSG: classpath = /opt/module/hadoop-2.7.2/etc/hadoop:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/curator-client-2.7.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/zookeeper-3.4.6.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-compress-1.4.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-math3-3.1.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/netty-3.6.2.Final.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/commons-httpclient-3.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/guava-11.0.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/log4j-1.2.17.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/stax-api-1.0-2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/hadoop-auth-2.7.2.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/jersey-json-1.9.jar:/opt/mo
(b)启动NameNode
[root@hadoop001 hadoop-2.7.2]# sbin/hadoop-daemon.sh start namenode starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-namenode-hadoop001.out
(c)启动DataNode
[root@hadoop001 hadoop-2.7.2]# sbin/hadoop-daemon.sh start datanode starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop001.out
(3)查看集群

(a)查看是否启动成功
[root@hadoop001 hadoop-2.7.2]# jps 23608 NameNode 23769 Jps 23691 DataNode [root@hadoop001 hadoo
注意:jps是JDK中的命令,不是Linux命令。不安装JDK不能使用jps
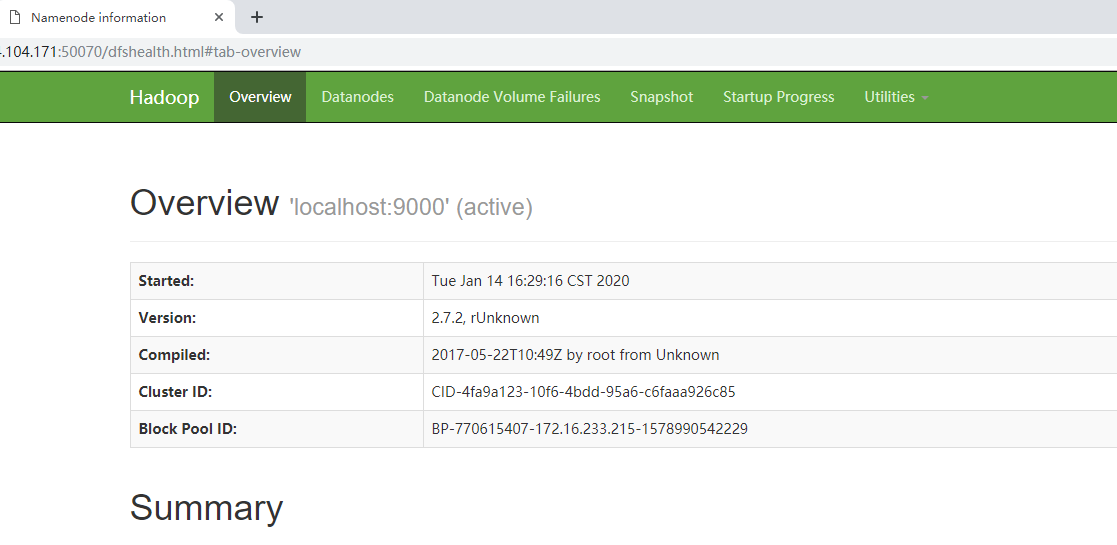
(b)web端查看HDFS文件系统
(c)查看产生的Log日志
说明:在企业中遇到Bug时,经常根据日志提示信息去分析问题、解决Bug。
当前目录:/opt/module/hadoop-2.7.2/logs
[root@hadoop001 hadoop-2.7.2]# cd /opt/module/hadoop-2.7.2/logs [root@hadoop001 logs]# ll total 60 -rw-r--r-- 1 root root 23889 Jan 14 16:29 hadoop-root-datanode-hadoop001.log -rw-r--r-- 1 root root 717 Jan 14 16:29 hadoop-root-datanode-hadoop001.out -rw-r--r-- 1 root root 27523 Jan 14 16:29 hadoop-root-namenode-hadoop001.log -rw-r--r-- 1 root root 717 Jan 14 16:29 hadoop-root-namenode-hadoop001.out -rw-r--r-- 1 root root 0 Jan 14 16:29 SecurityAuth-root.audit
(d)思考:为什么不能一直格式化NameNode,格式化NameNode,要注意什么?
[root@hadoop001 hadoop-2.7.2]# cd data/tmp/dfs/name/current/ [root@hadoop001 current]# ll total 1040 -rw-r--r-- 1 root root 1048576 Jan 14 16:29 edits_inprogress_0000000000000000001 -rw-r--r-- 1 root root 351 Jan 14 16:29 fsimage_0000000000000000000 -rw-r--r-- 1 root root 62 Jan 14 16:29 fsimage_0000000000000000000.md5 -rw-r--r-- 1 root root 2 Jan 14 16:29 seen_txid -rw-r--r-- 1 root root 206 Jan 14 16:29 VERSION [root@hadoop001 current]# cat VERSION #Tue Jan 14 16:29:02 CST 2020 namespaceID=1486374433 clusterID=CID-4fa9a123-10f6-4bdd-95a6-c6faaa926c85 cTime=0 storageType=NAME_NODE blockpoolID=BP-770615407-172.16.233.215-1578990542229 layoutVersion=-63 [root@hadoop001 current]# cd ../../data/current/ [root@hadoop001 current]# ll total 8 drwx------ 4 root root 4096 Jan 14 16:29 BP-770615407-172.16.233.215-1578990542229 -rw-r--r-- 1 root root 229 Jan 14 16:29 VERSION [root@hadoop001 current]# cat VERSION #Tue Jan 14 16:29:47 CST 2020 storageID=DS-b07b5055-82c9-4010-a583-dd75fe1e1097 clusterID=CID-4fa9a123-10f6-4bdd-95a6-c6faaa926c85 cTime=0 datanodeUuid=9002013a-cc17-4ae7-886f-3f0ef4d44595 storageType=DATA_NODE layoutVersion=-56
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
(4)操作集群
(a)在HDFS文件系统上创建一个input文件夹
[root@hadoop001 hadoop-2.7.2]# bin/hdfs dfs -mkdir -p /user/topcheer/input
(b)将测试文件内容上传到文件系统上
[root@hadoop001 hadoop-2.7.2]# bin/hdfs dfs -put wcinput/wc.input /user/topcheer/input/
(c)查看上传的文件是否正确
[root@hadoop001 hadoop-2.7.2]# bin/hdfs dfs -lsr / lsr: DEPRECATED: Please use 'ls -R' instead. drwxr-xr-x - root supergroup 0 2020-01-14 16:45 /user drwxr-xr-x - root supergroup 0 2020-01-14 16:45 /user/topcheer drwxr-xr-x - root supergroup 0 2020-01-14 16:53 /user/topcheer/input -rw-r--r-- 1 root supergroup 48 2020-01-14 16:53 /user/topcheer/input/wc.input
(d)运行MapReduce程序
[root@hadoop001 hadoop-2.7.2]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/topcheer/input/ /user/topcheer/output/ 20/01/14 17:08:35 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id 20/01/14 17:08:35 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId= 20/01/14 17:08:35 INFO input.FileInputFormat: Total input paths to process : 1 20/01/14 17:08:35 INFO mapreduce.JobSubmitter: number of splits:1 20/01/14 17:08:35 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local330020084_0001 20/01/14 17:08:36 INFO mapreduce.Job: The url to track the job: http://localhost:8080/ 20/01/14 17:08:36 INFO mapreduce.Job: Running job: job_local330020084_0001 20/01/14 17:08:36 INFO mapred.LocalJobRunner: OutputCommitter set in config null
(e)查看输出结果
命令行查看:
[root@hadoop001 hadoop-2.7.2]# bin/hdfs dfs -cat /user/topcheer/output/* hadoop 2 mapreduce 1 topcheer 2 yarn 1 [root@hadoop001 hadoop-2.7.2]#
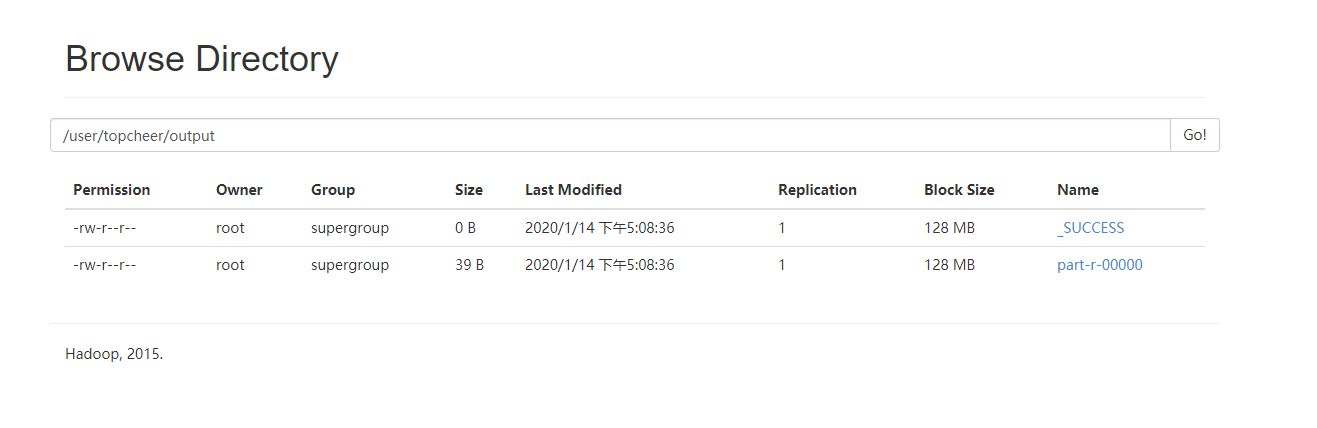
浏览器查看,如图所示
(f)将测试文件内容下载到本地
[root@hadoop101 hadoop-2.7.2]$ hdfs dfs -get /user/topcheer/output/part-r-00000 ./wcoutput/
2 启动YARN并运行MapReduce程序
(1)配置集群
(a)配置yarn-env.sh
配置一下JAVA_HOME

(b)配置yarn-site.xml
<configuration> <!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop001</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志保留时间设置7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
(c)配置:mapred-env.sh
配置一下JAVA_HOME
[root@hadoop001 hadoop]# cat mapred-env.sh # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # export JAVA_HOME=/home/y/libexec/jdk1.6.0/ export JAVA_HOME=/opt/module/jdk1.8.0_144 export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000 export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA #export HADOOP_JOB_HISTORYSERVER_OPTS= #export HADOOP_MAPRED_LOG_DIR="" # Where log files are stored. $HADOOP_MAPRED_HOME/logs by default. #export HADOOP_JHS_LOGGER=INFO,RFA # Hadoop JobSummary logger. #export HADOOP_MAPRED_PID_DIR= # The pid files are stored. /tmp by default. #export HADOOP_MAPRED_IDENT_STRING= #A string representing this instance of hadoop. $USER by default #export HADOOP_MAPRED_NICENESS= #The scheduling priority for daemons. Defaults to 0. [root@hadoop001 hadoop]#
(d)配置: (对mapred-site.xml.template重新命名为) mapred-site.xml
[root@hadoop001 hadoop]# mv mapred-site.xml.template mapred-site.xml [root@hadoop001 hadoop]# vim mapred-site.xml
[root@hadoop001 hadoop]# cat mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- 指定MR运行在YARN上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop001:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop001:19888</value> </property> </configuration> [root@hadoop001 hadoop]#
(2)启动集群
(a)启动前必须保证NameNode和DataNode已经启动
(b)启动ResourceManager
[root@hadoop001 hadoop-2.7.2]# sbin/yarn-daemon.sh start resourcemanager starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-resourcemanager-hadoop001.out
(c)启动NodeManager
[root@hadoop001 hadoop-2.7.2]# sbin/yarn-daemon.sh start nodemanager starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-hadoop001.out
(3)集群操作
(a)YARN的浏览器页面查看,如图2-35所示
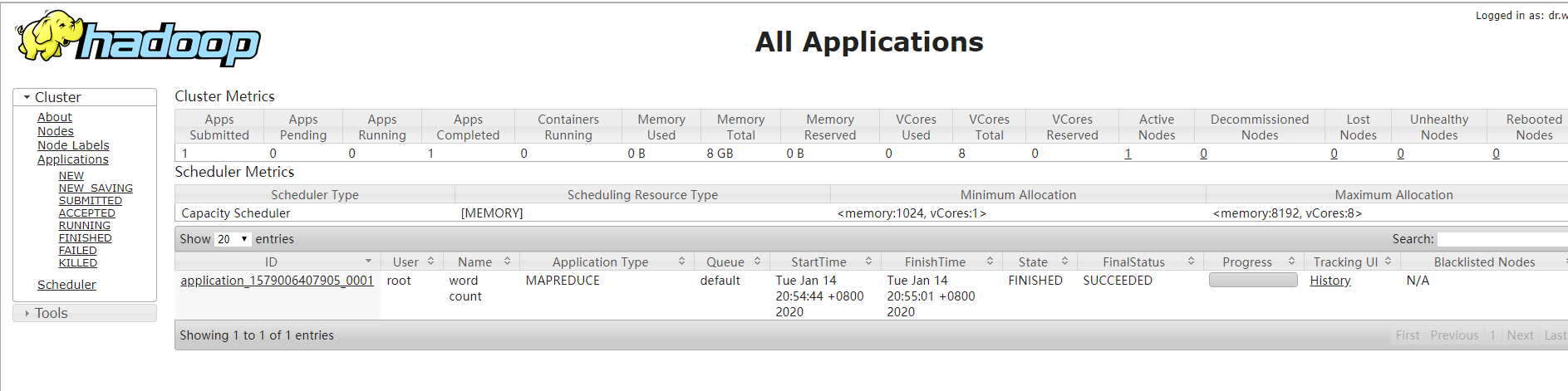
(b)删除文件系统上的output文件
[root@hadoop001 hadoop-2.7.2]# bin/hdfs dfs -rm -R /user/topcheer/output 20/01/14 20:23:56 INFO fs.TrashPolicyDefault: Namenode trash configuration: Dele tion interval = 0 minutes, Emptier interval = 0 minutes. Deleted /user/topcheer/output
(c)执行MapReduce程序
[root@hadoop001 hadoop-2.7.2]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapr educe-examples-2.7.2.jar wordcount /user/topcheer/input /user/topcheer/output 20/01/14 20:25:53 INFO client.RMProxy: Connecting to ResourceManager at hadoop00 1/172.16.233.215:8032 20/01/14 20:25:54 INFO input.FileInputFormat: Total input paths to process : 1 20/01/14 20:25:54 INFO mapreduce.JobSubmitter: number of splits:1 20/01/14 20:25:54 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_15 79004405060_0001 20/01/14 20:25:54 INFO impl.YarnClientImpl: Submitted application application_15
(d)查看运行结果,如图所示

3 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
1. 配置mapred-site.xml
[root@hadoop001 hadoop]# vim mapred-site.xml [root@hadoop001 hadoop]#
在该文件里面增加如下配置。
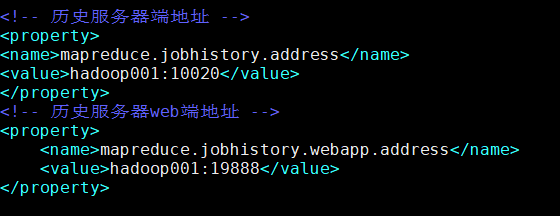
2. 启动历史服务器
[root@hadoop001 hadoop-2.7.2]# sbin/mr-jobhistory-daemon.sh start historyserver starting historyserver, logging to /opt/module/hadoop-2.7.2/logs/mapred-root-historyserver-hadoop001.out [root@hadoop001 hadoop-2.7.2]# jps 24836 ResourceManager 25749 JobHistoryServer 25093 NodeManager 23608 NameNode 25787 Jps 23691 DataNode
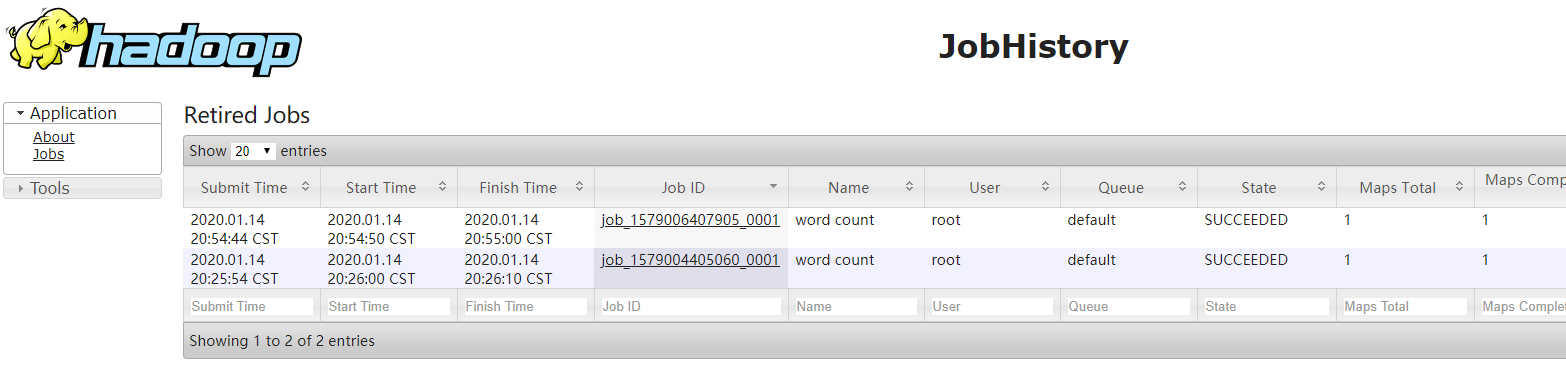
3. 查看JobHistory
http://hadoop001:19888/jobhistory
44 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
- 配置yarn-site.xml
[root@hadoop001 hadoop]# vi yarn-site.xml [root@hadoop001 hadoop]# cd ../../
在该文件里面增加如下配置。

- 关闭NodeManager 、ResourceManager和HistoryManager
root@hadoop001 hadoop-2.7.2]# sbin/yarn-daemon.sh stop resourcemanager stopping resourcemanager [root@hadoop001 hadoop-2.7.2]# jps 25905 Jps 25749 JobHistoryServer 25093 NodeManager 23608 NameNode 23691 DataNode [root@hadoop001 hadoop-2.7.2]# sbin/yarn-daemon.sh stop nodemanager stopping nodemanager nodemanager did not stop gracefully after 5 seconds: killing with kill -9 [root@hadoop001 hadoop-2.7.2]# sbin/mr-jobhistory-daemon.sh stop historyserver stopping historyserver
启动NodeManager 、ResourceManager和HistoryManager
[root@hadoop001 hadoop-2.7.2]# sbin/yarn-daemon.sh start resourcemanager starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-resourcemanager-hadoop001.out [root@hadoop001 hadoop-2.7.2]# sbin/yarn-daemon.sh start nodemanager starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-hadoop001.out [root@hadoop001 hadoop-2.7.2]# sbin/mr-jobhistory-daemon.sh start historyserver starting historyserver, logging to /opt/module/hadoop-2.7.2/logs/mapred-root-historyserver-hadoop001.out [root@hadoop001 hadoop-2.7.2]# jps 26390 JobHistoryServer 25991 ResourceManager 23608 NameNode 23691 DataNode 26428 Jps 26237 NodeManager
删除HDFS上已经存在的输出文件
[root@hadoop001 hadoop-2.7.2]# bin/hdfs dfs -rm -R /user/topcheer/output 20/01/14 20:54:21 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes. Deleted /user/topcheer/output
执行WordCount程序
[root@hadoop001 hadoop-2.7.2]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/topcheer/input /user/topcheer/output 20/01/14 20:54:43 INFO client.RMProxy: Connecting to ResourceManager at hadoop001/172.16.233.215:8032 20/01/14 20:54:43 INFO input.FileInputFormat: Total input paths to process : 1 20/01/14 20:54:43 INFO mapreduce.JobSubmitter: number of splits:1 20/01/14 20:54:44 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1579006407905_0001 20/01/14 20:54:44 INFO impl.YarnClientImpl: Submitted application application_1579006407905_0001
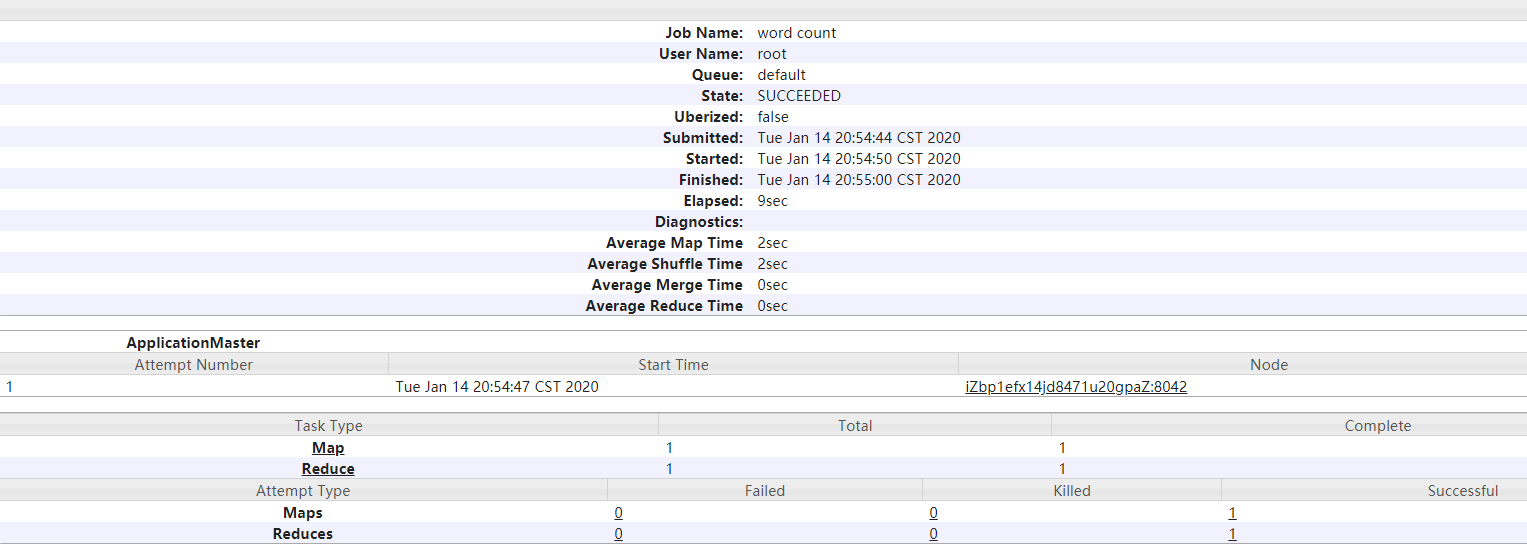
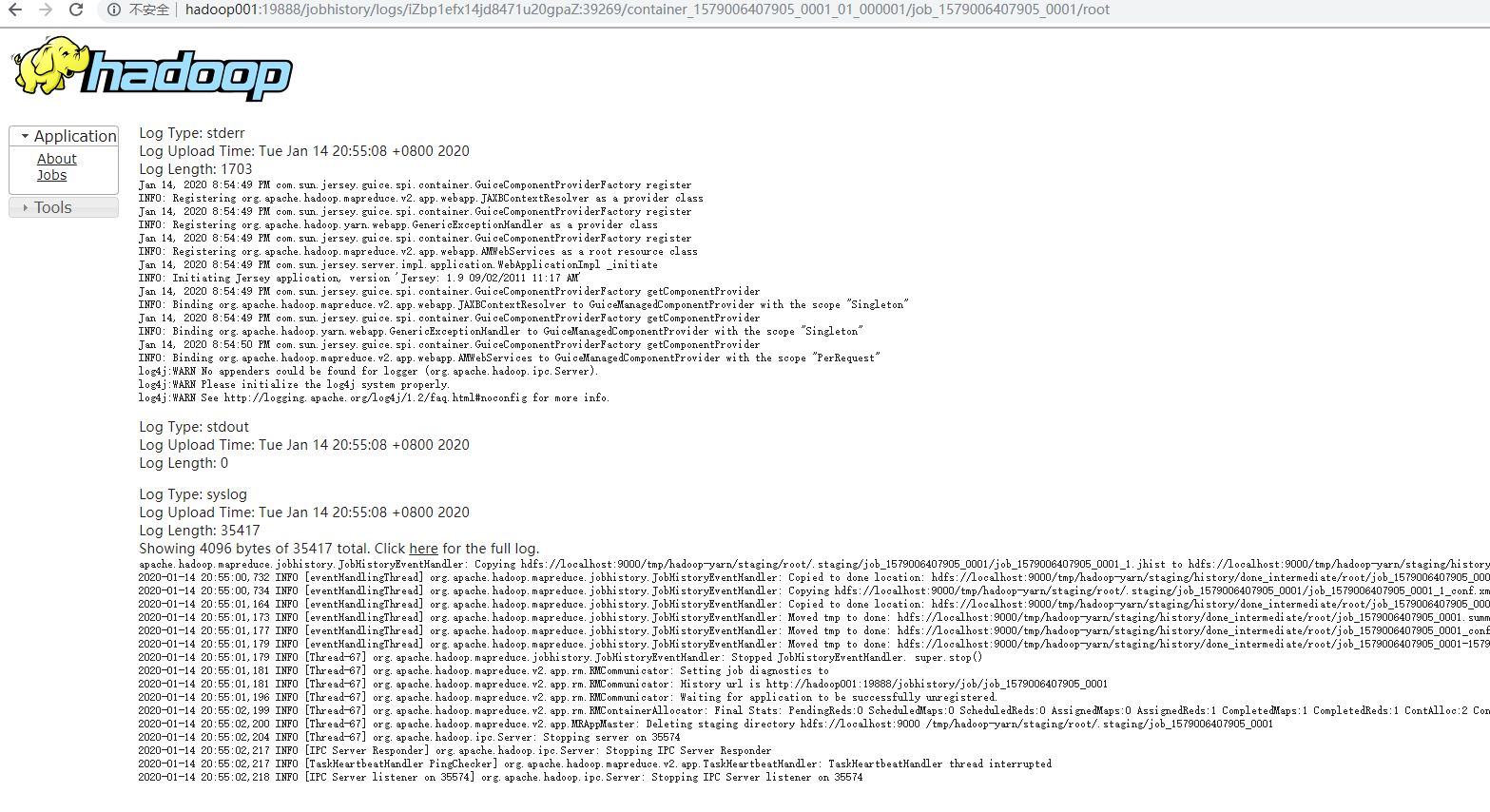
- 查看日志,如图所示

5 配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件:
表2-1
| 要获取的默认文件 |
文件存放在Hadoop的jar包中的位置 |
| [core-default.xml] |
hadoop-common-2.7.2.jar/ core-default.xml |
| [hdfs-default.xml] |
hadoop-hdfs-2.7.2.jar/ hdfs-default.xml |
| [yarn-default.xml] |
hadoop-yarn-common-2.7.2.jar/ yarn-default.xml |
| [mapred-default.xml] |
hadoop-mapreduce-client-core-2.7.2.jar/ mapred-default.xml |
(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。