capacity永远为2的幂
我们都知道HashMap的容量永远为2的幂,而HashMap没有一个成员名叫capacity,capacity是作为table这个数组的size而隐式存在的。
当用户构造HashMap时给了一个奇怪的容量时,会通过this.threshold = tableSizeFor(initialCapacity)计算出一个刚好大于或等于用户给定容量的2的幂。比如,用户给了10,计算出16;给了16,也计算出16。
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
接下来开始讲解:
- 先忽略最前面减一和最后面加一的操作,先理解这五次位或的操作。看下图,先假设n的bit为
000000...01XXXXXXXXXX...XXXXX,这里的1代表的是左起的第一个1,后面的X代表不确定(0或1)。那么位或的过程如下图所示:
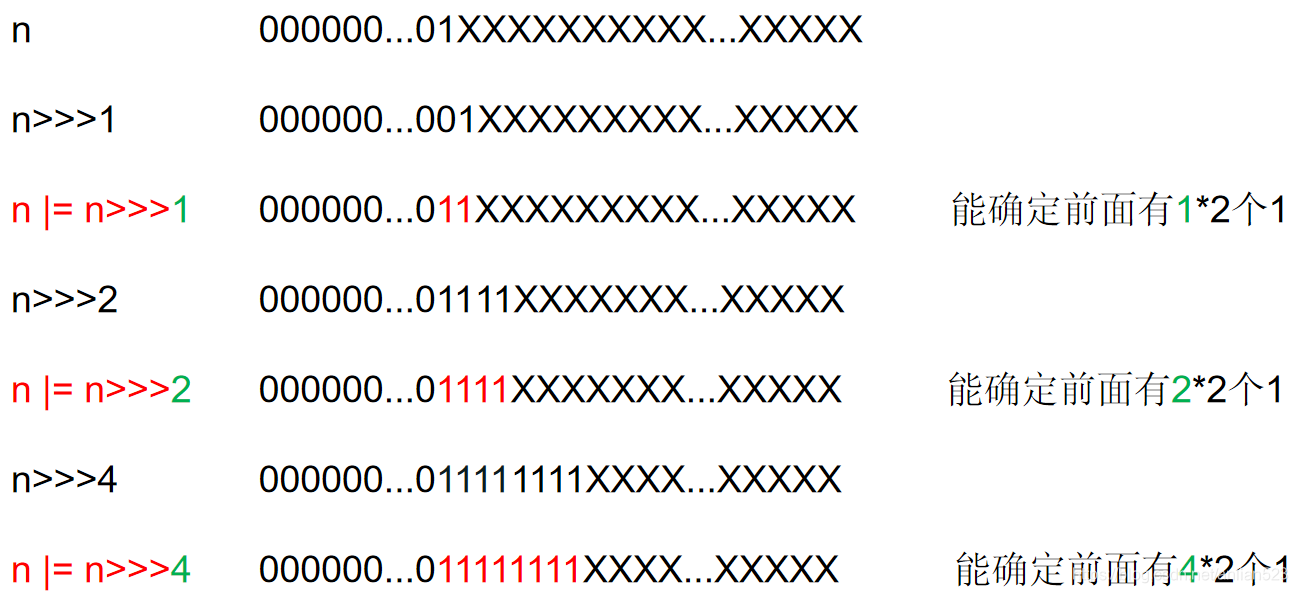
- 可见刚开始的时候,只知道n的bit位最前面有一个1。但执行了
n |= n >>> 1后,就能确定前面有1*2个1了;执行了n |= n >>> 2后,就能确定前面有2*2个1了。按照这个过程,执行了n |= n >>> 16,就能确定前面有16*2个1了。但是int总共才4个字节,32个bit,也就是说,执行完这5次位或后,左起第一个1后面的所有bit肯定都会变成1,只不过如果n比较小的话,在少于5次的位或操作时,就已经使得左起第一个1后面全为1了。 - 而之所以有最后的
n+1操作,是因为前面的位或操作已经让左起第一个1直到最后的bit都变成了1,形如000111...11111,此时再加1,就可以使得n变成2的次方,形如001000...00000。此函数的目的就是返回2的幂作为容量。加一操作的作用:使得五次位或后的n变成2的幂。 - 之所以有前面的
int n = cap - 1操作,是因为如果参数cap刚好是2的次方时,此函数希望返回这个数本身。比如cap是1000:如果没有减一操作,那么执行完位或操作后,变成了1111,再加个1,就变成了10000;但现在有了减一操作,减一后为0111,再执行位或操作后,还是0111,再加个1,就变回它本身1000了。减一操作的作用:使得形参cap刚好为2的幂时返回它本身。 - 最后的
(n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1,就是最大容量的判断,最终确定的容量不能比MAXIMUM_CAPACITY还大了。MAXIMUM_CAPACITY的定义是1 << 30即01000...000,因为有符号数的最高位bit是符号位,所以它已经是正数范围内最大的2的次方了。如果五次位或后算出来的n比1 << 30还大(那么肯定是01111...111),再加个1就得溢出了。
取table下标时,用&操作不用取余
整个HashMap源码里随处可见这样的取下标操作first = tab[(n - 1) & hash](这里n为table的大小即capacity,hash为key的哈希值),其实正常来说,这里取下标,我们应该使用hash % n的,这样就能计算出一个在0 ~ n-1 范围内的数字作为数组的下标。但是由于capacity永远为2的幂,所以这里的n也为这个2的幂。
当n为2的幂时,用(n - 1) & hash得到的结果,和hash % n是一样的。

- 假设现在n为
1000,减一之后为0111。如果hash为...QWERXYZ,那么执行&操作后,hash就为变成000...000XYZ即XYZ。 - 从范围上来讲,之前要求的范围是
0 ~ 7,现在3位bitXYZ的可能范围也为0 ~ 7。 - 从原理上来讲,
0111相当于起到了一个掩码的作用,与0111进行&操作后,最后3位bit得到保留,其余bit全部归零。 - 从权值上来讲,最低位bit的权值为1(
),倒数第二位bit的权值为2(
)…以此类推。那么,与
0111(1000减一后得到)进行&操作后,将会舍弃掉所有权值>= 的bit,只保留 、 、 的权值的bit。这不刚好就是完美的一次“取余”操作么!
resize()里的链表分离
截取部分源码如下:
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
// 在do的逻辑里,是为了把e存到low或者high链表里
// 在do的逻辑里,next只是存一下e的下一个元素
next = e.next;
// 现在多了一个bit能到影响元素的新table下标,所以看这个bit是否等于0
// 如果这个bit等于0,说明新table下标和旧table下标是一样的
if ((e.hash & oldCap) == 0) {
// 如果low链表的head和tail还没初始化,这里只要执行过一次,head和tail都不会是null的
if (loTail == null)
loHead = e;
else
loTail.next = e;// 把e赋值给tail的后继
loTail = e;//更新tail
}
// 如果这个bit等于1,说明新table下标和旧table下标不一样的
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);//将do逻辑里存的next赋值给e,把e这个指针往后移动,因为do逻辑已经处理了e
// 如果哈希桶里,所有元素的那个bit都为1,那么它们都会存到high链表里去。自然low链表为null
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 如果哈希桶里,所有元素的那个bit都为0,那么它们都会存到low链表里去。自然high链表为null
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
resize函数会进行扩容和再哈希处理,会把哈希桶里的各个元素单独拎出来,看它是应该放在原哈希桶里面呢,还是应该放在新哈希桶里面。
但是注意,新哈希桶的下标居然是直接用j + oldCap算出来的(j为原哈希桶的下标,oldCap为旧容量),接下来将进行讲解:
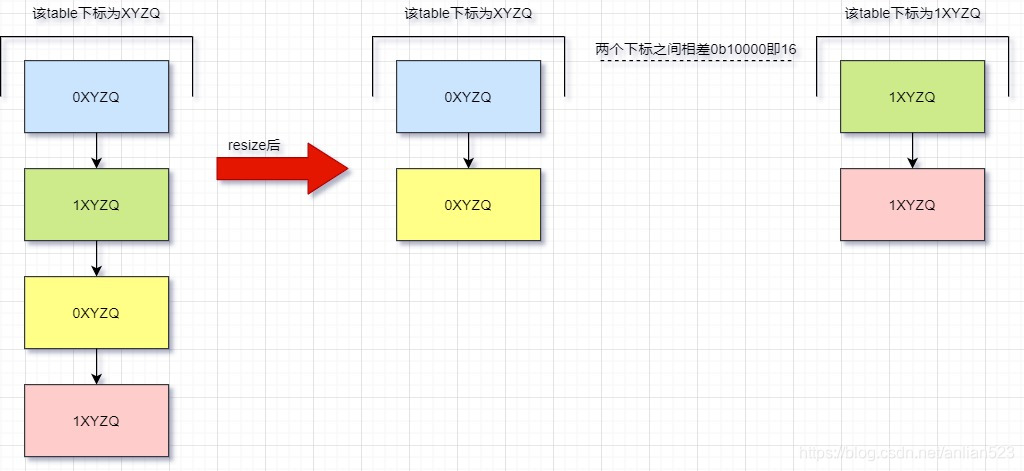
- 假设旧容量是
0b10000即16,那么可能的table下标范围为0b0000 - 0b1111,即能影响到元素所在table下标的bit只有后4位bit0b????。 - 假设有四个元素,它们的hash值的最后4位bit都是
XYZQ,由于当前容量16的限制,它们会被放置到同一个哈希桶(table下标为0bXYZQ)里。 - 现在resize里扩容后,新容量升为
0b100000即32,所以现在能影响到元素所在table下标的bit只有后5位bit0b?????,但相比之前,只有右起第5位bit可能发生变化。 - 所以,如果这个关键bit为0,那么元素还是处于原table下标,如果这个关键bit为1,那么元素处于 原table下标+旧容量 的新下标。
- 图中可见,原下标与新下标的相差值,刚好就是旧容量
0b10000。 - 图中通过颜色来表示不同的元素,注意链表分离后,它们也能保持之前的相对位置。比如,蓝色元素还是在黄色元素前面,这是因为do while循环是按照原顺序处理的。
静态函数hash()
此函数是用来计算Key的hash值的。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 这里把key的hashCode与它本身无符号右移16位的异或结果作为返回值。
- 根据之前提到的table数组取下标的操作,可以得知:当capacity比较小时,那么永远只有hash值的那几个低位bit能够影响到计算出来的table下标,而这可能会造成更多的哈希冲突。
- 所以源码里使用了
(h = key.hashCode()) ^ (h >>> 16),这样哈希值的高16位还是保持不变(因为无符号右移填充0,0异或任何数是它本身),哈希值的低16位受到高16位影响后,可能会发生改变。右移16位是因为int总共只有32个bit,所以要右移一半的bit,即16个bit。
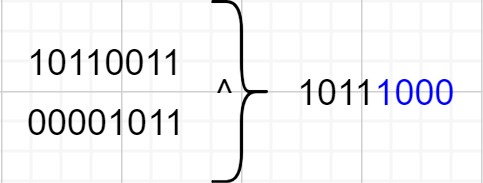
以8位bit为例,无符号右移一半的bit后,再异或起来。那么,前一半bit不变,后一半bit则受到了扰动。
其他
本文基于jdk8的源码。
