代换密码的密码分析
使用单表代换密码,对于给出的密文进行分析并得到结果,了解加密解密过程
密文信息如下:AHNFCROACOAHNISEFLCIASFVCNWOSEAHNWSRLDWCAHCEIRNTONDATRCFFOSEOANNLTEDTLUMCEUMFRSMAHNNUITETDTTEDJTPTEAHNUOWCNLDOCAOATRCFFBTASETGTCEOACAOARTDCACSETLTLLCNOTAAHNOTMNACMNCACODNMTEDCEGAHTATFRCITEISUEARCNOOUIHTORWTEDTTEDUGTEDTRNMSVNCMPSRAATRCFFOSEONISEDHTEDILSAHNOFRSMAHNUOAHTAVCNWSEAHNWSRLDCOKESWETOTMNRCITFCROATEDCAMNTEOAHTATEYSENONNETOHTVCEGMSVNDTMNRCITOIHNNONBNCATETLLYSRESACOPUECOHNDBYISEARTOAIHCETONNOCAORNLTACSEOWCAHAHNWSRLDTOBTONDSEMUAUTLRNOPNIAFTCRENOOJUOACINTEDWCEWCEISSPNRTACSETEDTCMOASOTFNGUTRDWSRLDPNTINTEDPRSMSANISMMSEDNVNLSPMNEACACOWCLLCEGASWSRKWCAHAHNRNOASFAHNWSRLDASMTKNAHNCEANRETACSETLGSVNRETEINOYOANMFTCRNRTEDMSRNRNTOSETBLNTEDBUCLDTENWAYPNSFCEANRETACSETLRNLTACSEOTEDTISMMUECAYWCAHTOHTRNDFUAURNFSRMTEKCED
对上面密码使用各种方法进行解密,得到明文信息
解密原理:
替代密码是指先建立一个替换表,加密时将需要加密的明文依次通过查表,替换为相应的字符,明文字符被逐个替换后,生成无任何意义的字符串,即密文,替代密码的密钥就是其替换表。根据密码算法加解密时使用替换表多少的不同,替代密码又可分为单表替代密码和多表替代密码。单表替代密码的密码算法加解密时使用一个固定的替换表。单表替代密码又可分为一般单表替代密码、移位密码、仿射密码、密钥短语密码。
思路步骤:
-
尝试使用穷举法获得明文。程序a:字母代换程序
-
程序实现统计密文中的英文字母频率。 程序b:字母统计程序
-
根据统计结果和常用字母频率表,假设字母代换的规则(1-1代换),用密文来验证假设的正确与否,若不成立,则继续假设,一直到找到明文为止。 程序a:字母代换程序
-
给出明文及密钥(字母代换规则表)。
在进行实验的过程之中,我将会使用2种不同的方法来对这次实验的内容分别进行验证和解决,分别为通过大量测试的聚合算法和分别进行频率分析来对这个实验进行解决。
一、使用频率分析法进行密文分析:
频率法就是我们对密文进行分析,只要这个内容不是特殊的内容,他固定单词的频率会出现多次,这个方法主要基于密文的量多,量多固定使用的单词频率也就会多。比如说the、and、for这些英文在英文文章中出现的频率会很多。
频率分析法主要思路:
-
第一步:统计出密文字母出现的各个频次;
-
第二步:根据密文字母出现的频次统计,确定出某些密文字母对应的明文字母是否可能是单个字母频率统计表之中的哪类字母;
-
第三步是利用自然语言的文字结合规律进行猜测分析,对各类单词之中字母出现的频率进行对应猜测,同时也需要利用双字母、三字母统计特性以及元音辅音的拼写知识进行猜测。
-
第四步就是整理我们进行猜测的明文字母,对恢复得到的明文进行整理分析。
对文本词频分析.py
# 统计频率
def getLetterList():
c_file = open('c_text.txt') # 读取文件
c_text = c_file.read() # 读取文本
char_list = list(c_text) # 转化为列表,每个字母为一个元素
# 统计加密字符串中各个字母的出现次数
# Q X Z
tempSet = set(char_list) # 抓转为集合去重
# 保存为字典,key:字母,value:出现次数
tempDict = {}
for i in tempSet:
tempDict[i] = char_list.count(i)
# 列表排序, 以元组形式
dict_sorted = sorted(tempDict.items(), key=lambda x: x[1], reverse=True)
# print(dict_sorted)
frequency_list = []
print("字母", "出现次数", "频率")
for i in dict_sorted:
print(i[0], "\t", i[1], "\t", i[1] / len(c_text))
frequency_list.append(i[0]) # 按照出现频率写入到列表
return frequency_list
getLetterList()
对二元英文进行词频分析.py
# 统计频率
def get2WordList():
c_file = open('c_text.txt') # 读取文件
c_text = c_file.read() # 读取文本
char_list = list(c_text) # 转化为列表,每个字母为一个元素
word_list2 = []
temp_list = []
try:
for i in range(0, len(char_list)-1):
temp_list.append(char_list[i])
temp_list.append(char_list[i + 1])
temp_str = "".join(temp_list)
word_list2.append(temp_str)
temp_list = []
except StopIteration:
print()
# 统计加密字符串中各个二元字母的出现次数
tempSet = set(word_list2) # 抓转为集合去重
# 保存为字典,key:字母,value:出现次数
tempDict = {}
for i in tempSet:
tempDict[i] = word_list2.count(i)
# 列表排序, 以元组形式
dict_sorted = sorted(tempDict.items(), key=lambda x: x[1], reverse=True)
# print(dict_sorted)
frequency_list = []
print("2元字母", "出现次数", "\t频率")
for i in dict_sorted:
print(i[0], "\t\t", i[1], "\t\t", i[1] / len(c_text))
frequency_list.append(i[0]) # 按照出现频率写入到列表
return frequency_list
get2WordList()
对三元英文进行词频分析.py
# 统计频率
def get3WordList():
c_file = open('c_text.txt') # 读取文件
c_text = c_file.read() # 读取文本
char_list = list(c_text) # 转化为列表,每个字母为一个元素
word_list3 = []
temp_list = []
try:
for i in range(0, len(char_list)-2):
temp_list.append(char_list[i])
temp_list.append(char_list[i + 1])
temp_list.append(char_list[i + 2])
temp_str = "".join(temp_list)
word_list3.append(temp_str)
temp_list = []
except StopIteration:
print()
# 统计加密字符串中各个二元字母的出现次数
tempSet = set(word_list3) # 抓转为集合去重
# 保存为字典,key:字母,value:出现次数
tempDict = {}
for i in tempSet:
tempDict[i] = word_list3.count(i)
# 列表排序, 以元组形式
dict_sorted = sorted(tempDict.items(), key=lambda x: x[1], reverse=True)
# print(dict_sorted)
frequency_list = []
print("3元字母", "出现次数", "\t频率")
for i in dict_sorted:
print(i[0], "\t\t", i[1], "\t\t", i[1] / len(c_text))
frequency_list.append(i[0]) # 按照出现频率写入到列表
return frequency_list
get3WordList()
通过使用上述一元、二元、三元对密文之中的英文字母出现频次进行分析,我们可以得到下面的结果,分别是单字母、双字母、三字母进行统计得到的频率:


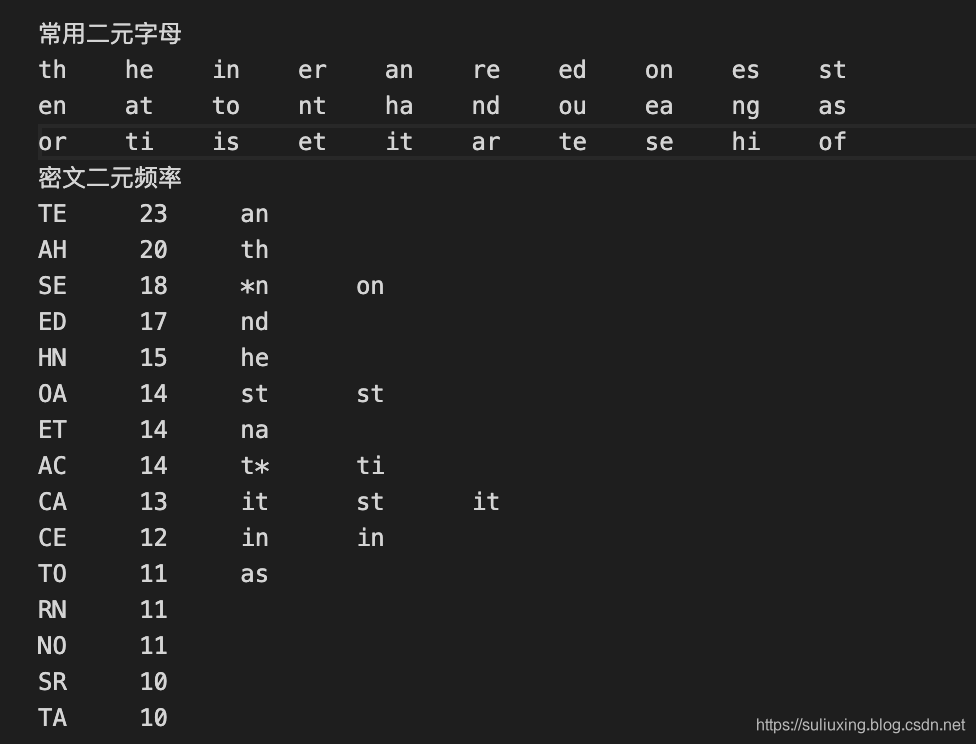


在上面分别对各个代码算法得到的字母频率进行统计,得到的结果值得我们进行分析并进行字母猜测,在下面我们对得到的信息进行合理化猜测并进行验证。由此可以得到三元之中密文TED对应着英文中的and、AHN对应着the、ACS对应着tio、CSE对应着ion、SET对应着ona,继续细细向下进行分析。
经过对词典以及各类单词进行详细的猜测分析,以及出现的频率进行统计分析,我们逐渐接近明文,因为有一些词汇为低频词汇,上面不少的词汇并未作出改变,原字母保持不变,因此,我们并未对其进行代换变化,经过分析如下所示,得到明文结果。

二、使用算法大量聚合进行密文分析
这个方法的原理就是选择不同的解密密钥进行破解尝试,然后通过计算每一个解密得到的明文的适应度,也就是符合英文单词语法的程度,如果解密得到的明文越接近我们日常使用的英语文章,它的那个适应度的值就会越高,如果大多数单词不对,那么适应度就会越低。
主要思路步骤:
-
第一步,我们随机生成一个密钥,用它来进行代换解密,解出得到的明文m1,对明文进行适应度计算,第一个适应度为d1。
-
第二步,随机交换之前生成的密钥之中的两个字符,我们得到子密钥child,解密出对应的明文m2,同时计算适应度d2。
-
第三步,对d1、d2进行比较,如果d1 < d2,那么child成为新的密钥。
-
第四步,对第二步、第三步进行多次循环1000次,直到无法生成得到更高的适应度,此时得到的密钥最有可能就是我们密文的解密密钥。
-
第五步,通过设置一个标志量flag来对循环进行终止操作,如果当最高值不进行满足的话,我们就跳出循环,防止陷入局部最优的困境,对于生成明文的适应度主要就是对不同解密密钥进行比较,解密出来得到的明文适应度越高,密钥就越好,适应度的计算方法我们通过使用quadgram statistics来进行计算。
# -*- coding: utf-8 -*-
# __author__ = "苏柳欣" [email protected]
# Date: 2019-11-29 Python: 2.7.16
import random
import sys
sys.path.append('/Users/Iro/code/CodeSupport/ngram_score.py')
from ngram_score import *
from math import *
# 1.随机生成一个key,称为parentkey,用它解密得对应的明文m1,对明文计算适应度d1
# 2.随机交换parentkey中的两个字符得到子密钥child,解密出对应的明文m2并计算适应度d2
# 3.若d1<d2,则child成为新的parentkey
# 4.不断循环进行步骤2、3直到最后的1000次循环中不再有更高的适应度生成
# 5.回到1重新生成parentkey继续迭代寻找,或者由操作者终止程序
# 重新执行1,是为了防止2、3的操作使结果陷入局部最优的困境。对于生成的明文的适应度的比较
# 其实可以看作是对不同解密密钥的比较,解密出来的明文的适应度越高,对应的密钥就更好。
# quadgram statistics的适应度计算方法
ciphertext = 'AHNFCROACOAHNISEFLCIASFVCNWOSEAHNWSRLDWCAHCEIRNTONDATRCFFOSEOANNLTEDTLUMCEUMFRSMAHNNUITETDTTEDJTPTEAHNUOWCNLDOCAOATRCFFBTASETGTCEOACAOARTDCACSETLTLLCNOTAAHNOTMNACMNCACODNMTEDCEGAHTATFRCITEISUEARCNOOUIHTORWTEDTTEDUGTEDTRNMSVNCMPSRAATRCFFOSEONISEDHTEDILSAHNOFRSMAHNUOAHTAVCNWSEAHNWSRLDCOKESWETOTMNRCITFCROATEDCAMNTEOAHTATEYSENONNETOHTVCEGMSVNDTMNRCITOIHNNONBNCATETLLYSRESACOPUECOHNDBYISEARTOAIHCETONNOCAORNLTACSEOWCAHAHNWSRLDTOBTONDSEMUAUTLRNOPNIAFTCRENOOJUOACINTEDWCEWCEISSPNRTACSETEDTCMOASOTFNGUTRDWSRLDPNTINTEDPRSMSANISMMSEDNVNLSPMNEACACOWCLLCEGASWSRKWCAHAHNRNOASFAHNWSRLDASMTKNAHNCEANRETACSETLGSVNRETEINOYOANMFTCRNRTEDMSRNRNTOSETBLNTEDBUCLDTENWAYPNSFCEANRETACSETLRNLTACSEOTEDTISMMUECAYWCAHTOHTRNDFUAURNFSRMTEKCED'
parentkey = list('ABCDEFGHIJKLMNOPQRSTUVWXYZ')
sss = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
# 上面将密文存入变量中,在设定一个目前的字符替换标准
# 下面的key就是用来声明字典key
key = {'A':'A'}
# 导入quadgrams.txt文本来进行适应度分析计算
fitness = ngram_score('/Users/Iro/code/CodeSupport/quadgrams.txt')
parentscore = -99e9
maxscore = -99e9
j = 0
flag = 1
print('开始进行密文分析 QAQ ')
while flag:
j = j + 1
random.shuffle(parentkey) # 进行随机打乱
for i in range(len(parentkey)):
key[parentkey[i]] = chr(ord('A') + i)
decipher = ciphertext
for i in range(len(decipher)):
decipher = decipher[:i] + key[decipher[i]] + decipher[i + 1:]
parentscore = fitness.score(decipher)
count = 0
while count < 1000: # 进行1000次的适应度计算,预计会达到峰值
''' 下面是进行适应度的计算的比较 '''
a = random.randint(0,25) # 适应度的计算与比较
b = random.randint(0,25)
child = parentkey[:]
child[a], child[b] = child[b], child[a]
childkey = {'A':'A'}
for i in range(len(child)):
childkey[child[i]] = chr(ord('A') + i)
decipher = ciphertext
for i in range(len(decipher)):
decipher = decipher[:i] + childkey[decipher[i]] + decipher[i+1:]
score = fitness.score(decipher)
if score > parentscore: # 当此时的适应度大于之前适应度,我们就进行赋值操作
parentscore = score
parentkey = child[:]
count = 0
count = count + 1
if parentscore > maxscore: # 这里对最大的适应度的值进行输出,当适应度不再
maxscore = parentscore # 进行增长的时候,我们将标志符号flag设置为0,结束
maxkey = parentkey[:]
for i in range(len(maxkey)):
key[maxkey[i]] = chr(ord('A') + i)
decipher = ciphertext
for i in range(len(decipher)):
decipher = decipher[:i] + key[decipher[i]] + decipher[i+1:]
print("目前使用密钥: " + ''.join(maxkey))
print(" " + sss)
print("\n")
print("明 文: " + decipher.lower())
print("\n")
else:
flag = 0
ss = decipher.lower()
'''
下面的操作是导入英文段的分割的语料库,对上面得到的明文段进行添加空格分割
'''
words = open("/Users/Iro/code/CodeSupport/words-by-frequency.txt").read().split() # 有特殊字符的话直接在其中添加
wordcost = dict((k, log((i+1)*log(len(words)))) for i,k in enumerate(words))
maxword = max(len(x) for x in words)
def infer_spaces(s):
def best_match(i):
candidates = enumerate(reversed(cost[max(0, i-maxword):i]))
return min((c + wordcost.get(s[i-k-1:i], 9e999), k+1) for k,c in candidates)
cost = [0]
for i in range(1,len(s)+1):
c,k = best_match(i)
cost.append(c)
out = []
i = len(s)
while i>0:
c,k = best_match(i)
assert c == cost[i]
out.append(s[i-k:i])
i -= k
return " ".join(reversed(out))
print("添加空格后明文为:" + infer_spaces(ss))
经过上面代码的分析计算,我们得到的结果如下,我的代码在后面还运用了NLP自然语言处理的方式,对生成的代码进行分词,最后自动得到符合语法的英文明文,但是还是有一些小错误,需要手动进行合理更改。
对了对了,上面代码不能直接跑,还需要导入一些支持包,我已经上传CSDN下载了,可以在这里下载
