【目标】爬取公司年报
公司列表:
bank_list = [ '中信银行', '兴业银行', '平安银行','民生银行', '华夏银行','交通银行', '中国银行', '招商银行', '浦发银行','建设银行',‘平安银行’ ]网站:
巨潮网
【实现过程】
分析网站接口:

查看接口返回数据:

选择查询年报:

点击搜索,查看接口数据:

点击一个年报,查看具体下载地址:

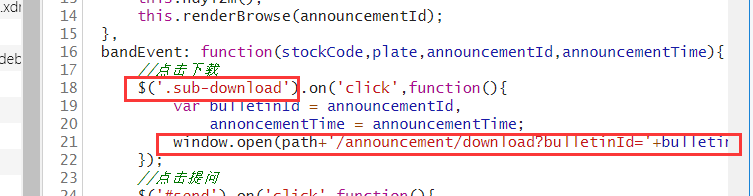
上图我们发现调用window.open(url),访问pdf地址,即可下载,其中各参数在网页内嵌中可以找到:

这样做,无非就是为了隐藏pdf下载地址,增加服务隐蔽性,也一定程度,反爬虫
其实,当你点击下载,会弹出下面这个新窗口。然后就开始下载文件,其实只要手速够快,就可以截屏获得规律:

上面我们看出path=http://www.cninfo.com.cn/new 拼接上后面参数就可以得到pdf的下载地址。
但实际上,上面的方法还是不简单,下面的方法更好。

这就是pdf的地址,直接访问就可以下载了。这也是代码里的写法。
这里的参数都在上一步的接口中返回了。
得到pdf后简单删选需要的文件即可,
上代码吧。
【代码实现】
import json
import os
from time import sleep
from urllib import parse
import requests
def get_adress(bank_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': bank_name,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 75.0.3770.100Safari / 537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
r = requests.post(url, headers=hd, data=data)
print(r.text)
r = r.content
m = str(r, encoding="utf-8")
pk = json.loads(m)
orgId = pk["keyBoardList"][0]["orgId"] #获取参数
plate = pk["keyBoardList"][0]["plate"]
code = pk["keyBoardList"][0]["code"]
print(orgId,plate,code)
return orgId, plate, code
def download_PDF(url, file_name): #下载pdf
url = url
r = requests.get(url)
f = open(bank +"/"+ file_name + ".pdf", "wb")
f.write(r.content)
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 30,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
# 'Content-Length': '216',
'User-Agent': 'User-Agent:Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533.20.25 (KHTML, like Gecko) Version/5.0.4 Safari/533.20.27',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
# 'Cookie': cookies
}
data = parse.urlencode(data)
print(data)
r = requests.post(url, headers=hd, data=data)
print(r.text)
r = str(r.content, encoding="utf-8")
r = json.loads(r)
reports_list = r['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']:
continue
if 'H' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:"+pdf_url,"存放在当前目录:/"+bank+"/"+file_name)
download_PDF(pdf_url, file_name)
sleep(2)
if __name__ == '__main__':
# bank_list = [ '中信银行', '兴业银行', '平安银行','民生银行', '华夏银行','交通银行', '中国银行', '招商银行', '浦发银行','建设银行', ]
bank_list = ["平安银行"]
for bank in bank_list:
os.mkdir(bank)
orgId, plate, code = get_adress(bank)
get_PDF(orgId, plate, code)
print("下一家~")
print("All done!")
【运行截图】


