一个zookeeper集群中,有一个处于leader身份的节点,其他的节点都是flower状态。那么一个leader是怎么产生的呢?这就是zookeeper中的选举规则,默认的选举规则称为:FastLeaderELection(还有另外的选举算法,实际上它们的核心思想都是一样的)
选举算法的中心思想
这里我们使用一张过程图和文字相结合的方式对FastLeaderELection选举算法进行描述。实际上FastLeaderELection说的中心思想无外乎以下几个关键点:
- 全天下我最牛,在我没有发现比我牛的推荐人的情况下,我就一直推举我当leader。第一次投票那必须推举我自己当leader。
- 每当我接收到其它的被推举者,我都要回馈一个信息,表明我还是不是推举我自己。如果被推举者没我大,我就一直推举我当leader,是我是我还是我!
- 我有一个票箱, 和我属于同一轮的投票情况都在这个票箱里面。一人一票 重复的或者过期的票,我都不接受。
- 一旦我不再推举我自己了(这时我发现别人推举的人比我推荐的更牛),我就把我的票箱清空,重新发起一轮投票(这时我的票箱一定有两票了,都是选的我认为最牛的人)。
- 一旦我发现收到的推举信息中投票轮要高于我的投票轮,我也要清空我的票箱。并且还是投当初我觉得最牛的那个人(除非当前的人比我最初的推荐牛,我就顺带更新我的推荐)。
- 不断的重复上面的过程,不断的告诉别人“我的投票是第几轮”、“我推举的人是谁”。直到我的票箱中“我推举的最牛的人”收到了不少于 N /2 + 1的推举投票。
- 这时我就可以决定我是flower还是leader了(如果至始至终都是我最牛,那我就是leader咯,其它情况就是follower咯)。并且不论随后收到谁的投票,都向它直接反馈“我的结果”。
一张理想的图
那么我们按照以上的原则,进行一次投票。这是一个比较理想的状态,我们不考虑其中的网络延迟,不考虑启动zookeeper节点时本身的时间差,我们假设发出包的先后顺序,就是目标节点接受这些包的先后顺序。这个理想的过程中,我们同时开启5个zookeeper节点,让他们进行选举:
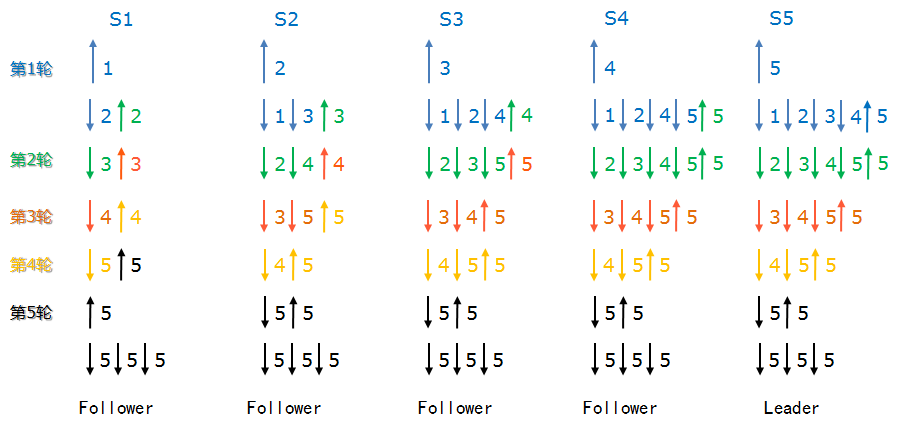
- 在第一轮中,按照“我最牛逼,我怕谁”的原则,每个节点都推荐它自己为集群的leader节点。
- 按照我们假设的理想条件,节点S1首先收到了S2发送来的推荐者“2”,节点S1发现“2”要比它之前推荐的“1”(也就是它自己)牛。根据谁牛推荐谁的原则,“S1”清空自己的票箱,重新选举“2”(注意,此时“S1”的新票箱中已经有两票选举“2”了,一票是它自己,另外一票是”S2”,并且所有节点都是Looking状态)
-
同样的事情发生在“S2”身上:”S2”收到了”S3”发过来的推荐信息,发现“3”这个被推举者比之前自己推举的“2”要牛,于是也清空自己的票箱,发起一轮新的投票,此时“S2”选举“3”。依次类推”S3”、”S4”。
- 这里要注意S5这个节点,在第一轮接受到了来源于“S1”——“S4”的推举者(一定注意,每一次接受信息,都会广播一次“我坚持推举的人”),发现“还是推荐的5最牛”,于是“我继续推举S5吧”。
- 以上这个过程在整个理想的网络环境上一直持续。到了第四轮,“S1”收到了“S2”发送来的推举者“5”,发现“5”要比当前“S1”推荐的“4”要牛。所以“S1”清空了自己的票箱,重新推举“5”(发送给其他所有节点)。
- 关键的第五轮来了,我们再重复一下,经过之前的选举,现在“S2”——“S5”都已经推举“5”为Leader了,而且都处于第四轮。这时他们收到了”S1”发来的新的“第五轮”投票,于是都和之前一样,做相同的一件事:清空自己的票箱,重新向其他所有节点广播自己的第五轮投票“5”。
- 于是,节点X,收到了大于N / 2 +1的选举“5”的投票,且都是第五轮投票。这样每个节点就都知道了自己的角色。,选举结束。所有将成为Follower状态的节点,向将要成为Leader的节点发起最后一次“工作是否正常”的询问。得到肯定的ack后,整个集群的工作状态就确认了。
实际上没有那么理想
关于上节的算法或者关于上上节的白话描述,如果您一边没有看懂,请多看几遍,如果您看晕了,请休息一下,清空脑袋,再看。选举算法的整个流程第一次是不好理解,但是一旦理解了其中的关键点,它就变得很简单。
我们在上文中介绍的选举流程是基于一个基本的考虑:理想的网络环节,理想的节点处理能力。但事实上,没有这样的环境,网络情况的多变导致了我们需要让选举算法兼容各种的情况。
下面我们假设在选举的过程中,“S1”,“S2”两个节点出现了宕机的情况(或者是网络延迟,或者是网络物理层断开,不管您怎么想吧,反正其它节点再也收到”S1”,”S2”的投票信息了)。如下图所示:
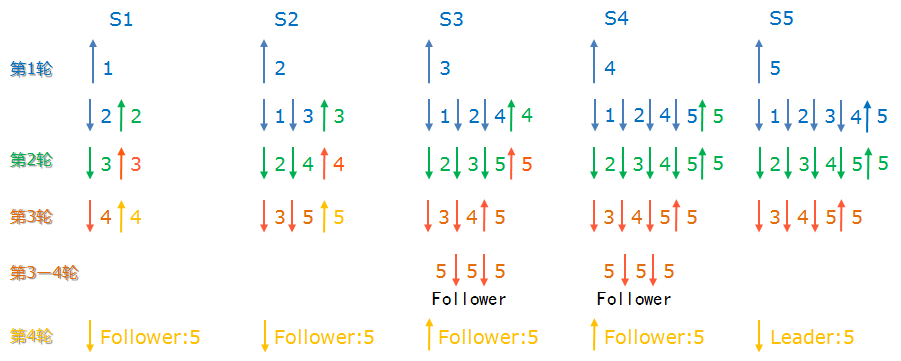
上图所示,在第三轮的选举过程后,“S1”,“S2”两个节点就断开了,他们的投票信息根本没有发送出去。
- 这样一来,“S3”收到了“S4”,“S5”发来的投票信息,这时“S3”的票箱处于第3轮,并且发现了占大多数的投票结果:大家选举“S5”为Leader节点。
- 同样的事情也发生在“S4”身上。这样“S3”,“S4”两个节点率先知道了投票结果,在最后一次询问Leader节点是否能正常工作,并得到了肯定的ACK之后,“S3”,“S4”两个节点变成了Follower状态。
- 之后,无论“S3”,“S4”两个节点收到了任何节点的投票信息,都直接向源节点反馈投票结果,不会再进行投票了。
- 这样一来,在投票完成后,“S1”,“S2”重新连入后,虽然他们发起了投票,但是不会再收到投票反馈了。直接根据“S3”或者“S4”发来的结果状态,变成Follower状态。
选举流程图
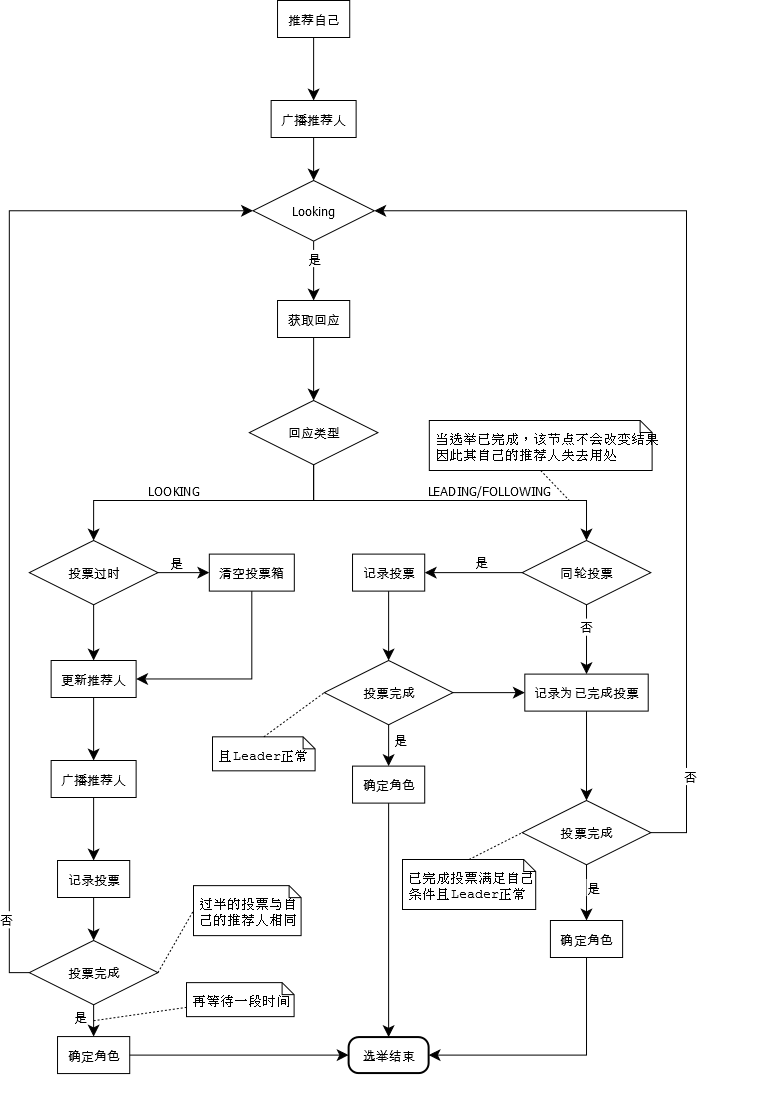
上图是网络上的一张选举过程图,步骤是怎么样的,笔者我就不再多说了,只希望这个能辅助大家更好的理解选举过程。
哦,现在您知道为什么zookeeper在少于 N / 2 + 1的节点处于工作状态的情况下会崩溃了吧。因为,无论怎么选也没有任何节点能够获得 N / 2 + 1 的票数。
