点进来的朋友先点个赞再点个关注好不好,求支持!一直往后更新。
数据结构有什么用?
当你用着java里面的容器类很爽的时候,你有没有想过,怎么ArrayList就像一个无限扩充的数组,也好像链表之类的。好用吗?好用,这就是数据结构的用处,只不过你在不知不觉中使用了。
现实世界的存储,我们使用的工具和建模。每种数据结构有自己的优点和缺点,想想如果Google的数据用的是数组的存储,我们还能方便地查询到所需要的数据吗?而算法,在这么多的数据中如何做到最快的插入,查找,删 除,也是在追求更快。
我们java是面向对象的语言,就好似自动档轿车,C语言好似手动档吉普。数据结构呢?是变速箱的工作原理。你完全可以不知道变速箱怎样工作,就把自动档的车子从 A点 开到 B点,而且未必就比懂得的人慢。写程序这件事, 和开车一样,经验可以起到很大作用,但如果你不知道底层是怎么工作的,就永远只能开车,既不会修车,也不能 造车。
当然了,数据结构内容比较多,细细的学起来也是相对费功夫的,不可能达到一蹴而就。我们将常见的数据 结构:堆栈、队列、数组、链表和红黑树 这几种给大家介绍一下,作为数据结构的入门,了解一下它们的特点即可。
常见的数据结构
数据存储的常用结构有:栈、队列、数组、链表和红黑树。我们分别来了解一下:
栈
stack,又称堆栈,它是运算受限的线性表,其限制是仅允许在标的一端进行插入和删除操作,不允许在其他任何位置进行添加、查找、删除等操作。
更准确的说,一般线性表的插入、删除运算不受限制,而栈和队列上的插入删除运算均受某种特殊限制。

简单的说:采用该结构的集合,对元素的存取有如下的特点:
先进后出(即,存进去的元素,要在后它后面的元素依次取出后,才能取出该元素)。
例如,子弹压进弹夹,先压进去的子弹在下面,后压进去的子弹在上面,当开枪时,先弹出上面的子弹,然后才能弹出下面的 子弹。 栈的入口、出口的都是栈的顶端位置。

这里两个名词需要注意:
压栈:就是存元素。即,把元素存储到栈的顶端位置,栈中已有元素依次向栈底方向移动一个位置。
弹栈:就是取元素。即,把栈的顶端位置元素取出,栈中已有元素依次向栈顶方向移动一个位置。
栈的顺序存储结构实现
引用:https://blog.csdn.net/xmxkf/article/details/82465726
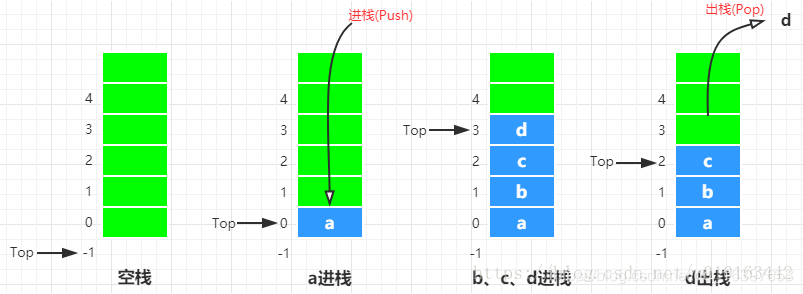
通常栈可以用顺序的方式存储,分配一块连续的存储区域存放栈中的元素,并用一个变量指向当前的栈顶。采用顺序存储的栈称为顺序栈,Java util包下的Stack就是顺序栈。
顺序栈的操作示意图如下:
顺序栈的实现如下:
package test;
import java.util.Arrays;
import java.util.EmptyStackException;
public class Test<T>{
private int top = -1; //栈顶指针,-1代表空栈
private int capacity = 10; //默认容量
private int capacityIncrement = 5; //容量增量
private T[] datas; //元素容器
public Test(int capacity){
datas = (T[])new Object[capacity];
}
public Test(){
datas = (T[])new Object[capacity];
}
/**溢出扩容 */
private void ensureCapacity() {
int oldCapacity = datas.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
/**
* Arrays的copyOf()方法传回的数组是新的数组对象,改变传回数组中的元素值,不会影响原来的数组。
* copyOf()的第二个自变量指定要建立的新数组长度,如果新数组的长度超过原数组的长度,则保留数组默认值,
* */
datas = Arrays.copyOf(datas, newCapacity);
}
/**进栈,将元素添加到栈顶*/
public synchronized void push(T item) {
//容量不足时扩容
if(top>=datas.length-1)
ensureCapacity();
datas[++top] = item;
}
/**出栈,将栈顶的元素移除并返回该元素*/
public synchronized T pop() {
if(top<0)
new EmptyStackException();
T t = datas[top];
datas[top] = null;
top--;
return t;
}
/**清空栈*/
public synchronized void clear() {
if(top<0)
return;
for(int i = top; i>=0; i--)
datas[i] = null;
top = -1;
}
/**返回栈顶元素*/
public T peek() {
if(top<0)
new EmptyStackException();
return datas[top];
}
/**获取栈中元素个数*/
public int getLength() {
return top+1;
}
/**栈是否为空栈*/
public boolean empty() {
return top<0;
}
/**获取元素到栈顶的距离 */
public int search(T data) {
int index = -1;
if(empty())
return index;
if (data == null) {
for (int i = top; i >= 0; i--)
if (datas[i]==null){
index = i;
break;
}
} else {
for (int i = top; i >= 0; i--)
if (data.equals(datas[i])) {
index = i;
break;
}
}
if (index >= 0) {
return top - index;
}
return index;
}
@Override
public String toString() {
if(empty())
return "[]";
StringBuffer buffer = new StringBuffer();
buffer.append("[");
for(int i = 0; i<=top; i++){
buffer.append(datas[i]+", ");
}
return buffer.subSequence(0, buffer.lastIndexOf(", "))+"]";
}
}
栈的链式存储结构实现
采用链式存储结构的栈称为链栈,在链栈中规定所有操作都是在链表表头进行的,链栈的优点是不存在栈满上溢的情况。上述顺序栈的实现过程中增加了扩容的功能,所以也能实现不上溢。
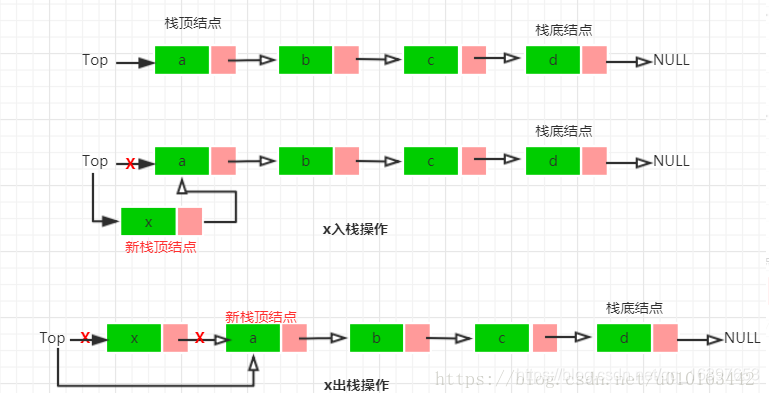
链栈的实现如下:
public class StackByLink<T>{
public LNode<T> top; //栈顶指针,指向栈顶结点
private int size = 0;
/**进栈,将元素添加到栈顶*/
public synchronized void push(T item) {
LNode temp = new LNode();
temp.next = top; //添加的结点的指针域指向当前栈顶结点
top = temp; //更新栈顶结点
size ++;
}
/**出栈,将栈顶的元素移除并返回该元素*/
public synchronized T pop() {
if(top==null)
new EmptyStackException();
LNode < T> next = top.next;
T data = top.data;
top.next = null;
top.data=null;
top = next;
size--;
return data;
}
/**清空栈*/
public synchronized void clear() {
LNode<T> next;
while(top!=null){
next = top.next;
top.data = null;
top.next = null;
top = next;
}
size = 0;
}
/**返回栈顶元素*/
public T peek() {
if(top==null)
new EmptyStackException();
return top.data;
}
/**获取栈中元素个数*/
public int getLength() {
return size;
}
/**栈是否为空栈*/
public boolean empty() {
return top==null;
}
/**获取元素到栈顶的距离 */
public int search(T data) {
int dis = -1;
if(empty())
return dis;
LNode<T> node = top;
if (data == null) {
while(node!=null){
dis ++;
if (node.data == null)
return dis;
}
} else {
while(node!=null){
dis ++;
if (node.data.equals(data))
return dis;
}
}
return dis;
}
@Override
public String toString() {
if(empty())
return "[]";
LNode node = top;
StringBuffer buffer = new StringBuffer();
buffer.append("[");
while(node != null){
buffer.append(node.data+", ");
node = node.next;
}
return buffer.subSequence(0, buffer.lastIndexOf(", "))+"]";
}
}
两种栈的效率分析
顺序栈和链式栈中,主要的操作算法push(T item)、pop()、 peek()的时间复杂度和空间复杂度都是O(1),从效率上都是一样的,因为栈只对一端进行操作。顺序栈和链式栈实现起来最大的区别就是链式栈不用考虑容量问题,而顺序栈会有上溢的情况,如果加上自动扩容,则push(T item)的时间复杂度将变为O(n)。所以链式栈相比会更加灵活一点。
队列
queue,简称队,它同堆栈一样,也是一种运算受限的线性表,其限制是仅允许在表的一端进行插入, 而在表的另一端进行删除。
队列的顺序存储结构需要使用一个数组和两个整数型变量来实现, 利用数组顺序存储队列中的所有元素,利用两个整数变量分别存储队首元素和队尾元素的下标位置,分别称为队首指针和队尾指针。

假设队列元素个数最大不超过MaxSize,当队列为初始状态有front-rear,该条件可作为队列空的条件。那么能不能用rearMaxSize-1作为队满的条件呢?显然不能,如果继续往上图的队中添加元素时出现“上溢出”,这种溢出并不是真正的溢出,因为数组中还存在空位置,所以这是一种假溢出。
为了能充分的使用数组中存储空间,把数组的前端和后端连接起来,形成一个环形的顺序表,即把存储队列元素的表从逻辑上看成一个环,称为环形队列。如下如所示:
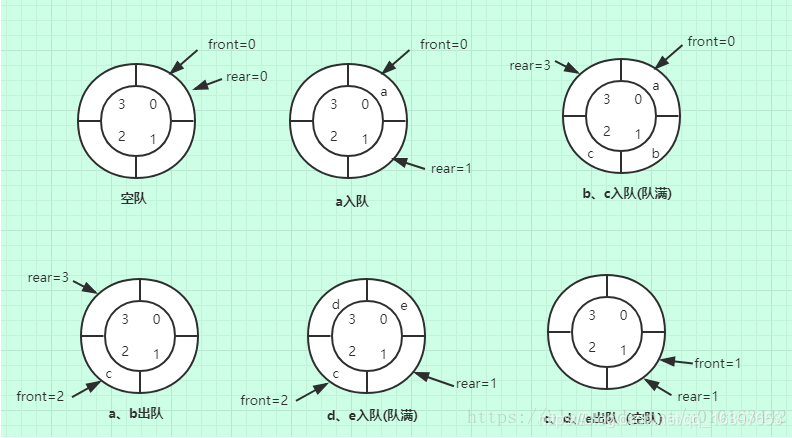
上图对应步骤解析如下:
初始化队列时,队首front和队尾rear都指向0;
a入队时,队尾rear=rear+1指向1;
bc入队后,rear=3,此时队已满。其实此时队中还有1个空位,如果这个空位继续放入一个元素,则rear=front=0,这和rear=front时队为空冲突,所以为了算法设计方便,此处空出一个位。所以判断队满的条件是(rear+1)%MaxSize == front
ab出队,队首front=2;
de入队,此时rear=1;满足(rear+1)%MaxSize == front,所以队满
cde出队,此时rear=front=1,队空
通过上述分析,我们可以得出,出队和入队操作会使得队首front队尾rear指向新的索引,由于数组为环状,可通过求余%运算来实现:
入队(队尾指针进1):rear = (rear+1)%MaxSize
出队(队首指针进1):front = (front+1)%MaxSize
当满足 rear==front时,队列为空,我们可以在出队操作后,判断此条件,如果满足则说明队列为空了,可以将rear和front重新指向0;
当需要入队操作时,首先通过(rear+1)%MaxSize == front判断是否队满,如果队满,则需要空充容量,否则会溢出。
public class QueueByArray<T>{
private int front = 0; //队首指针(出队)
private int rear = 0; //队尾指针(入队)
private int size; //元素个数
private int capacity = 10; //默认容量
private int capacityIncrement = 5; //容量增量
private T[] datas; //元素容器
public QueueByArray(int capacity){
datas = (T[])new Object[capacity];
}
public QueueByArray(){
datas = (T[])new Object[capacity];
}
public int getFront() {
return front;
}
public void setFront(int front) {
this.front = front;
}
public int getRear() {
return rear;
}
public void setRear(int rear) {
this.rear = rear;
}
/**获取队中元素个数*/
public int getSize() {
return rear - front;
// return size;
}
/**是否为空队*/
public boolean isEmpty() {
return rear==front;
}
/**入队*/
public synchronized boolean enQueue(T item) {
if(item==null)
throw new NullPointerException("item data is null");
//判断是否满队
if((rear+1) % datas.length == front){
//满队时扩容
ensureCapacity();
}
//添加data
datas[rear] = item;
//更新rear指向下一个空元素的位置
rear = (rear+1) % datas.length;
size++;
return true;
}
/**双端队列 从队首入队*/
public synchronized boolean enQueueFront(T item) {
if(item==null)
throw new NullPointerException("item data is null");
//判断是否满队
if((rear+1) % datas.length == front){
//满队时扩容
ensureCapacity();
}
//使队首指针指向上一个空位
front = (front-1+datas.length)%datas.length;
//添加data
datas[front] = item;
size++;
return true;
}
/**溢出扩容 */
private void ensureCapacity() {
int oldCapacity = datas.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
T[] oldDatas = datas;
datas = (T[])new Object[newCapacity];
int j = 0;
//将原数组中元素拷贝到新数组
for (int i = front; i!=this.rear ; i = (i+1) % datas.length) {
datas[j++] = oldDatas[i];
}
//front指向新数组0的位置
front = 0;
//rear指向新数组最后一个元素位置
rear = j;
}
/**出队*/
public synchronized T deQueue() {
if(isEmpty())
return null;
T t = datas[front];
datas[front] = null;
//front指向新的队首元素
front = (front+1) % datas.length;
size --;
return t;
}
/**双端队列 从队尾出队*/
public synchronized T deQueueRear() {
if(isEmpty())
return null;
//队尾指针指向上一个元素位置
rear = (rear-1+datas.length)%datas.length;
T t = datas[rear];
datas[rear] = null;
size --;
return t;
}
/**清空队列*/
public synchronized void clear() {
while(!isEmpty()){
deQueue();
}
front = rear = 0;
}
/**返回队首元素*/
public T peek() {
if(isEmpty())
return null;
return datas[front];
}
public T getElement(int index) {
if(isEmpty() || index>=datas.length)
return null;
T t = datas[index];
return t;
}
@Override
public String toString() {
if(isEmpty())
return "[]";
StringBuffer buffer = new StringBuffer();
buffer.append("[");
int mFront = front;
while(mFront!=rear){
buffer.append(datas[mFront]+", ");
mFront = (mFront+1) % datas.length;
}
return buffer.subSequence(0, buffer.lastIndexOf(", "))+"]";
}
}
队列的链式存储结构实现
链式存储结构有单链表和双链表,对于链队的实现,使用单链表就足以满足需求(双链表由于多了前驱指针,存储密度不如单链表,造成空间浪费)。下面我们使用单链表实现链队,操作示意图如下:

从上图中,我们可以知道如下几点:
使用front指向队首结点,rear指向队尾结点;
当队为空时,front = rear = null,并约定以此作为队列为空的判断条件;
入队时,使当前队尾结点的后继指针指向新结点rear.next = newNode,然后使队尾指针rear指向新结点
出队时,删除队首结点,使front = front.next
链队不会出现溢出的情况,这比使用数组实现的顺序队列更加灵活
链队的分析就到这里,接下来我们实现链队的基本操作算法:
public class QueueByLink<T>{
private LNode<T> front; //队首指针
private LNode<T> rear; //队尾指针
private int size; //元素个数
/**获取队中元素个数*/
public int getSize() {
return size;
}
/**队列是否为空*/
public boolean isEmpty() {
return front==null && rear==null;
}
/**入队*/
public synchronized boolean enQueue(T item) {
if(item==null)
throw new NullPointerException("item data is null");
LNode<T> newNode = new LNode();
newNode.data = item;
if (front == null) {
//向空队中插入,需要将front指针指向第一个结点
front = newNode;
} else {
//非空队列,队尾结点的后继指针指向新结点
rear.next = newNode;
}
rear = newNode; //队尾指针指向新结点
size ++;
return true;
}
/**出队*/
public synchronized T deQueue() {
if(isEmpty())
return null;
T t = front.data;
front = front.next;
if (front == null) //如果出队后队列为空,重置rear
rear = null;
size--;
return t;
}
/**返回队首元素*/
public T peek() {
return isEmpty()? null:front.data;
}
/**清空队列*/
public synchronized void clear() {
while(!isEmpty()){
deQueue();
}
front = rear = null;
size = 0;
}
@Override
public String toString() {
if(isEmpty())
return "[]";
StringBuffer buffer = new StringBuffer();
buffer.append("[");
LNode mFront = front;
while(mFront!=null){
buffer.append(mFront.data+", ");
mFront = mFront.next;
}
return buffer.subSequence(0, buffer.lastIndexOf(", "))+"]";
}
}
简单的说,采用该结构的集合,对元素的存取有如下的特点:
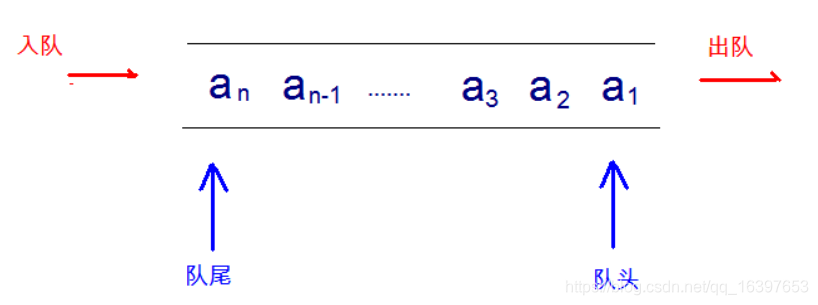
先进先出(即,存进去的元素,要在后,它前面的元素依次取出后,才能取出该元素)。例如,小火车过山 洞,车头先进去,车尾后进去;车头先出来,车尾后出来。
队列的入口、出口各占一侧。例如,下图中的左侧为入口,右侧为出口。
数组
Array,是有序的元素序列,数组是在内存中开辟一段连续的空间,并在此空间存放元素。就像是一排出 租屋,有100个房间,从001到100每个房间都有固定编号,通过编号就可以快速找到租房子的人。
简单的说,采用该结构的集合,对元素的存取有如下的特点: 查找元素快:通过索引,可以快速访问指定位置的元素

增删元素慢
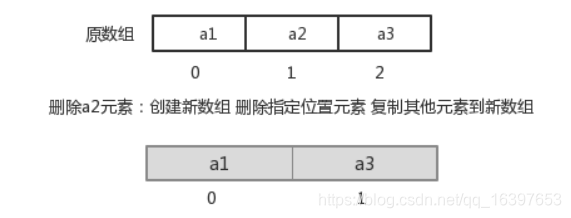
指定索引位置增加元素:需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根据索引,复制到新数组对应索引的位置。如下图

指定索引位置删除元素:需要创建一个新数组,把原数组元素根据索引,复制到新数组对应索引的位 置,原数组中指定索引位置元素不复制到新数组中。如下图
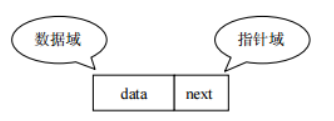
链表
linked list,由一系列结点node(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每 个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。我们常说的 链表结构有单向链表与双向链表,那么这里给大家介绍的是单向链表。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
多个结点之间,通过地址进行连接。例如,多个人手拉手,每个人使用自己的右手拉住下个人的左手,依次 类推,这样多个人就连在一起了。

查找元素慢:想查找某个元素,需要通过连接的节点,依次向后查找指定元素
增删元素快:
增加元素:只需要修改连接下个元素的地址即可。
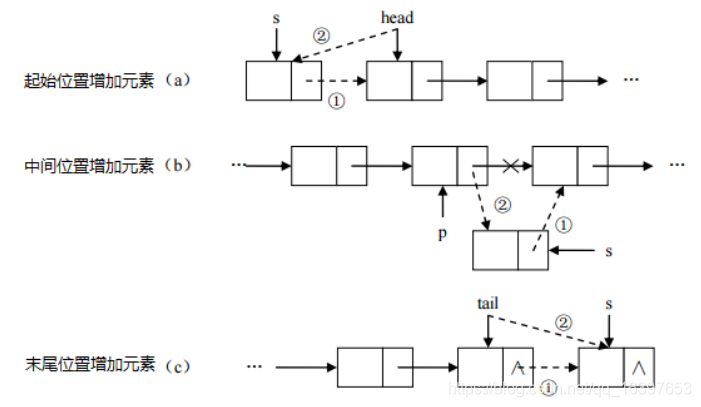
删除元素:只需要修改连接下个元素的地址即可。
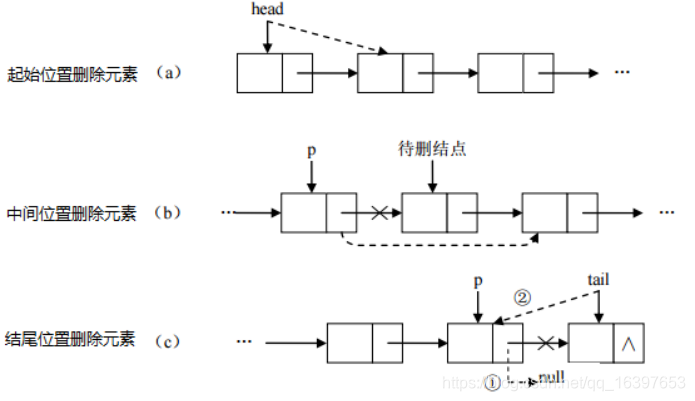
链表的实现原理
1 创建一个节点类,其中节点类包含两个部分,第一个是数据域(你到时候要往节点里面储存的信息),第二个是引用域(相当于指针,单向链表有一个指针,指向下一个节点;双向链表有两个指针,分别指向下一个和上一个节点)
2 创建一个链表类,其中链表类包含三个属性:头结点、尾节点和大小,方法包含添加、删除、插入等等方法。
单向链表的节点类:
public class Node {
public Object data;
public Node next;
public Node(Object e){
this.data = e;
}
}
双向链表的节点类:
public class Node {
public Object e;
public Node next;
public Node pre;
public Node(){
}
public Node(Object e){
this.e = e;
next = null;
pre = null;
}
}
如何自己写出一个链表?
代码如下(以双向链表为例,有详细的注释,单向链表同理):
首先创建了一个节点类
package MutuLink;
public class Node {
public Object e;
public Node next;
public Node pre;
public Node(){
}
public Node(Object e){
this.e = e;
next = null;
pre = null;
}
}
然后创建了一个链表类
package MutuLink;
public class MyList {
private Node head;
private Node tail;
private int size = 0;
public MyList() {
head = new Node();
tail = new Node();
head.next =null;
tail.pre = null;
}
public boolean empty() {
if (head.next == null)
return true;
return false;
}
//找到所找下标节点的前一个节点
public Node findpre(int index){
Node rnode = head;
int dex = -1;
while(rnode.next != null){
//找到了插入节点的上一个节点
if( dex== index - 1){
return rnode;
}
rnode = rnode.next;
dex++;
}
return null;
}
public Node findthis(int index){
Node rnode = head;
//把rnode想象为指针,dex为指向的下标,这个地方很容易错,因为当指向最后一个节点时没有判断IF就跳出循环了
int dex = -1;
while(rnode.next != null){
if(dex == index)
return rnode;
rnode = rnode.next;
dex++;
}
if(dex == size - 1){
return rnode;
}
// Node test = new Node(new Students("haha",1,2));
return null;
}
// 往链表末尾加入节点
public void add(Object e) {
Node node = new Node(e);
Node rnode = head;
//如果是空链表的话插入一个节点,这个节点的pre不能指向上一个节点,必须指空
if (this.empty()) {
rnode.next = node;
rnode.next.pre = null;
tail.pre = node;
size++;
} else {
while (rnode.next != null)
rnode = rnode.next;
rnode.next = node;
node.pre = rnode;
tail.pre = node;
size++;
}
}
//往链表的某一个标插入一个节点
public boolean add(int index,Object e){
if(index <0||index>=size)
return false;
Node node = new Node(e);
Node prenode = this.findpre(index);
node.next = prenode.next;
prenode.next.pre = node;
prenode.next = node;
node.pre = prenode;
size++;
return true;
}
public boolean add(int index,MyList myl){
if(index <0 || index >= size)
return false;
Node prenode = this.findpre(index);
// myl.tail.pre.next = prenode.next;
// prenode.pre = myl.tail.pre;
// tail.pre = null;
// prenode.next = myl.head.next;
// myl.head.next.pre = prenode;
// head.next = null;
myl.tail.pre.next = prenode.next;
prenode.next.pre = myl.tail.pre.pre;
myl.head.next.pre = prenode.pre;
prenode.next = myl.head.next;
myl.head = null;
myl.tail = null;
size+=myl.size;
return true;
}
public Object remove(int index){
Object ob= this.get(index);
if(index <0 || index >= size)
return null;
//特殊情况,当移除节点是最后一个节点的时候
//较为复杂通过画图来写代码
if(index == size - 1){
Node prenode = this.findpre(index);
this.tail.pre = this.tail.pre.pre;
this.tail.pre.next.pre = null;
this.tail.pre.next =null;
size--;
return ob;
}
//比较复杂,通过画图解决
else{
Node prenode = this.findpre(index);
prenode.next = prenode.next.next;
prenode.next.pre.next = null;
prenode.next.pre = prenode.next.pre.pre;
size--;
return ob;
}
}
public Object get(int index){
Node thisnode = this.findthis(index);
return thisnode.e;
}
public int size(){
return size;
}
}
最后测试
package MutuLink;
import java.util.Random;
public class manage {
public static void main(String[] args) {
String name = "";
int credit;
int age;
int size;
MyList myl = new MyList();
Random random = new Random();
size = random.nextInt(5) + 1;
for (int i = 0; i < size; i++) {
credit = random.nextInt(5);
age = random.nextInt(5) + 18;
for (int j = 0; j < 4; j++) {
name += (char) (random.nextInt(26) + 97);
}
Students stu = new Students(name, credit, age);
myl.add(stu);
name = "";
}
System.out.println("Size of myl1 is "+ myl.size());
for(int i = 0; i < myl.size() ;i++){
Students stu2 = (Students) myl.get(i);
stu2.show();
}
// //测试能否在链表末尾加入节点(成功)
// for(int i = 0; i < myl.size() ;i++){
// Students stu2 = (Students) myl.get(i);
// stu2.show();
// }
// //测试能否通过下标加入一个节点(成功)
// Students stu3 = new Students("cyt",5,18);
// myl.add(1, stu3);
// System.out.println("Size is "+ myl.size());
// for(int i = 0; i < myl.size() ;i++){
// Students stu2 = (Students) myl.get(i);
// stu2.show();
// }
MyList myl2 = new MyList();
size = random.nextInt(5) + 1;
for (int i = 0; i < size; i++) {
credit = random.nextInt(5);
age = random.nextInt(5) + 18;
for (int j = 0; j < 4; j++) {
name += (char) (random.nextInt(26) + 97);
}
Students stu2 = new Students(name, credit, age);
myl2.add(stu2);
name = "";
}
System.out.println("Size is of myl2 "+ myl2.size());
for(int i = 0; i < myl2.size() ;i++){
Students stu2 = (Students) myl2.get(i);
stu2.show();
}
myl.add(1, myl2);
System.out.println("Size is of myl1 "+ myl.size());
for(int i = 0; i < myl.size() ;i++){
Students stu2 = (Students) myl.get(i);
stu2.show();
}
}
}
输出结果:

红黑树
二叉树:binary tree ,是每个结点不超过2的有序树(tree)。
简单的理解,就是一种类似于我们生活中树的结构,只不过每个结点上都最多只能有两个子结点。
二叉树是每个节点最多有两个子树的树结构。顶上的叫根结点,两边被称作“左子树”和“右子树”。 如图:
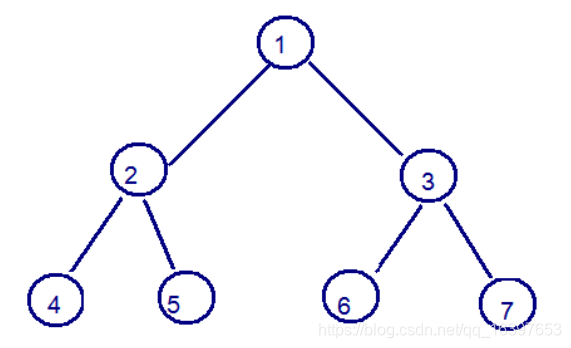
我们要说的是二叉树的一种比较有意思的叫做红黑树,红黑树本身就是一颗二叉查找树,将节点插入后,该树仍然 是一颗二叉查找树。也就意味着,树的键值仍然是有序的。
红黑树的约束:
- 节点可以是红色的或者黑色的
- 根节点是黑色的
- 叶子节点(特指空节点)是黑色的
- 每个红色节点的子节点都是黑色的
- 任何一个节点到其每一个叶子节点的所有路径上黑色节点数相同
红黑树的特点: 速度特别快,趋近平衡树,查找叶子元素最少和最多次数不多于二倍
