生成图片
from tensorflow.examples.tutorials.mnist import input_data
import scipy.misc
import numpy as np
import os
import tensorflow as tf
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
#print(mnist.train.images.shape)
save_dir = 'MNIST_data/raw/'
if os.path.exists(save_dir) is False:
os.makedirs(save_dir)
for i in range(mnist.train.images.shape[0]):
image_array = np.array(mnist.train.images[i])
image_array = image_array.reshape(28,28)
file_name = save_dir + 'mnist_train_%d.jpg' % i
#print(image_array)
scipy.misc.toimage(image_array, cmin=0.0, cmax=1.0).save(file_name)
图片所示
label标签
from tensorflow.examples.tutorials.mnist import input_data
import scipy.misc
import numpy as np
import os
import tensorflow as tf
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
for i in range(20):
one_hot_label = mnist.train.labels[i, :]
label = np.argmax(one_hot_label)#输出最大值的索引
print('mnist_train_%d.jpg label: %d' % (i, label))
简单的流程
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
#占位符
x = tf.placeholder(tf.float32, [None, 784])
#变量
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
#占位符与变量区别在于,系统不需要计算占位符的值,而是直接把占位符的值传递给会话,与变量不同的是,占位符的值不会被保存,每次可以给占位符传递不同的值
#y为预测结果
y = tf.nn.softmax(tf.matmul(x, W) + b)
#y_为实际结果
y_ = tf.placeholder(tf.float32, [None, 10])
#cross_entropy为交叉熵,用于衡量相似性,损失函数
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y)))
#优化损失,使用梯度下降法,0.01为learning rate
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
#创建一个Session
sess = tf.InteractiveSession()
#运行之前初始化所有变量
tf.global_variables_initializer().run()
#训练1000次
for _ in range(1000):
#在数据集中每次取出100个数据
batch_xs, batch_ys = mnist.train.next_batch(100)
开始训练
sess.run(train_step, feed_dict={x:batch_xs, y_:batch_ys})
#将预测结果与实际结果进行比对
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_, 1))
#计算预测的准确率,cast函数是将其转为float类型
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float16))
print(sess.run(accuracy, feed_dict={x:mnist.test.images, y_:mnist.test.labels}))
0.9136的准确率
Softmax回归
Softmax回归是一个线性的多类分类模型,实际上它是从Logistic回归模型转化而来。区别在于Logistic回归模型为两类分类模型,而Softmax模型为多类分类模型。
那什么是Softmax函数呢?
Softmax函数的主要功能是将各个类别的“打分”转化为合理的概率值。例如,一个样本可能属于三个类别,第一个类别打分为a,第二个类别打分为b,第三个类别打分为c。打分越高说明属于这个类别的概率越大,但是打分本身不代表概率,因为打分的值可能是负数,也可能很大,但概率要求在0-1之间,而且所有概率相加应该为1,,所以对(a,b,c)使用softmax函数后,就将其转为合理的概率值,
两层卷积网络的分类
对于0.91的准确率并不是很满意,故我们用稍微复杂一些的卷积神经网络进行预测
先介绍几个卷积神经网络中的函数
tf.truncated_normal(shape, mean, stddev)
shape表示生成张量的维度,mean是均值,stddev是标准差。 这个函数产生正太分布,均值和标准差自己设定。这是一个截断的产生正太分布的函数,就是说产生正太分布的值如果与均值的差值大于两倍的标准差,那就重新生成。和一般的正太分布的产生随机数据比起来,这个函数产生的随机数与均值的差距不会超过两倍的标准差,但是一般的别的函数是可能的。 简而言之,为一个生成需要形状的随机函数,但其生成的随即数据与均值的差距不能超过两倍的标准差
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)
除去name参数用以指定该操作的name,与方法有关的一共五个参数:
第一个参数input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一
第二个参数filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维
第三个参数strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4
第四个参数padding:string类型的量,只能是"SAME","VALID"其中之一,这个值决定了不同的卷积方式。值为“SAME”时,表示卷积核可以停留在图像边缘
第五个参数:use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true
结果返回一个Tensor,这个输出,就是我们常说的feature map,shape仍然是[batch, height, width, channels]这种形式。
最终输出的行列数计算方法
- SAME:
out_height = ceil(float(in_height) / float(strides[1]))
out_width = ceil(float(in_width) / float(strides[2]))
- VALID:
out_height = ceil(float(in_height - filter_height + 1) / float(strides1))
out_width = ceil(float(in_width - filter_width + 1) / float(strides[2]))
便于理解,贴个网址
tf.nn.relu()
relu()函数为激活函数,那么为什么要引入非线性的激活函数呢? 如果不用激活函数,在这种情况下每一层输出都是上层输入的线性函数。容易验证,无论神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。因此引入非线性函数作为激活函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入。 该函数是将大于零的数保持不变,小于零的数置为0 举例:
>>> a = tf.constant([[-2,-4],[4,-2]])
>>> with tf.Session() as sess:
... print(sess.run(tf.nn.relu(a)))
...
[[0 0]
[4 0]]
tf.nn.max_pool(value, ksize, strides, padding, name=None)
参数为4个,跟卷积函数很相似, 其为最大值池化操作。
第一个参数value:需要池化的输入,一般池化层在卷积层后面,所以输入通常是feature map,依然是[batch, height, width, channels]这样的shape
第二个参数ksize,池化窗口的大小,取一个四维向量,一般为[1,height,width,1],因为不想在batch和channels上做池化故设为1。
第三个参数strides:和卷积类似,窗口在每一个维度上滑动的步长。
第四个参数padding:和卷积类似,可以去"VALID"或者"SAME"
返回一个Tensor,shape不变,四维向量
其思想非常简单,对于每个2*2窗口选出最大数作为输出矩阵的相应元素的值。 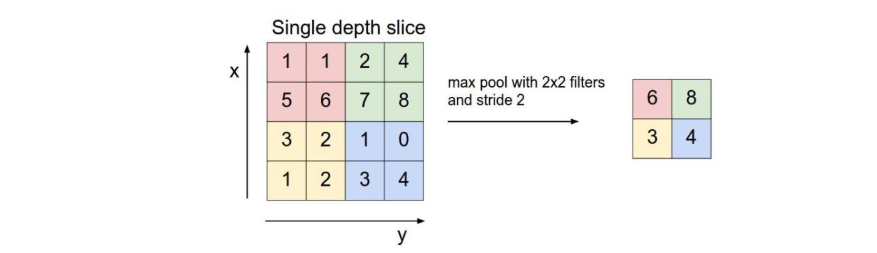
tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None,name=None)
为了防止和减轻过拟合,一般用在全连接层。
Dropout就是在不同的训练过程中随机扔掉一部分神经元。也就是让某个神经元的激活值以一定的概率p,让其停止工作,这次训练过程中不更新权值,也不参加神经网络的计算。但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了 参数解析:
- x:输入的feature map
- keep_prob:指每个神经元被选中的概率(初始化时其为一个占位符,当运行时,设置其具体的值)
tf.cast(x,dtype,name=None)
主要作用为转换数据类型
- x:输入
- dtype:转换之后的数据类型
tf.reduce_mean(input_tensor,axis=None,keep_dims=False,name=None,reduction_indices=None)
tf.reduce_mean 函数用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值,主要用作降维或者计算tensor(图像)的平均值。 参数解析:
- 第一个参数为输入的tensor
- 第二个参数为指定的轴, 如果不指定则计算所有元素的均值(axis=0为纵轴,axis=1为横轴)
- 第三个参数keep_dims,如果设置为True,则不降维,输出结果保持输入形状,若为False,则降维。
>>> import tensorflow as tf
>>>
... x = [[1,2,3],
... [1,2,3]]
>>>
>>> with tf.Session() as sess:
... sess.run(tf.reduce_mean(x))
...
2
>>> with tf.Session() as sess:
... sess.run(tf.reduce_mean(x, axis=0))
...
array([1, 2, 3])
>>> with tf.Session() as sess:
... sess.run(tf.reduce_mean(x, axis=1))
...
array([2, 2])
卷积神经网络的层级结构
- 数据输入层
- 卷积计算层
- ReLu激励层
- 池化层
- 全连接层
输入层
该层做的处理主要对原始图像数据进行预处理,其中包括:
- 去均值(把输入数据各个维度都中心化为0,如下图所示,其目的就是把样本的中心拉回到坐标系的原点上。)
- 归一化(幅度归一化到同样的范围,如下所示,即减少各维度数据取值范围的差异而带来的干扰,比如,我们有两个维度的特征A和B,A的范围是0-10,B的范围是0-1000,如果直接使用两个特征是有问题的,好的做法就是归一化,即A和B的数据都变为0-1的范围)
- PCA/白化:使用PCA降维,白化是对各个特征轴上的幅度归一化
卷积计算层
- 局部关联,每个神经元看作一个滤波器
- 窗口滑动,filter对局部数据进行计算
激励层
把卷积层输出结果做非线性映射 一般采用ReLU,它的特点是收敛快,求梯度简单,但比较脆弱
池化层
池化层夹在连续的卷积层中间,用于压缩数据和参数的量,减小过拟合。简而言之,如果输入是图像的话,那么池化层的作用就是压缩图像 池化层具体作用:
- 特征不变性,也就是我们在图像处理中,经常提到的特征的尺度不变性,池化操作就是resize,图像压缩时去掉的信息只是一些无关紧要的信息,而留下的信息则是具有尺度不变性的特征,是最能表达图像的特征。
- 特征降维,一幅图像含有的信息量是很大的,特征也很多,但是有些信息对于我们做图像任务时没有太多用途或者有重复,我们可以把这类的冗余信息去除,把最重要的特征抽取出来,这也是池化操作的一大作用。
- 在一定程度上防止过拟合,更方便优化。
全连接层
两层之间的所有神经元都有权重连接,通常全连接层在卷积神经网络的尾部。
理解神经网络中的通道
一般的RGB图片的channel为3(红绿蓝), 灰度图为1
一般channels的含义为:每个卷积层中卷积核的数量
手写数字两层卷积神经网络实现
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
def weight_variable(shape):
inite = tf.truncated_normal(shape=shape, stddev=0.1)
return tf.Variable(inite)
def bias_variable(shape):
inite = tf.constant(0.1, shape=shape)
return tf.Variable(inite)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1,1,1,1], padding="SAME")
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
x_image = tf.reshape(x, [-1, 28, 28, 1])
W_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
W_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob=keep_prob)
W_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)#1e-4即为0.0001
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
sess =tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
for i in range(20000):
batch_x, batch_y = mnist.train.next_batch(50)
sess.run(train_step, feed_dict={x:batch_x, y_:batch_y, keep_prob:0.8})
if i % 100 == 0:
train_accuracy = sess.run(accuracy, feed_dict={x:batch_x, y_:batch_y, keep_prob:1.0})
print("step %d, training accuracy %g" % (i, train_accuracy))
print("test accuracy %g" % (sess.run(accuracy, feed_dict={x:mnist.test.images, y_:mnist.test.labels, keep_prob:1.0})))最后输出为:
test accuracy 0.9912
达到百分之99.12的准确率
