C语言是博主最先学的语言,但接触机器学习以来,主要编程语言变成了python,为了防止对C语言的淡忘,利用谭浩强C语言系列进行查漏补缺,进行易忘概念总结。
一、基础知识
1、一个C程序的执行是从本程序的main函数开始,到main函数结束;
2、C语言本身没有输入输出语句(只有输入输出函数);
3、C语言规定,在源程序中main函数的位置可以任意;
4、一个C语言程序是由:
5、C语言的源程序必须通过编译和链接后,才能被计算机执行;
6、在C语言源程序中,一个变量代表内存中的一个存储单元;
7、在Turbo C环境中用RUN命令运行一个C程序时,所运行程序的后缀是.exe;
8、C语言源程序文件的后缀是.c,经过编译后,生成文件的后缀是.obj,经过连接后,生成文件的后缀是.exe;
9、C语言源程序的基本单位是函数;
10、一个C语言源程序是由若干函数组成,其中至少应含有一个主函数(main);
11、C和C++的不同:C++是以C语言为基础的面向对象程序设计语言,对于C89而言,因为C++标准包容了C89的所有内容,所以实现了其全部特性,但对于C99而言,其部分特性未包含到C++中。C语言源文件的扩展名是.c,C++的是.cpp;
12、原码、反码和补码:原码是在真值的基础上,最高位用1表示正号,用0表示负号;正数的反码、补码和原码相同;负数的反码是原码除负号位外取反,补码是在反码基础上末位加1;
13、C编译器对数据的三种内存分配方式(书上说对数据区的内存分配需要认真研究):
(1)在静态数据区中分配:静态数据区中的变量在C程序编译的时候就分配完成并初始化,这些变量称为静态型变量,其生命周期贯穿程序的整个运行周期。外部变量、static变量都在静态数据区中分配存储单元(这里内容有个小小的bug,如果我将程序进行编译后迟迟不去运行,那是不是被分配的内存空间就一直被这个程序的静态型变量占用?我认为这里应该是做了个假设:“编译完就立刻装入内存运行”,否则静态型变量应当也是程序要被运行时才分配内存,只不过是编译时就先确定“其一定会被分配内存(同时就确定了所需内存大小)”且将程序装入内存时就为之分配内存,分配完成才进行程序执行的下一步);
(2)在动态数据区的堆栈上分配:C程序在函数内或者语句块内声明的变量是内部变量,它就在堆栈上分配存储空间。这部分存储空间中的变量随时可能消失,调用函数时,这部分变量就在堆栈上分配存储空间,当函数调用结束时,这部分存储空间会被自动释放,这些变量就不存在了;
(3)在动态数据区的堆上分配:需要程序员自己负责变量的分配和释放。需要使用C语言的指针来管理、操作这部分内存。
二、C语言基本要素
1、system("PAUSE")的功能是产生一个DOS系统功能调用,等待键盘输入一个字符。在输入前屏幕暂停在当前位置,方便观察结果。此函数不是必须的,但若用之,需加#include<stdlib.h>;
2、return 0的功能是退出main函数,返回操作系统;
3、用户自定义函数可以在main函数之后定义,但必须在main函数之前声明;
4、printf()和scanf()在stdio.h中,都是标准库函数;
5、开发过程:编辑、编译(利用编译器,得到计算机可识别处理的二进制代码)、连接(将多个目标代码或者库函数代码连接起来)、装载运行(将连接后的程序装载到计算机内存,运行并得到结果);
8、每个C程序都必须且只能有一个main函数;
9、C99标准中,main函数必须返回int型,即void main(void)是错误的,另外,要用int main(void)明确声明main函数没有参数;C89可以返回void型,默认返回int型;
10、包含在函数名后面一对大括号中的部分就是函数体,C89要求变量的定义语句应该放在函数体中语句块的开头,C99则无这个要求(一般为了满足C89的要求,会将变量定义语句放在语句块开头);
变量、常量和数据类型
11、用const定义的常量称为常变量,是不可改变的,可以通过初始化(定义时赋值)或者外部硬件因素修改其值,但不能通过赋值语句;
12、转义字符:
| 转义字符 | 字符值 |
|---|---|
| \’ | ’ |
| \" | " |
| \? | ? |
| \\ | \ |
| \a | 警告(产生声音或视觉信号) |
| \b | 退格(backspace),当前位置后退一个字符 |
| \f | 换页(form feed),当前位置移到下一页开头 |
| \n | 换行 |
| \r | 回车(carriage return),当前位置移到本行开头 |
| \t | 水平制表符,当前位置移到下一个tab位置 |
| \v | 垂直制表符,当前位置移到下一个垂直制表对齐点 |
| \o、\oo、\ooo,o代表一位八进制数 | 与该八进制码对应的ascii字符 |
| \xh[h…],h代表一位十六进制数 | 与该十六进制码对应的ascii字符 |
13、用""将若干字符括起来,但不能用',这个只能包含一个字符;
14、用#define定义的常量为符号常量,习惯上用大写表示,预编译后,符号常量就不存在了,比如#define Pi 3.1415926,预编译后,Pi被全部置换成3.1415926;
15、常量在程序运行期间,值不能改变,变量的值可以改变。变量必须先定义,后使用;
16、常变量是有名字的不变量,常量是没有名字的不变量(有名字便于在程序中被引用)。常变量具有变量的基本属性:有类型、占存储单元,只是不允许改变;
17、合法标识符:只能由字母、数字、下划线组成,且第一个字符必须为字母或者下划线(而不能是数字);
18、整型数据:C标准要求sizeof(short)≤sizeof(int)≤sizeof(long)≤sizeof(long long),通常是把long定为32位,把short定为16位,而int可以是16位或者32位。书上没提long long通常多少位,但表格中long long有8字节,即64位;
19、只有整型(包括字符型)可以加signed和unsigned修饰符,实行数据不能加。对无符号整型数据用“%u”格式输出,这个代表输出无符号十进制数的格式;
20、给无符号整型变量赋值负数的案例:
unsigned short x = -1;
printf("%d\n", x);
输出结果是65535,因为系统会将-1转换成补码形式,由于是short型(16位),即系统用十六个1表示-1的补码。但由于x是unsigned型,所以输出时会认为这是非负数,非负数的原码和补码一致,故输出65535;
21、由于字符是按照其代码(整数)形式存储的,因此C99单独把字符型数据作为整型数据的一种。几种重要字符的ascii代码:
| 字符 | ASCII代码 |
|---|---|
| A | 65 |
| a | 97 |
| 1 | 49 |
| ’ '(空格字符) | 32 |
| % | 37 |
| \n | 10 |
22、字符’1’和整数1的区别:前者只是形状为’1’的符号,在内存中占一个字节以ascii码(49)存储,后者占两个字节,以二进制补码方式存储。⚠️注意’1’+‘1’不等于’2’;
23、用char定义的变量是字符变量,用%d打印出来是其ascii码的值,用%c打印出来是这个字符本身;
24、字符型数据可以是signed或者unsigned的,不加这个符号时,默认是signed char还是unsigned char需要由编译器决定。将负数赋值给有符号字符型数据是合法的,但它不代表一个字符,而是作为一字节整型变量存储负整数;
25、总结一下浮点数取值范围,浮点数值为:
对于float:1bit(符号位)+8bits(指数位)+23bits(尾数位);
对于double:1bit(符号位)+11bits(指数位)+52bits(尾数位)。
(补充概念:规范化的指数形式指的是小数点前为0,小数点后第一位不为0)
尾数最大近似为1,浮点数的范围主要就和指数部分有关,float的指数部分范围是-127~128,底数为2。128代表浮点数范围两头最大和最小是多少,-127代表浮点数范围中最接近0的点应该是多少,所以float的两头范围大致就是
~
,即
~
,同理计算出最靠近0的部分就是
,double型的计算过程略,谭浩强教材中有一张表:
| 类型 | 字节数 | 有效数字 | 数值范围(绝对值) |
|---|---|---|---|
| float | 4 | 6 | 0以及 ~ |
| double | 8 | 15 | 0以及 ~ |
| long double(Visual C++ 6.0编译器) | 8 | 15 | 0以及 ~ |
| long double(Turbo C编译器) | 16 | 19 | 0以及 ~ |
对于float的有效数字,由于float的尾数有23位,即
,共七位,意味着最多能有7位有效数字,但绝对能保证的为6位,所以有效数字定为6位,这个也代表精度。其他类型的有效数字推算略,推算不是重点,将上图各个类型的大致范围记住,方便编程就足够了;
26、C程序中的实型常量都是双精度浮点型常量;
算数运算和数据存储
27、整除运算符/:多数C编译系统采取“向零取整”,5/3 = 1,-5/3 = -1;
28、求余运算符%:参加运算的运算对象为整数,结果也是整数。除了%以外的其他运算符的操作数都可以是任何算数类型;
29、运算符的优先级和结合性:优先级相同的情况下,算术运算符的结合方向都是先左后右(左结合性);
30、不同类型数据间混合运算:
int、float、double两两之间进行运算,先将非double型(包括float)的转化为double型,再进行运算,运算结果为double型;
char型可以直接和int型进行运算(不需要类型转换);
char型和float或者double型进行运算,char型和float型会先被转化为double型;
31、强制类型转换:(类型名)(表达式),比如b = (double)a就是将a的值强制转化为double型赋给b,但a的类型和值都没有发生变化;
⚠️由于%要求两侧数字都是整型的,令f为浮点型数据,则f%3不合法,可写成(int)f%3;
32、赋值过程的类型转换
将浮点型(包括单精度和双精度)赋给整型时,先舍弃浮点型数据的小数部分然后再赋予整型变量:
int i; i = 3.56;运行结果是i为3;
将整型数据赋给浮点型数据时,数值不变,以浮点数形式存储到变量中;
将double型赋给float时,先将双精度转换为单精度,只取6~7位有效数字,存储到float变量的4个字节中;
⚠️双精度范围比单精度大,不要将单精度无法存储的大数赋值给单精度变量;
字符型数据给整型数据赋值,将前者的ASCII赋给后者;
多字节的整型数据赋给少字节的整型数据,比如占4字节的int赋给2字节的short,或者1字节的char,将其低字节原封不动地送到被赋值的变量,此过程叫“截断”;
33、⚠️关于补码的注意事项:
以下两个横线之间的内容参考了其他博客,觉得其对+0和-0和-32768的补码来源很有参考价值:
正0和负0的原码:0000000000000000和1000000000000000,补码表现中,两者都是0000000000000000,也就是正0和负0在补码系统中的编码是一样的,
而任何一个原码都不可能在转成补码时变成1000000000000000(这个是-0的原码),
所以,人为规定1000000000000000这个-0的原码来表示-32768的补码。所以,补码系统中,范围是-32768~32767(原码系统中则是-32767~32767)。
此处参考原文:https://blog.csdn.net/chen_tongsheng/article/details/79011390
-127的补码是10000000的道理和上面一样,只要是第一位是1,剩下全0的补码,都可视为用-0的原码充当的补码。
再来一张图辅助理解原码、补码和反码,留意其中对-8补码来源的解释(-0和+0的补码相同,所以用-0的原码来表示-8的补码):
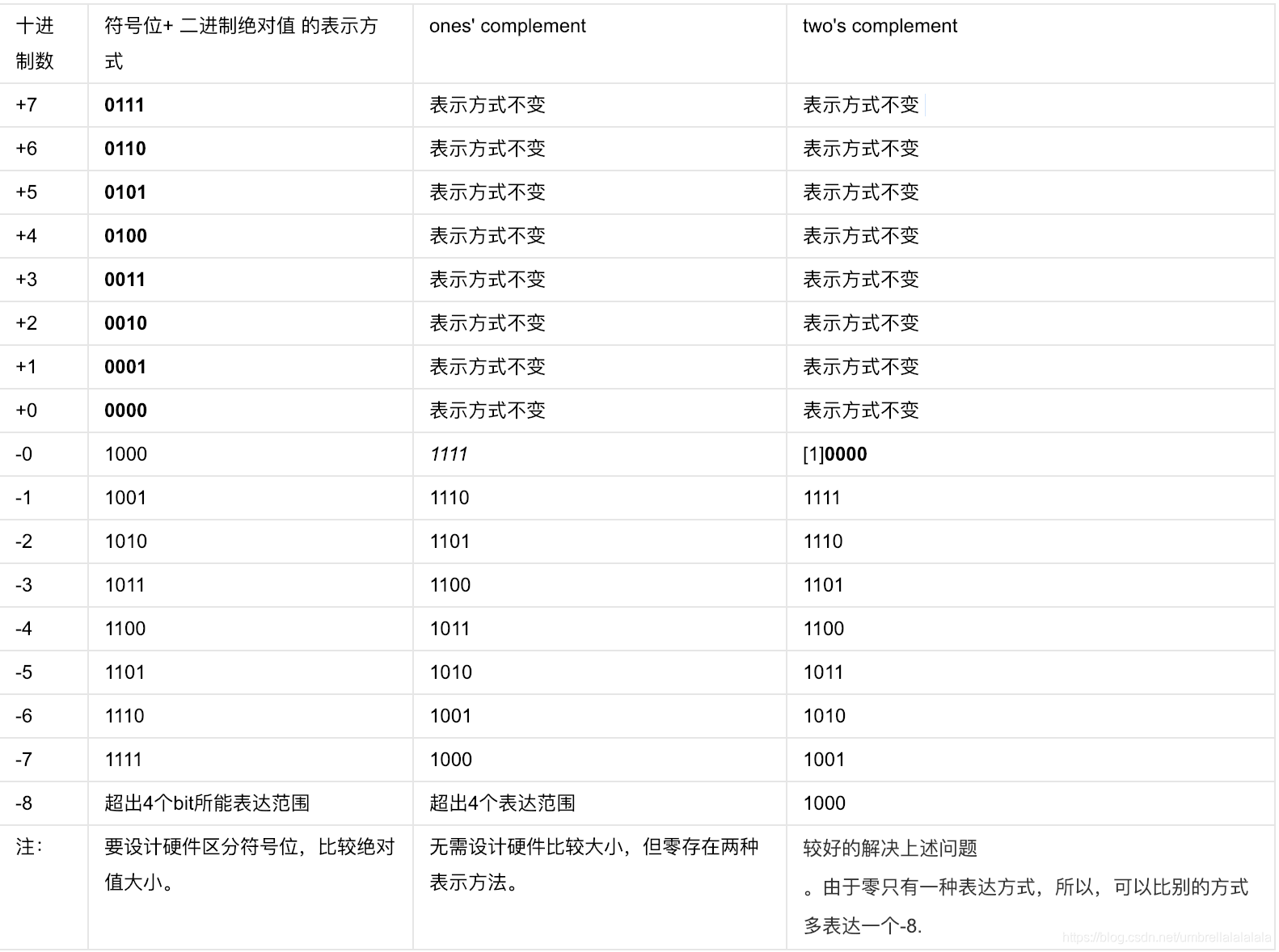
(在此友情提醒,谭浩强的C第四版图3.16(b)可能有错,应该是第一位1,后面15个0)
34、int a, b, c = 5只会对c赋值,若要对三者都赋值5,可写成:int a=5, b=5, c=5;
输入输出函数
35、printf:
(1)如果整数的范围在0~127的范围内,那么用%c占位符可以输出ASCII码相对应的字符,如果超过这个范围,则考虑最后一个字节的字符进行输出。比如以下两种方式均输出字符y(ASCII码为121或者01111001):
方式一
short a = 121;
printf("%c", a);
方式二
int a = 377;
printf("%c", a);
(2)-m.nf%代表输出数据占总列数(含小数点)为m,小数点后占的列数为n,左对齐;
(3)%e:
printf("%e", 123.456);
如上,如果不指定宽度,很多编译系统中的输出结果是:
1.234560e+002,意思是
。也可以利用%m.ne%的形式指定宽度:
printf("%13.2e", 123.456);
输出结果是:
()1.23e+002,“()”代表四个空格,这样总长度是13;
(4)%i作用同%d,按照十进制整数数据的实际长度输出,一般用%d而不是这个;
(5)%o以八进制整数形式输出:
int a = -1; //假设系统规定int占4字节
printf("%o\n", a);
得到结果是37777777777,因为-1在内存单元中是32个1(补码存储),八进制1位是二进制3位,所以有11位八进制数;
(6)%u无符号整型数据;
(7)%g:输出浮点数,系统自动选f格式或者e格式,选择长度较短的格式,不输出无意义的0;
36、scanf:
参数是格式和变量地址表列。
格式字符:
| 格式字符 | 说明 |
|---|---|
| d, i | 有符号十进制数 |
| u | 无符号十进制数 |
| o | 无符号八进制数 |
| x, X | 无符号十六进制数 |
| c | 单个字符 |
| s | 输入字符串,将字符串送到一个字符数组中,以非空白字符开始,以第一个空白字符结束,并以’\0’作为最后一个字符 |
| f | 用来输入实数,可用小数形式或指数形式(双精度要用lf) |
| e, E, g, G | 同f |
格式附加字符:
| 字符 | 说明 |
|---|---|
| l | 输入长数据,可用%ld,%lo,%lx,%lu,%lf(双精度),%le |
| h | 输入短数据,可用%hde,%ho,%hx |
| 域宽 | 正整数,指定输入数据所占宽度(列数) |
| * | 表示本输入项在读入后不赋给相应变量 |
37、putchar(),输出一个字符,参数可以是字符的ASCII码;
38、getchar(),输出一个字符。
⚠️键盘输入信息时,输入的字符先暂存在键盘的缓冲器中,只有按了enter键后才将字符送入计算机中,按照先后顺序分别赋给相应的变量。
示例:
char a, b, c;
a = getchar();
b = getchar();
c = getchar();
putchar(a);
putchar(b);
putchar(c);
putchar("\n");
如果输入"BOY",再按回车,那么三个字符进入计算机,然后分别赋值给a,b,c,这样在经过putchar()依次输出:
BOY
如果输入B、回车、O、回车,那么运行情况:
B
O
B
O
上述运行情况是这样的:输入B,B进入键盘缓冲区,输入回车,B和回车进入计算机,分别赋给a和b,然后再按O和回车,O赋给c,回车赋给下一个getchar();输出的时候就依次输出a、b、c,分别是B、回车、O,然后再用putchar("\n")输出一个回车。注意程序运行之后,计算机中仍有个回车,如果再使用一个getchar(),这个回车就会被其接收。
关系运算符和逻辑运算符
39、关系运算符和关系表达式:
大于、大于等于、小于、小于等于四种优先级高于等于和不等于;
a为3,b为2,c为1,则:
a>b值为真,表达式值为1;
(a>b) == c值为真,表达式值为1(注意a>b成立,所以其值为1,等于c的值,所以表达式为真);
f = a > b > c,f为0,因为>号是左结合的,先算a>b,为真,即值为1,然后算1>c,为假,值为0;
40、逻辑运算符优先级由高到低是非与或;
总的运算符优先级由高到低:
非、算数运算符、关系运算符、与或、赋值运算符;
⚠️表达式是从左向右扫描的,在扫描的过程中结合优先级进行判断。下列表达式结果是0:
5 > 3 && 8 < 4 - !0
分支结构要大量用到这一块的内容,顺便补充常见的逻辑判断:
闰年是能被4整除但不能被100整除的数,或者是能被400整除的数;
分支和循环
41、两种分支语句
if不再赘述,主要复习使用较少的switch,以下是示例:
#include<stdio.h>
int main(){
char grade;
scanf("%c", &grade);
printf("Your score:");
switch(grade){
case 'A':
printf("85~100\n");
break;
case 'B':
printf("70~84\n");
break;
……
default:
printf("enter data error!\n");
}
return 0;
}
运行结果:
A
Your score:85~100
default可以没有,且其在switch中的出现顺序不一定非要最后一个;
switch执行顺序是先计算grade的值,然后依次和各个case之后的值进行比较,找到匹配的则直接执行之,注意如果case中没有加break语句,则执行结束后顺序跳转到下一个case进行值的比较。如果没有case匹配,则执行default;
42、三种循环结构
for、while和do while,最后一种可以无条件循环一次,不是很常用。
一个重要例子:求100~200之间的所有素数
#include<stdio.h>
#include<math.h>
int main(){
int n, k, i, m = 0;
for(n=101; n<=200; n+=2){
k = sqrt(n); //用来求平方根,要求参数是双精度。执行时将整数n自动转化为双精度,
//计算出来的函数值也是双精度的,赋给整型k后自动省略小数部分。
for(i=2; i<=k; i++)
if(n%i==0) break;
if(i>=k+1){ //表明n未曾被整除过
printf("%d ", n);
m += 1;
}
if(m%10==0) printf("\n"); //每行只输十个数字
}
printf("\n");
return 0;
}
数组
43、数组的长度必须依赖于常量而不是变量,有种情况除外,那就是在被调用函数中定义的数组,其长度可以是变量或者非常量表达式:
void func(int n)
{
int a[n];
}
这是合法的,此情况称为“可变长数组”。但注意在执行函数的时候,n的值是不变的,数组长度是固定的,且如果指定数组为静态(static)存储方式,则不能用“可变长数组”:
void func(int n)
{
static int a[n]; //不合法
}
44、⭐️字符数组
由于字符型数据是按照整数形式(ASCII)存放的,因此可以用整型数组存放它的数据:
int c[10];
c[0] = 'a';
但是这样做浪费存储空间。
如果字符个数小于数组长度,比如:
char c[10] = {'c', ' ', 'p', 'r', 'o', 'g', 'r', 'a', 'm'}
那么数组的状态是这样的:
| c[0] | c[1] | c[2] | c[3] | c[4] | c[5] | c[6] | c[7] | c[8] | c[9] |
|---|---|---|---|---|---|---|---|---|---|
| c | 空格 | p | r | o | g | r | a | m | \0 |
其余的位置会自动补上“\0”,这个是空字符,编程时可以用这个判断数组末尾。
如果初值个数和数组长度相同,则不会在末尾补上这个空字符,而实际上,多数情况我们需要用这个“\0”来判断字符的有效长度,所以说定义字符数组时先估计字符串的长度,然后保证字符数组长度大于字符串的长度(当然是否需要“\0”还是用户来决定)。
上述有加“\0”和不加“\0”的情况,但下述情况必然会加“\0”(用字符串来初始化):
char c[] = {"deep dark fantasy"}
char c[] = "deep dark fantasy" //这两行等价
注意数组c的长度就不是17,而是18,因为要算上自动加上的“\0”。
但如果这样定义,就不会加“\0”:
char c[] = {'d', 'e', 'e', 'p', ' ', ……,'y'}
记住,只有用字符串初始化字符数组和(不管以什么形式初始化)数组长度超过字符串长的情况,才有“\0”。
使用%s输出字符串的时候,遇到第一个“\0”时,输出就结束。
利用一个scanf()输入多个字符串,需要以空格分离(多少个空格都一样):
char str1[5], str2[5], str3[5];
scanf("%s%s%s", str1, str2, str3);
输入how are you?,三个字符数组的状态如下:
| h | o | w | \0 | \0 |
|---|---|---|---|---|
| a | r | e | \0 | \0 |
| y | o | u | ? | \0 |
⚠️如果scanf输入项如果是字符数组名,就不要再加地址符,因为数组名就是数组的起始地址。
string.h中的字符处理函数:
(1)puts():将一个字符串(以“\0”结尾)输出到终端,输出的字符串可以包含转义字符,会将字符串结束标志的“\0”自动转换成“\n”。
(2)gets():从标准输入(键盘)读取一行数据,遇到换行符就返回,并将换行符替换成“\0”,键盘输入computer回车,gets接收到的是9个字符,最后一个是空字符。这个函数比较危险,它不会检查数组能否装得下输入行,所以C99不建议使用此函数。
(3)strcat(str1, str2):将str2接到str1后面,并将结果存储到str1中。将str1中的“\0”取消,只保留str2中的“\0”。
(4)strcpy(str1, str2):
char str1[10], str2[] = "China";
strcpy(str1, str2);
将str2中的前5个字符和其后的一个“\0”复制到str1中,取代其中前六个字符,但其后四个字符还是str1中原有的字符。
还有个扩展函数:
strncpy(str1, str2, 2); //将str2前2个字符复制到str1中,此处指定的复制个数不得超过str1原有的字符(不含“\0”)
(5)strcmp(str1, str2):字符串比较函数,从左至右依次比较ASCII码,直到遇到不相等或遇到“\0”的情况。若字符串相等,则返回0;若str1>str2,则返回正数,反之负数。(字符串大小比较指的是ASCII码的比较)
(6)strlen():
char str[10] = "China";
printf("%d\n", strlen(str));
输出结果是5,不包括最后的“\0”。
(7)大小写转换:
转换为小写:strlwr();
转换为大写:strupr();
函数注意事项和变量作用域、生存周期
45、形式参数和实际参数:调用函数的过程中,实参的数据会传递给形参;
46、函数的返回值是通过函数中的return语句获得的;
47、对被调用函数的声明:在一个函数中调用另一个用户自定义函数之前,应当先对被调用函数进行声明。声明的作用是将函数名、函数参数个数和参数类型等信息通知编译系统,以便在遇到函数调用的时候,编译系统能够正确识别函数并检查调用是否合法。
在函数声明中,形参可以简写,只写形参的类型而不写名称;
如果已经在某函数之前对被调用函数进行了“外部声明”,则不需要在函数内部再进行声明。写在所有函数前面的外部声明在整个文件范围内有效;
如果函数在被调用之前进行了定义,则不需要在被调用之前进行声明;
48、数组作为函数参数:
(1)数组元素作实参时,向形参传递的是数组元素的值;
(2)用数组名作函数实参时,向形参(数组名或指针变量)传递的是数组首元素的地址;(数组名本身代表数组首元素的地址,C语言编译系统不检查形参数组大小,形参数组只获得实参数组首元素地址,形参数组可以不指定大小:float average(float array[])只用方括号表示这是数组,但不指定大小);因为传递的是数组首地址,所以形参数组值发生变化时,会使得实参数组也发生变化;
(3)多维数组名作为函数参数:可以省略第一维大小说明,而不能省略第二维大小说明:
int array[][10]; //是对的
int array[3][]; //是错的
int array[][]; //是错的
原因:二维数组是由多个一维数组组成的,在内存中,数组是按行存放的,所以在定义二维数组时,必须指定列数(即一行中包含几个元素)。实参和形参必须是由相同长度的一维数组组成的,第二维相同的情况下,第一维可以不同,所以必须指定第二维大小;
49、局部变量和全局变量:
(1)在一个函数内部,可以在复合语句中定义变量,这些变量只在本复合语句中有效(复合语句就是用大括号包裹的几条语句);(这种复合语句称为“分程序”或“程序块”);
(2)函数(或程序块)内定义的变量是局部变量,函数外定义的变量是全局变量。前者的范围是自定义起到本程序块结束,后者的范围是自定义起到本源文件的结束;一个习惯是将全局变量名的第一个字母用大写表示;
为什么在不必要时尽量别用全局变量:
全局变量在程序全部执行过程中都占用存储单元,而不是仅在需要时才开辟单元;
降低函数通用性;降低程序清晰性;
50、变量存储方式和生存期:
(1)用户使用的存储空间分为:程序区、静态存储区、动态存储区,全局变量存放在静态存储区中,函数形参、函数中定义的未用static声明的变量(自动变量)、函数调用时的现场保护和返回地址都存放在动态存储区中;
(2)四种存储类别:自动的(auto)、静态的(static)、寄存器的(register)、外部的(extern),根据变量存储类别,可以知道变量的作用域和生存期;
也可将存储类别进一步划入局部和全局存储类别:
三种局部变量存储类别:
1)自动变量:
int f(int a)
{
auto int b, c = 3;
……
}
调用该函数时,系统会给这类变量分配存储空间,在函数调用结束时就自动释放这些存储空间,auto可以省略,不写之则隐含指定为“自动存储类别”;
2)静态局部变量:有时希望函数中的局部变量值在函数调用结束后不消失而是继续保留原值,即占用的内存单元不释放,下一次再调用该函数的时候,该变量已有值就是上一次函数调用结束时的值。
{
……
static int a; //静态局部变量
……
}
如非必要,不要使用静态局部变量,因为它多占内存,降低程序可读性,调用次数过多时,无法浓情静态局部变量当前值是多少;
3)寄存器变量:
register int f; //f为寄存器变量
寄存器的存取速度远高于内存的,所以对于使用频繁的变量可以使用这种方法提高速度;
全局变量的存储类别:
1)用extern扩展外部变量作用域:
如果外部变量不在文件的开头处定义,则有效范围只是定义位置到文件结束,用extern作“外部变量声明”,就可以从“声明”处起,合法使用该外部变量:
int main()
{
extern int A, B, C; //使得外部变量A,B,C能合法地从此处使用到文件结束
……
}
int A, B, C;
……
extern int A, B, C;亦可以写成extern A, B, C;,因为这不是真正的变量定义;
2)用extern将一个文件定义的外部变量作用域扩展到另一个文件:
file1.c:
int A;
……
file2.c:
extern A;
……
这样,file2也可以使用file1的外部变量A了;
3)将外部变量作用域限制在本文件中:
如果file1的主人不希望变量被file2拿去用,那么就可以:
file1.c:
static int A;
……
这是如果file2.c:
extern A;
……
就会出错。
⚠️不要以为对外部变量加static声明后才采取静态存储方式,而不加static的是采取动态存储。
真相是:对局部变量加static,则将其分配在静态存储区,该变量在其作用域结束后也暂不释放,而是坚挺到程序执行结束;对全局变量用static声明,则将该变量作用域限于本文件模块;
这一块内容要多加小心,auto和register声明不是很常见,重点掌握extern的用法,以及static对局部和全局变量的声明作用;
小结
对于数据,其有数据类型和存储类别两种属性,而存储类型对于全局和局部变量又可能有不同的功效(比如static声明全局或者局部变量功能不同)。下表汇总了不同类别的变量的可见性(能被引用)和生存期(存在)
| 函数内能被引用 | 函数内存在 | 函数外能被引用 | 函数外存在 | |
|---|---|---|---|---|
| 自动变量和寄存器变量 | ||||
| 静态局部变量 | ||||
| 静态外部变量 | (仅限本文件) | |||
| 外部变量 |
50、声明和定义
声明包括定义,但声明并非都是定义。
定义性声明(简称定义)举例:
int a;
引用性声明举例:
extern A;
⚠️外部变量的定义只能有一次,它的位置在所有函数之外(外部和局部变量的区别就在于其定义位置在“外面”还是“里面”)。
结论
在函数内对变量的声明(extern除外)都是定义,在函数内对其他函数的声明不是函数的定义。
51、内部函数和外部函数
内部函数示例:
static int func(int a, int b);
内部函数只能被本文件中其他函数所调用,又称静态函数(名称来源与它是用static定义的)。
⚠️通常把只能由本文件使用的函数、外部变量放在文件的开头,前面都加上static使之局部化,其他文件都不能引用,这就提高了程序的可靠性。记住,加了static的东东只能在本文件使用。
外部函数示例:
extern int func(int a, int b);
这样,函数就能被其他文件所使用,如果省略extern,则默认为外部函数。
以上部分所述C语言基本要素,构成了C语言的基本身躯,接下来总结指针,为C语言注入“灵魂”。
我偏爱用C++写面向过程的程序,因为它不仅包含了C语言的功能,还有一个不错的指针替代品——引用(自从学了引用,我几乎不用指针,除了接收数组的形参和malloc数组定义),除此之外还可以视情况添加面向对象的编程元素。指针被誉为C语言的灵魂,如果你强制我只用C写程序,那我的程序一定不是十尾,而是外道魔像。
三、指针
指针基本概念
1、指针变量
使用示例:
int *p1, *p2;
int a = 1;
int b = 2;
p1 = &a;
p2 = &b;
printf("p1:", * p1);
printf("p2:", * p2);
以上是指针变量的定义和指针指向内容的引用。
指针变量用作函数参数:
void swap(int * p1, int * p2){
int temp;
temp = * p1;
* p1 = * p2;
* p2 = temp;
}
以上代码实现指针指向的两个存储单元内容互换,但写成以下这样就有问题了:
void swap(int * p1, int * p2){
int * temp;
* temp = * p1;
* p1 = * p2;
* p2 = temp;
}
⚠️由于未给temp赋值,因此temp无确定的值,所以temp指向的单元是未知的,此时对* temp赋值,就相当于改变未知单元的值,万一改变的是重要单元,那么可能会破坏系统正常工作状况。
如果执行以下语句,则互换作用无法达成:
void swap(int x, int y){
int temp;
temp = x;
x = y;
y = temp;
}
x和y作为形参,两者互换,但不会影响到实参互换。
⚠️C语言中实参变量和形参变量之间的数据传递是单向传递,所以即便是通过指针的方式实现自定义swap函数的功能,也是将指针指向的存储空间中的量进行改变,而不是将指针本身的值(指针指向存储空间的地址)进行改变。
⚠️设有int * p定义的整型指针变量p,则形如p = xxx是改变指针变量的值,即指针变量指向的地址;形如* p = xxx是改变指针指向的地址中的内容,而指针的指向不变。
看一个重要概念:(此处大量参考百度知道用户CodeBlove的内容,详情见参考链接)
⚠️⚠️⚠️二维数组和指针的指针间的关系
二维数组名即数组地址,指向首行地址,不是指针的指针。
设有二维数组int a[10][10],假设a等价于指针的指针,则设int **p=a; 那么要对行递增执行p++时,由于int **是指指向一个 int *类型的指针,其数据宽度是4字节,内置宽度,因此p将指向下一个整数元素地址,也就是p递增了4字节,而不是10个int型数据的宽度,这就错位了。
所以a[10][10]的地址类型不是简单的指针的指针,应该是int (*)[10],而不是int **。
设int (*p)[10]=a,其含义为,p是一个指向含10个int类型元素的一维数组或行的指针。
指针和数组
2、通过指针引用数组
指针存储地址,而数组名就是数组首元素的地址。
示例:
int a[10];
…… //对a赋值
for(int i=0; i<10; i++){
printf("%d", *(a+i)); //但注意每次都要重新计算地址
}
上述代码可以依次输出数组的十个元素,a代表数组首元素地址,a+i代表第(i+1)个元素的地址,当进行a+i操作的时候,系统会自动根据a的基类型将i转换为相应的数字,比如此处a的基类型是int,则使用VC++ 6.0的系统自动将+i转换为+4。
*(a+i)引用数组元素的方法叫指针法,a[i]引用数组元素的方法叫下标法;
⚠️以上代码算不上真正的通过指针引用数组元素,在使用a[i]时,C编译器会将a[i]转化为*(a+i),再计算元素地址,即使用a[i]和*(a+i)效率是相同的。
以下是利用指针的方式来输出数组中的全部元素:
for(p=a; p<(a+10);p++){
printf("%d", * p);
}
用指针变量直接指向元素,不必每次都重新计算地址,将指针在变量上进行移动(p++)也是较为迅速的操作。
调用自定义函数,传递参数的时候,系统是将形参数组名当作指针变量来处理的,以下两种写法是等价的:
func(int a[], int n);
func(int * a, int n);
3、通过指针引用多维数组
设有二维数组a[3][4],则:
| 符号 | 意义 |
|---|---|
| a | 指向第0行,即第0行首地址 |
| a+i | 指向第i行,即第i行首地址 |
| a[0],*(a+0),*a | 指向第0行第0个元素 |
| a[1]+2,*(a +1)+2,&a[1][2] | 指向第1行第2个元素 |
| *(a[1]+2),a[1][2] | a[1][2] |
| * (*(a+1)+2) | a[1][2] |
理解上表,只需将二维数组想象成多行组成,每一行是一个一维数组。
⚠️&a[i]或a+i指向行,a[i]或*(a+i)指向列
指向二维数组的指针变量的两种方式:
(1)使用int *型指针变量:
int a[3][4] = {……}
int * p;
for(p=a[10]; p<a[0]+12; p++){
printf("%4d", * p);
}
(2)使用int(*)[4]型指针变量
int a[3][4] = {……}
int (* p)[4]
p = a;
printf("%d", * (*(p+i)+j));
(这种写法真是要多麻烦有多麻烦,反正博主是从来不用的)
小结
引用数组元素的三种方式中,a[i]和*(a+i)的方式效率一样,都比较费时,因为每次都要重新计算地址,定义一个指针变量指向数组元素,通过指针变量自加操作遍历数组元素则较为高效;
⚠️要区分数组名a和指针p的区别,后者是指针变量,但前者a是指针常量,所以a++操作是行不通的。
指针和字符串
4、通过指针引用字符串
首先区别以下两种方式:
//方式一
char * string;
string = "deep dark fantasy";
//方式二
char * string;
*string = "deep dark fantasy";
不要认为以上两种方式是等价的,前者是将字符串的首地址赋给指针变量string,后者是将指针变量指向的地址的内容变成那个字符串;
再来看看字符串的输出方式:
printf("%s\n", string);
%s是输出字符串时所用的格式符,再输出项中给出字符指针变量名string,则系统会输出string指向的字符串的第一个字符,然后自动使string加1,使之指向下一个字符,再输出该字符……直到遇到\0为止。用字符数组名或字符指针变量名都可以输出一个字符串,但是对于数值型数组,不能企图用数组名输出它的全部元素。
⚠️"deep dark fantasy"是字符串常量,C语言对字符串常量是按照字符数组处理的,在内存中开辟了一个字符数组来存放该字符串常量,但这个字符数组是没有名字的,因此不能通过数组名来引用,只能通过指针变量来引用。
5、字符指针变量和字符数组名的比较
首先,调用函数时,函数的形参和实参都可以是字符数组名或字符指针变量中的一种。
接下来,讲讲两者在其他方面的使用异同:
字符数组名和字符指针变量保存的都是字符串第一个字符的地址,但是只能对后者赋值操作:
char * a;
a = "I am umbrellalalalala";
这样是没问题的,但下面的方法是错的:
char str[14];
str = "I am umbrellalalalala"; //数组名是地址,是常量,不能被赋值
str[] = "I am umbrellalalalala"; //这样赋值也是非法的
//如果是对单个数组元素赋值则没问题:str[0] = "I"
⚠️定义了字符指针变量(或者其他指针变量)的时候,应当立刻给它赋值,否则它将指向一个未知的地址,如果给那个地址输入数据,同时那个地址碰巧是系统区之类的地方,则会出问题:
char * a; //定义字符指针变量a,此时a指向的地址未知
//下面这个语句改变的不是a的指向,而是a指向的地址的内容!
scanf("%s", a); //键盘输入一个字符串,字符串被存储到a指向的内存单元开始的一段连续内存单元中,
//VC++ 6.0编译这种语句时会给出警告
所以应当在定义了指针变量后,及时指定其指向。
看一个有趣的字符指针变量用法开开眼界:
int x = 666;
char * format;
format = "%d\n";
printf(format, x); //输出666,换行
指针和函数
接下来总结博主从来没用过的函数指针。
6、函数指针定义和基本使用:
如果在程序中定义了一个函数,在编译时,编译系统为函数代码分配一段存储空间,这段存储空间的起始地址(又称入口地址)就是这个函数的指针。
使用指针变量访问用户自定义的函数:
#include<stdio.h>
int main(){
int max(int, int); //用户自定义函数的声明
int (*p)(int, int); //定义指向函数的指针变量p
p = max; //指针指向函数(将函数名“赋给”指针变量)
……
//接下来使用自定义函数
c = (*p)(a, b);
……
}
int max(int x, int y) //max函数的定义,略
……
注意(*p)代表max函数,括号不能省略,因为*要和p先结合。如果写成了int * p(int, int),这个是范围整型指针的p函数。
要先将函数入口地址赋给指针,才能用指针使用函数,注意地址赋值操作不能写成:
p = max(a, b)
这样就变成了将函数所得到的函数值赋给p。
7、用指向函数的指针作函数参数
直接看用法:
void func(int (* x1)(int), int (* x2)(int, int)){
……
a = (* x1)(1);
b = (* x2)(2, 3);
……
}
如果func经常需要调用不同的函数,也就是说func的参数经常要改变,那么这种情况下的函数指针的使用就非常方便了,只需要每次调用func时给出不同的函数名作为实参就行了。
指针数组和多重指针
8、区分指针数组和“数组指针”
下面定义一个指针数组:
int *p[4];
下面定义一个指向一维数组的指针变量:
int (* p)[4];
9、指向指针的指针
简单看一个例子:
#include<stdio.h>
int main(){
char *name[] = {"deep", "dark", "fantasy"}; //定义一个指针数组,每个数组元素指向一个字符串
char **p;
int i;
for(i=0; i<5; i++){
p = name + i;
printf("%s\n", *p);
}
return 0;
}
运行结果:
deep
dark
fantasy
完♂美
依次类推,还可以定义int ***型,int ****型指针,但不常见也没必要。
10、动态分配内存
这里谭浩强的书上介绍了calloc、realloc、malloc、free函数,这里只介绍malloc和free,例子:
int *p, i, n;
scanf("%d", &n); //可以在运行时指定数组大小
p = (int *)malloc(n * sizeof(int));
for(i=0; i<n; i++){
scanf("%d", p+i);
}
……
free(p); //使用完这个数组,将其指向的动态分配的空间释放
这个代码段实现程序运行时再指定数组大小,并向数组中输入元素,使用完释放动态分配的空间。
11、void指针类型
void * p;
p = &a; //相当于执行p = (void *)&a
执行后p得到a的纯地址,但不指向a,不能通过*p输出a的值。
12、指针的其他概念
(1)指针和指针变量
指针就是地址本身,指针变量是存储地址的变量。
(2)重点区分int (* p)[4]和int * p[4]:
前者是指向包含四个元素的一维数组的指针变量;后者是指针数组,包含四个指向整型数据的指针元素。
四、用户自建数据类型
结构体及其使用
1、结构体定义和基本使用
struct Date //定义一个叫Date的结构体
{
int month;
int day;
int year;
};
struct Student
{
int num;
char name[20];
char sex;
int age;
struct Date birthday; //结构体可以“嵌套使用”,定一个 Date型的结构体变量名曰birthday,
//作为Student结构体的成员
char addr[30];
};
struct Student student1, student2; //利用定义好的结构体定义两个结构体变量
struct Philosophy{ //定义结构体的同时定义结构体变量,可同时给结构体变量初始化,也可以不初始化
char name[20];
char addr[20];
char profession[20];
} Van = {"Van", "next door", "artist"}, Billy; //注意分号的位置
//使用以上定义的结构体变量
printf("%s\n%s\n%s\n", Van.name, Van.addr, Van.profession};
C99标准允许对结构体变量的某一个成员进行初始化:
//定义一个Student结构体变量b,只指定b的name
struct Student b = {.name = "xiaoming"}; //name之前有成员运算符“.”
如果未进行初始化,那么数值型成员会被系统初始化为0,字符型成员会被系统初始化为’\0’,指针型成员会被初始化为NULL。
注意以下操作,由于.运算符优先级最高,所以:
b.age++
是对b的成员age进行自加操作。
同类的结构体变量可以互相赋值:
struct Student c, d;
d = {……}; //初始化内容略
c = d; //这样c的成员值和d的一样
2、结构体数组
struct Person{
char name[20];
int count;
}leader[3] = {"Li", 0, "Zhang", 0, "Sun", 0};
结构体数组名为leader,大小为3,上述初始化方式直接在大括号中方6个值,每个结构体变量有两个成员,这种方式恰能按序给三个数组元素赋值。
3、结构体指针
指向一个结构体变量的指针:
struct Student e; //继续使用1中定义的结构体变量
struct Student *p;
p = &e;
这样操作后,e.name和(*p).name以及p->name(常用)是一样的。
指向结构体数组的指针:
struct Student stu[3] = {{stu[1]的成员值}, {stu[2]的成员值}, {stu[3]的成员值}};
for(struct Student * p = stu; p<stu+3; p++)
printf (p当前指向的结构体变量);
上述伪代码,p在循环中,依次指向结构体变量stu[1]、stu[2]、stu[3]。
还可以用结构体变量和结构体变量指针做函数参数,此处略。
从来没用过的共用体
说实话,这部分内容过去也就在各种考试前看过,实际使用频率为0……但既然都写了这么多了,姑且就将这部分内容总结下:
4、共用体的三种声明和定义的形式:
(1)声明共用体的同时定义变量:
union Data{
int i;
char ch;
float f;
}a, b, c;
(2)先声明共用体,再定义变量:
union Data{
int i;
char ch;
float f;
}
union Data a, b, c;
(3)声明共用体的同时定义变量,但不说明共用体的名称:
union{
int i;
char ch;
float f;
}a, b, c
5、共用体和结构体的区别:
结构体变量所占内存长度是各成员占的内存长度只和,每个成员分别占有其自己的内存单元。而共用体变量所占内存长度等于最长的成员的长度。
也就是说,共用体变量对应的同一个内存段可以用来存放几种不同类型的成员,但在每一瞬时只能存放其中一个成员。因为在每一个瞬时,存储单元只能有唯一的内容。例子:
union Data{
int i;
char ch;
float f;
}a;
a.i = 97;
表示将整数97存到共用体变量中,显然此时a中只有i有用户想要的值,但也不是不可以强行输出所有成员:
//注意97在内存中是01100001
printf("%d", a.i); //输出的是97
printf("%c", a.ch); //输出的是字母'a',因为'a'的ASCII码是97
printf("%f", a.f); //输出0.000000
按照浮点数形式输出为0的解释:
浮点数占32位,1位符号位+8位指数位+23位尾数位:
00000000,00000000,00000000,01100001对于float型而言,指数位全是0,而实际上计算出来的指数要加127再作为指数位进行存储 。
补充内容:
float型的2.0的存储方式,2.0写作二进制的科学计数法为:
符号位为0(正),指数位为
,尾数位是0(只取1.0的小数部位)
所以在内存中,以32位float型存储为:
0,10000000,00000000000000000000000 //1符号、8指数、23尾数
所以说,int型的97在内存中的二进制序列,以float型的眼光看待,就是0(个人认为理由是指数位全零是非法的,或者指数位全零是特指float型的0)。
判断对错:
union Data{
int i;
char ch;
float f;
}
union Data a = {1, 'a', 1.5}; //错误,不能初始化多个成员,它们占用同一段存储单元
union Data a = {15}; //正确,对第一个成员初始化
union Data a = {.ch='j'} //正确,C99允许用这种方式对特定的成员初始化
⚠️共用体变量中起作用的成员是最后一次被赋值的成员。
C99允许同类型的共用体变量相互赋值:
b = a; //a和b都是同类型的共用体,合法
但是不允许对共用体变量赋值,也不可以企图引用共用体变量名以得到一个值赋给非共用体变量。
枚举类型
使用频率类似于switch语句,简单总结如下:
6、枚举类型介绍,直接看代码:
enum Weekday{sun, mon, tue, wed, thu, fri, sat}; //enum用来声明枚举类型,大括号中的称为枚举元素
enum Weekday workday; //声明枚举变量
//辨别正误:
workday = mon; //正确,mon是指定的枚举常量之一
workday = monday; //错误,monday不是指定的枚举常量之一
mon = 1; //错误,不能以这种形式对枚举元素赋值
枚举元素的引用和赋值:每一个枚举元素都代表一个整数,比如上面定义的Weekday中,sun为0,mon为1……所以赋值语句workday = mon;相当于workday = 1。可以将枚举常量当作整数输出:
printf("%d", workday);
输出的是1。依此类推,枚举常量还可以用作条件分支中整数之间的比较。
虽然枚举元素的值不能单独指定数值,但是可以在定义枚举类型的时候显示指定:
enum Weekday{sun=7, mon=1, tue, wed =3, thu, fri, sat}workday, weekend
typedef的使用方法
7、
个人认为typedef主要用于增强程序可读性的场合,博主参与算法竞赛期间没有用过,但写游戏这种设计大规模编程工作的任务中少不了它。
typedef int Integer;
typedef float Real;
//上面两行执行后,下面两行等价
int i;
Integer i;
//下面两行也等价
float f;
Real f;
代码讲得很清楚了,typedef就是给类型名重新起个名字使用,达到自己想要的可读性目标。
也可以用这个来简化复杂类型表示方法:
int * (* (*)[10])(void) //指向包含10个元素的一维数组的指针,数组元素的类型为函数指针,
//函数没有参数,函数的返回值是int指针
是不是巨鸡儿(文明你我他)麻烦?这时候用typedef来简化十分方便,不过谭浩强系列书上没给这种的具体表示,估计实际中用不到,等我们能用到时再说,咱不深究这个问题。
再看一个例子,用typedef简化结构体(这可能是typedef最常用的地方,特别是在《数据结构》这门课中):
typedef struct{
int month;
int day;
int year;
}Date;
Date birthday; //定义结构体变量,不要写成struct Date birthday
Date *p; //定义结构体指针变量p,指向此结构体类型数据
简化数组:
typedef int Num[100];
Num a; //定义整型数组a,a中有100个元素
简化指针:
type char * String;
String p, s[10]; //p为字符指针变量,s为字符指针数组
简化数组指针:
typedef int ( * Pointer)(); //Pointer是指向函数的指针类型,函数返回整型值
Pointer p; //p为Pointer类型的指针变量
typedef记忆技巧:
如果去掉typedef,剩下的部分应当是一个完整的变量或别的什么的定义:
typedef int Num[100]; //Num是指定的名称
//去掉typedef后:
int Num[100]; //Num是被定义的变量
五、对文件的操作
未完待续
