1.c++中 . 和 -> 主要是用法上的不同。
A.B则A为对象或者结构体;
A->B则A为指针,->是成员提取,A->B是提取A中的成员B,A只能是指向类、结构、联合的指针;
2.写输出文件
#include<iostream>
ofstream f;
f.open("地址/想要创建的文件名及文件类型如:pose_array.txt");
f << fixed;
此处是循环体,循环存入数据
f.close();
3.C++中的矩阵相乘
Mat矩阵dot——A.dot(B)
Opencv中.dot操作才算得上是真正的“点乘”,A.dot(B)操作相当于数学向量运算中的点乘,也叫向量的内积、数量积。
对两个向量执行点乘运算,就是对这两个向量对应位一一相乘之后求和的操作,点乘的结果是一个标量。
对于向量a和向量b:
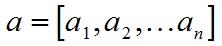
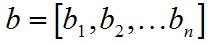
a和b的点积公式为:
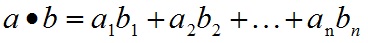
要求向量a和向量b的行列数相同。
Mat矩阵的dot方法扩展了一维向量的点乘操作,把整个Mat矩阵扩展成一个行(列)向量,之后执行向量的点乘运算,仍然要求参与dot运算的两个Mat矩阵的行列数完全一致。
dot方法声明中显示返回值是double,所以A.dot(B)结果是一个double类型数据,不是Mat矩阵,不能把A.dot(B)结 果赋值给Mat矩阵!
Mat矩阵mul——A.mul(B)
Opencv中mul会计算两个Mat矩阵对应位的乘积,所以要求参与运算的矩阵A的行列和B的行列数一致。计算结果是跟A或B行列数一致的一个Mat矩阵。
以简单的情况为例,对于2*2大小的Mat矩阵A和B:
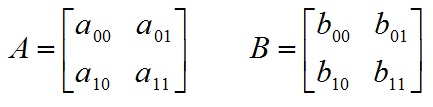
对A和B执行mul运算:
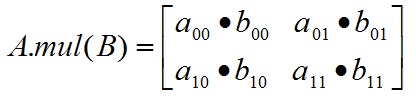
mul操作不对参与运算的两个矩阵A、B有数据类型上的要求,但要求A,B类型一致,不然报错;
Mat AB=A.mul(B),若声明AB时没有定义AB的数据类型,则默认AB的数据类型跟A和B保存一致;
若AB精度不够,可能产生溢出,溢出的值被置为当前精度下的最大值;
4.iterator begin(),end(),*first,*last
#include <iterator>
std::vector<int> IntVector;
std::vector<int>::iterator first=IntVector.begin();
// begin()得到指向vector开头的Iterator,*first得到开头一个元素的值
std::vector<int>::iterator last=IntVector.end();
// end()得到指向vector结尾的Iterator,*last得到最后一个元素的值
5. STL
1.容器
STL容器,即是将最常运用的一些数据结构(data structures)实现出来。容器是指容纳特定类型对象的集合。根据数据在容器中排列的特性,容器可概分为序列式(sequence)和关联式(associative)两种。迭代器是一种检查容器内元素并遍历元素的数据类型。它提供类似指针的功能,对容器的内容进行访问。
1.1序列式容器
序列式容器中的元素都可序(ordered),但未必有序(sorted)。数组为C++语言内置的序列容器,STL另外提供vector、list、deque(double-ended queue)。它们的差别在于访问元素的方式,以及添加或删除元素相关操作的运行代价。
Vector
vector是标准C++建议替代C数组的动态数组模型,它维护的是一个连续线性空间。采用的数据结构非常简单:线性连续空间。它以两个迭代器start和finish分别指向配置得到的连续空间中目前已被使用的范围,并以迭代器end_of_storage指向整块连续空间(含备用空间)的尾端。
vector的实现技术,关键在于其对大小的控制以及重新分配时的数据移动效率。一旦vector原有空间用完,如果客户端每新增一个元素,vector内部就只扩充一个元素的空间,实为不智。注意,所谓动态增加大小,并不是在原空间之后接续新空间(因为无法保证之后尚有可供配置的空间),而是每次再分配原大小两倍的内存空间。因此,对vector的任何操作,一旦引起控件重新配置,指向原vector的所有迭代器就都失效了。
由于vector维护的是一个连续线性空间,因此vector迭代器具备普通指针的功能,支持随机存取,即vector提供的是Random Access Iterators。
向量类模板std::vector的成员函数
#include<vector>
std::vector<type> vec;
std::vector<type> vec(size);
std::vector<type> vec(size,value);
std::vector<type> vec(myvector);
std::vector<type> vec(first,last);
Operators:==、!=、<=、>=、<、>、[]
assign(first,last):用迭代器first,last所指定的元素取代向量元素
assign(num,val):用val的num份副本取代向量元素
at(n):等价于[]运算符,返回向量中位置n的元素,因其有越界检查,故比[]索引访问安全
front():返回向量中第一个元素的引用
back():返回向量中最后一个元素的引用
begin():返回向量中第一个元素的迭代器
end():返回向量中最后一个元素的下一个迭代器(仅作结束游标,不可解引用)
max_size():返回向量类型的最大容量(2^30-1=0x3FFFFFFF)
capacity():返回向量当前开辟的空间大小(<= max_size,与向量的动态内存分配策略相关)
size():返回向量中现有元素的个数(<=capacity)
clear():删除向量中所有元素
empty():如果向量为空,返回真
erase(start,end):删除迭代器start end所指定范围内的元素
erase(i):删除迭代器i所指向的元素
erase()返回指向删除的最后一个元素的下一位置的迭代器
insert(i,x);把x插入到迭代器i所指定的位置之前
insert(i,n,x):把x的n份副本插入到迭代器i所指定的位置之前
insert(i,start,end):把迭代器start和end所指定的范围内的值插入到迭代器i所指定的位置之前
push_back(x):把x推入(插入)到向量的尾部
pop_back():弹出(删除)向量最后一个元素
rbegin():返回一个反向迭代器,该迭代器指向的元素越过了向量中的最后一个元素
rend():返回一个反向迭代器,该迭代器指向向量中第一个元素
reverse():反转元素顺序
resize(n,x):把向量的大小改为n,新元素的初值赋为x
swap(vectorref):交换2个向量的内容
List
list与向量(vector)相比, 它允许快速的插入和删除,且每次插入或删除一个元素,就配置或释放一个元素空间。因此,list对于空间的运用绝对的精准,一点也不浪费。而且,对于任何位置的元素插入或元素移除,list永远是常数时间。
list不再能够像vector那样以普通指针作为迭代器,因为其节点不保证在储存空间中连续存在。list迭代器必须有能力指向list的节点,并有能力进行正确的递增、递减、取值、成员存取等操作。所谓“list迭代器正确的递增、递减、取值、成员取用”操作是指,递增时指向下一个节点,递减时指向上一个节点,取值时取的是节点的数据值,成员取用时取用的是节点的成员。
list是一个环状双向链表,所以它只需要一个指针,便可以完整实现整个链表。由于list是一个双向链表(double linked-list),迭代器必须具备前移、后移的能力,所以list提供的是Bidirectional Iterators。
list有一个重要性质:插入操作(insert)和合并操作(splice)都不会造成原有的list迭代器失效。这在vector是不成立的,因为vector的插入操作可能造成记忆体重新配置,导致原有的迭代器全部失效。甚至list的元素删除操作(erase)也只有“指向被删除元素”的那个迭代器失效,其他迭代器不受任何影响。
链表类模板std::list成员函数
#include<list>
std::list<type> lst;
std::list<type> lst(size);
std::list<type> lst(size,value);
std::list<type> lst(mylist);
std::list<type> lst(first,last);
//以下未列出与vector相同的通用操作。
push_front(x):把元素x推入(插入)到链表头部
pop_front():弹出(删除)链表首元素
merge(listref):把listref所引用的链表中的所有元素插入到链表中,可指定合并规则
splice():把lst连接到pos的位置
remove(val):删除链表中所有值为val的元素
remove_if(pred):删除链表中谓词pred为真的元素(谓词即为元素存储和检索的描述,如std::less<>,std::greater<>那么就按降序/升序排列,你也可以定义自己的谓词)
sort():根据默认的谓词对链表排序
sort(pred):根据给定的谓词对链表排序
unique():删除链表中所有重复的元素
unique(pred):根据谓词pred删除所有重复的元素,使链表中没有重复元素
注意:vector和deque支持随机访问,而list不支持随机访问,因此不支持[]访问!
Deque
vector是单向开口的连续线性空间,deque则是以中双向开口的连续线性空间。可以在头尾两端分别做元素的插入和删除操作。
deque和vector的最大差异,一在于deque允许于常数时间内对头端进行元素的插入或移除操作,二在于deque没有所谓容量(capacity)观念,因为它是动态地以分段连续空间组合而成,随时可以增加一段新的空间并链接起来。换句话说,像vector那样“因旧空间不足而重新配置一块更大空间,然后复制元素,再释放旧空间”这样的事情在deque中是不会发生的。也因此,deque没有必要提供所谓的空间预留(reserved)功能。
虽然deque也提供Random Access Iterator,但它的迭代器并不是普通指针,其复杂度和vector不可同日而语,这当然涉及到各个运算层面。因此,除非必要,我们应尽可能选择使用vector而非deque。对deque进行的排序操作,为了最高效率,可将deque先完整复制到一个vector身上,将vector排序后(利用STL的sort算法),再复制回deque。
deque是由一段一段的定量连续空间构成。一旦有必要在deque的前端或尾端增加新空间,便配置一段定量的连续空间,串接在整个deque的头端或尾端。deque的最大任务,便是在这些分段的定量连续空间上,维护其整体连续的假象,并提供随机存取的接口。避开了“重新配置、复制、释放”的轮回,代价则是复杂的迭代器架构。
双端队列类模板std::deque成员函数
#include<deque>
std::deque<type> deq;
std::deque<type> deq(size);
std::deque<type> deq(size,value);
std::deque<type> deq(mydeque);
std::deque<type> deq(first,last);
其成员函数如下:
Operators:[]用来访问双向队列中单个的元素
front():返回第一个元素的引用
push_front(x):把元素x推入(插入)到双向队列的头部
pop_front():弹出(删除)双向队列的第一个元素
back():返回最后一个元素的引用
push_back(x):把元素x推入(插入)到双向队列的尾部
pop_back():弹出(删除)双向队列的最后一个元素
Stack
stack是一种后进先出(FILO)的数据结构,只有一个出口。stack允许新增元素、移除元素、取得最顶端元素。但除了最顶端外,没有任何其他方法可以存取stack的其他元素,stack不允许随机访问。
STL以deque作为stack的底层结构,对deque封闭期头端开口,稍作修改便形成了stack。
将元素插入stack的操作称为push,将元素弹出stack的操作称为pop。只有stack顶端的元素,才有机会被外界取用。stack不提供走访功能,也不提供迭代器。
容器适配器堆栈类std::stack成员函数
#include<stack>
stack实现后进先出的操作
std::stack<type,container> stk;
type为堆栈操作的数据类型
container为实现堆栈所用的容器类型,默认基于deque,还可以为std::vector和std::list
例如std::stack<int,std::list<int>> IntStack;
其成员函数如下:
top():返回顶端元素的引用
push(x):将元素压入栈(顶)
pop():弹出(删除)顶端元素
Queue
queue是一种先进先出(FIFO)的数据结构,它有两个出口。queue允许新增元素、移除元素、从最底端加入元素、取得最顶端元素。但除了最底端可以加入、最顶端可以取出,没有任何其他方法可以存取queue的其他元素。换言之,queue不支持随机访问。
STL以deque作为queue的底层结构,对deque封闭其底端的出口和前端的入口,稍作修改便形成了queue。
容器适配器队列类std::queue成员函数
#include<queue>
queue实现先进先出的操作
std::queue<type,container> que;
type为队列操作的数据类型
container为实现队列所用的容器类型,只能为提供了push_front操作的std::deque或std::list,默认基于std::deque
其成员函数如下:
front():返回队首元素的引用
back():返回队尾元素的引用
push(x):把元素x推入(插入)到队尾
pop():队首元素出列(弹出(删除)队首元素)
1.2关联式容器
关联式容器:每项数据(元素)包含一个键值(key)和一个实值(value)。当元素被插入到关联式容器中时,容器内部数据结构便依照其键值大小,以某种特定规则将这个元素放置于适当位置。关联式容器没有所谓头尾(只有最大元素和最小元素),所以不会有push_back(),push_front(),pop_back(),pop_front(),begin(),end()这样的操作。
标准的STL关联式容器分为set(集合)和map(映射类)两大类,以及这两大类的衍生体multiset(多键集合)和multimap(多键映射表)。
Map
关联式容器std::map成员函数
#include<map>
map建立key-value映射
std::map<key, value> mp;
std::map<key, value, comp> mp;
key为键值,value为映射值,comp可选,为键值对存放策略,例如可为std::less<>,键值映射对将按键值从小到大存储
其成员函数如下:
count():返回map中键值等于key的元素的个数
equal_range():函数返回两个迭代器——一个指向第一个键值为key的元素,另一个指向最后一个键值为key的元素
erase(i):删除迭代器所指位置的元素(键值对)
lower_bound():返回一个迭代器,指向map中键值>=key的第一个元素
upper_bound():函数返回一个迭代器,指向map中键值>key的第一个元素
find(key):返回键值为key的键值对迭代器,如果没有该映射则返回结束游标end()
注意map的[]操作符,当试图对于不存在的key进行引用时,将新建键值对,值为空。
2.STL常见容器的优缺点
verctor
vector类似于C语言中的数组,它维护一段连续的内存空间,具有固定的起始地址,因而能非常方便地进行随机存取,即 [] 操作符,但因为它的内存区域是连续的,所以在它中间插入或删除某个元素,需要复制并移动现有的元素。此外,当被插入的内存空间不够时,需要重新申请一块足够大的内存并进行内存拷贝。值得注意的是,vector每次扩容为原来的两倍,对小对象来说执行效率高,但如果遇到大对象,执行效率就低了。
list
list类似于C语言中的双向链表,它通过指针来进行数据的访问,因此维护的内存空间可以不连续,这也非常有利于数据的随机存取,因而它没有提供 [] 操作符重载。
deque
deque类似于C语言中的双向队列,即两端都可以插入或者删除的队列。queue支持 [] 操作符,也就是支持随机存取,而且跟vector的效率相差无几。它支持两端的操作:push_back,push_front,pop_back,pop_front等,并且在两端操作上与list的效率也差不多。或者我们可以这么认为,deque是vector跟list的折中。
map
map类似于数据库中的1:1关系,它是一种关联容器,提供一对一(C++ primer中文版中将第一个译为键,每个键只能在map中出现一次,第二个被译为该键对应的值)的数据处理能力,这种特性了使得map类似于数据结构里的红黑二叉树。
multimap
multimap类似于数据库中的1:N关系,它是一种关联容器,提供一对多的数据处理能力。
如果需要高效的随机存取,不在乎插入和删除的效率,使用vector;
如果需要大量的插入和删除元素,不关心随机存取的效率,使用list;
如果需要随机存取,并且关心两端数据的插入和删除效率,使用deque;
如果打算存储数据字典,并且要求方便地根据key找到value,一对一的情况使用map,一对多的情况使用multimap;
3.迭代器
迭代器提供对一个容器中的对象的访问方法,并且定义了容器中对象的范围。迭代器就如同一个指针。C++的指针也是一种迭代器。但迭代器不仅仅是指针,不一定具有地址值。例如,一个数组索引,也可以认为是一种迭代器。
迭代器的类型
对于STL数据结构和算法,你可以使用五种迭代器。下面简要说明了这五种类型:
Input iterators 提供对数据的只读访问。
Output iterators 提供对数据的只写访问
Forward iterators 提供读写操作,并能向前推进迭代器。
Bidirectional iterators提供读写操作,并能向前和向后操作。
Random access iterators提供读写操作,并能在数据中随机移动。
尽管各种不同的STL 实现细节方面有所不同,还是可以将上面的迭代器想象为一种类继承关系。从这个意义上说,下面的迭代器继承自上面的迭代器。由于这种继承关系,你可以将一个 Forward迭代器作为一个output或input迭代器使用。同样,如果一个算法要求是一个bidirectional 迭代器,那么只能使用该种类型和随机访问迭代器。