8 采样
其他
2020-01-12 12:37:02
阅读次数: 0
- 采样,从特定的概率分布中抽样本点
- 将复杂的分布简化为离散样本点
- 可用重采样对样本集调整以更好适应后期模型学习
- 随机模拟以进行复杂模型的近似求解或推理
- 采样在数据可视化方面
- 均匀、高斯,编程语言里有直接的采样函数。
- 这些简单分布,果样过程也不显而易见的,仍需精心设计
- 复杂的分布,没直接采样函数可调用,
- 通过一系列的问题与解答来,
- 采样的作用、
- 果样方法、
- 采样在分布或模型上的具体实现,
- 采样的应用。
1 采样的作用
场描述
- 采样是从特定的概率分布中抽取对应的样本点。
- 这些抽取出来的样本有什么用?
- 为什么需要采样?
- 采样可用来解决什么问题?
举例说明采样在机器学习中的应用。
分析与解答
- 采样本质是对随机现象的模拟,
- 根据给定的概率分布,
- 模拟产生一个对应的随机事件。
- 让人对随机事件及其产生过程有直观认识。
- 二项分布采样,可模拟“抛硬币正还是反”这个随机事件,
- 进而模拟产生一个多次抛硬币出现的结果序列,
- 或计算多次抛硬币后出现正面的频率。
- 采样得到的样本集可看作一种非参数模型,
- 即用较少量的样本点(经验分布)来近似总体分布,
- 并刻画总体分布中的不确定性。
- 这个角度来说,采样是种信息降维,起到简化问题。
- 训练机器学习模型时,想要优化的是模型在总体分布上的期望损失(期望风险),但总体分布可能含无穷多个样本点,要在训练时全部用上不可能
- 因此,一般用总体分布的一个样本集来作为总体分布的近似,称之为训练集,训练模型的时候是最小化模型在训练集上损失函数(经验风险)。
- 评估模型时,也是看模型在另外一个样本集(测试集)上的效果。
- 这种信息降维的特性,使得采样在数据可视化方面也有很多
应用,它可以帮助人们快速、直观地了解总体分布中数据的结构和特性。
- 对当前数据集重采样,可充分利用已有数据集,挖掘更多
信息,如自助法和刀切法( Jack knife),通过对样本多次重采样来估计统计量的偏差、方差等。
- 另外,利用重采样技术,可以在保持特定的信息下(目标信息不丢失),有意识地改变样本的分布,以更适应后续的模型训练和学习,例如利用重采样来处理分类模型的训练样本不均衡
- 模型结构复杂、含隐变量,导致对应的求解复杂,没解析解,难精确求解或推理。
- 可用采样方法随机模拟,对这些复杂模型近似求解或推理。
- 这一般会转化为某些函数在特定分布下的积分或期望,
- 或是求某些随机变量或参数在给定数据下的后验分布
- 在隐狄利克雷模型和深度玻尔兹曼机( Deep Boltzmann Machines,DBM)求解过程中,由于含隐变量,直接计算困难,此时可用吉布斯采样对隐变量的分布采样。
- 如果对于贝叶斯模型,还可将隐变量和参数变量放在一起,对它们的联合分布进行采样。
- 不同于一些确定性的近似求解方法(如变分贝叶斯方法、期望传播等)
- 基于采样的随机模拟方法是数值型的近似求解法。
总结与扩展
- 面试让大致说几种常见的应用,
- 如何用自助法或刀切法估计偏差、方差等;
- 隐狄利克雷模型和深度玻尔兹曼机怎么用吉布斯采样进行求解?
- 模型求解时,马尔可夫蒙特卡洛采样法
2 均匀分布随机数
场景描述
- 均匀分布:
- 样本空间是否连续
- 最简单的概率分布。
- 均匀分布中采样,即生成均匀分布随机数,
- 即使如此简单的分布,
如何编程实现均匀分布随机数生成器?
分析与解答
- 程序是确定性,不能产真正意义上的均匀分布随机数,
- 只能生伪随机数
- (这些数字虽通过确定性的程序产生的,但能通过近似的随机性测试)。
- 存储和计算单元只能处理离散值,也不能产生连续均匀分布随机数,
- 只能通过离散分布来逼近连续分布(用很大的离散空间来提供足够的精度)。
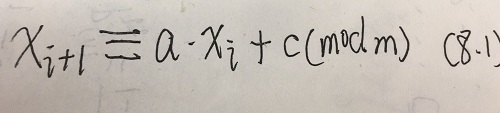
- 根据当前生成的
xi变換,产生下一次随机数
xi+1。
- 初始值
x0随机种子。
- 式(8.1)得到
[0,m−1]上的随机整数,
- 如想要得到区间
[0,1]上的连续均匀分布随机数,
- 除以
m即可。
- 线性同余法得到的随机数不相互独立
- (8.1)最多只产生
m个不同随机数,实际对于特定的种子,很多数无法取到,循环周期达不到
m
- 如果多次操作,得到的随机数会循环周期。
- 一个好的线性同余随机数生成器,要让其循环周期尽可能接近m,需要选择合适的乘法因子
a和模数
m(要用代数和群理论)。
- 具体实现有不同版本,如gcc采用的glibc版本

- 真正的随机数只会存在于自然界的物理现象中,比如放射性物质的衰变,温度、气流的随机扰动等。
- 一些网站可以提供基于大自然的随机现象的随机生成器,有兴趣的读者可以尝试一下。
- 图8.1通过大气噪声产生随机数,是“货真价实”的真随机数生成器
总结与扩展
- 面试官可能会针对线性同余法进行深入提问,
- 线性同余法中的随机种子一般如何选定?
- 如果需要产生高维样本或大量样本,线性同余法会存在什么问题?
- 如何证明上述线性同余发生器得到的序列可以近似为均匀分布(伪随机数)?
3 常见的采样方法
场景描述
- 对一个随变,用概率密度刻画该变量的概率分布特性。
- 给定随变的一取值,根据概率密度来计算该值对应的概率(密度)。
- 也可根据概率密度函数提供的概率分布信息来生成随机变量的一取值,这是采样。
- 采样是概率密度函数的逆向应用。
- 与根据概率密度函数计算样本点对应的概率值不同,
- 采样过程没那么直接,
- 通常需要根据待采样分布的具体特点来选择合适的采样策略。
问题
- 抛开那些针对特定分布而精心设计的采样方法,
- 说一些你知道的通用采样方法或采样策略,
- 描述它们主要思想及具体步骤
分析与解答
- 采样方法都以均匀分布随机数为基本
- 均匀分布随机数一般用线性同余法产生
- 设已生成[0,1]均匀分布随机数。
- 对简单分布,可直接用均匀采样的扩展方法来产样本点
- 不好直接采样,可函数变换法。
- 随机变量
x和
u存在变换关系
u=φ(x)
- 有
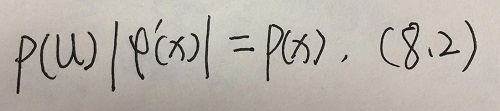
- 目标分布
p(x)中不好采样
x,
- 可构造变换
u=φ(x),
- 使变换后的分布
p(u)中采样较易
- 这样可通过先对
u采样然后通过反函数
x=φ−1(u)来间接得到
x。
- 高维空间随机向量,则
φ′(x)对应Jacobian行列
发布了447 篇原创文章 ·
获赞 249 ·
访问量 5万+
转载自blog.csdn.net/zhoutianzi12/article/details/103913305
