文章目录
Hadoop集群按照,HDFS跟MapReduce自带demo演示
Hadoop的由来
需要:数据爆炸增长时代,大数据时代,如何处理大量数据。需要Hadoop
解释:What Is Apache Hadoop? The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.(可靠,可伸缩,弹性分布式计算框架)
解决问题:
1. 海量数据的存储(HDFS) 这是个存储的集群
2. 海量数据的分析(MapReduce)
3. 资源管理调度(YARN 该框架在2.0版本后引入)这是个管理的集群
作者:Doug Cutting
受Google三篇论文的启发(GFS、MapReduce、BigTable)对应成功产品就是(HDFS、MapReduce、HBase)
注意:Hadoop 进行MapReduce的时候是将代码推送到 分节点上进行本地计算。网络传输只是结果。
Hadoop 干什么
应用范围:海量半结构化跟非结构化数据的一次存储多次读取分析, hadoop擅长日志分析,facebook就用Hive来进行日志分析,淘宝搜索中的自定义筛选也使用的Hive;利用Pig还可以做高级的数据处理,包括Twitter、LinkedIn 上用于发现您可能认识的人,可以实现类似Amazon.com的协同过滤的推荐效果。淘宝的商品推荐也是!在Yahoo!的40%的Hadoop作业是用pig运行的,包括垃圾邮件的识别和过滤,还有用户特征建模。(2012年8月25新更新,天猫的推荐系统是hive,少量尝试mahout!)
应用公司:Hadoop被公认是一套行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力。几乎所有主流厂商都围绕Hadoop开发工具、开源软件、商业化工具和技术服务。今年大型IT公司,如EMC、Microsoft、Intel、Teradata、Cisco都明显增加了Hadoop方面的投入
Hadoop在淘宝中的应用框架

Hadoop 生态系统
- 这一切是如何开始的—Web上庞大的数据!
- 使用Nutch抓取Web数据
- 要保存Web上庞大的数据——HDFS应运而生
- 如何使用这些庞大的数据?
- 采用Java或任何的流/管道语言构建MapReduce框架用于编码并进行分析
- 如何获取Web日志,点击流,Apache日志,服务器日志等非结构化数据——fuse,webdav, chukwa, flume, Scribe
- Hiho和sqoop将数据加载到HDFS中,关系型数据库也能够加入到Hadoop队伍中
- MapReduce编程需要的高级接口——Pig, Hive, Jaql
- 具有先进的UI报表功能的BI工具- Intellicus
- Map-Reduce处理过程使用的工作流工具及高级语言
- 监控、管理hadoop,运行jobs/hive,查看HDFS的高级视图—Hue, karmasphere, eclipse plugin, cacti, ganglia
- 支持框架—Avro (进行序列化), Zookeeper (用于协同)
- 更多高级接口——Mahout, Elastic map Reduce
- 同样可以进行OLTP——Hbase

Hadoop 版本
- Apache 官方版本(2.7.2)
- Cloudera 使用下载最多的版本,稳定,有商业支持,在Apache的基础上打上了一些patch。推荐使用。
- HDP(Hortonworks Data Platform) Hortonworks公司发行版本。
Hadoop 核心组件
- HDFS: Hadoop Distributed File System 分布式文件系统
- YARN: Yet Another Resource Negotiator 资源管理调度系统
- Mapreduce:分布式运算框架
海量数据的存储用HDFS
- 主从结构
主节点, namenode HA的引入
从节点,有很多个: datanode
- namenode负责:
接收用户操作请求
维护文件系统的目录结构
管理文件与block之间关系,block与datanode之间关系
- datanode负责:
存储文件
文件被分成block存储在磁盘上
为保证数据安全,文件会有多个副本
HDFS 流程图

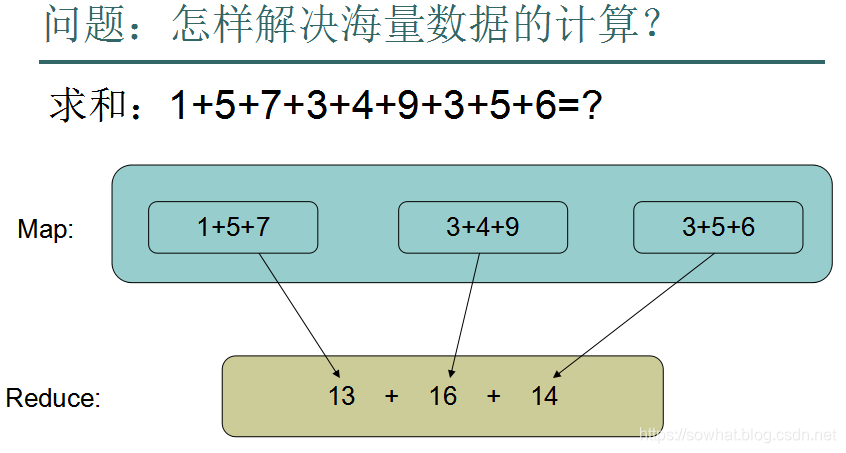
海量数据任务的分析MapReduce
形象图:
海量任务的调度 YARN
Hadoop 特点
- 扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据。
- 成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
- 高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行地(parallel)处理它们,这使得处理非常的快速。
- 可靠性(Reliable):hadoop能自动地维护数据的多份副本,并且在任务失败后能自动地重新部署(redeploy)计算任务。
Hadoop 1.0跟2.0差别

Hadoop 部署方式
- 本地模式
- 伪分布模式
- 集群模式
Hadoop 伪分布式搭建
参考 Hadoop-HA分布式搭建,本次视频教程是Windows下按照VMware 然后安装centos7 来安装的。所以开搞前要注意一下几点

- 网络设置
1.1 知道网卡、网关、交换机、路由器简单作用。
1.2 VMware网络配置
1.2 首先设定VMware的网络为NAT,设置好固定网关
1.3 VMware 会在Windows电脑上创建虚拟网卡
1.4 创建好的centos系统设置好 固定IP地址跟网关,
形象图如下

- centos设置
2.1 centos [修改主机名[(https://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_linux_043_hostname.html)
2.2 centos 设置固定IP
2.2 centos 主机名跟IP映射
2.3 centos 防火墙设置
- 安装JDK
- 安装Hadoop2.4.1
4.1 hadoop-env.sh
vim hadoop-env.sh
export JAVA_HOME=Java安装路径
4.2 core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://主机名:9000</value>
<!-- 这是 namenode 的URI 切记-- >
</property>
<!-- 指定hadoop运行时产生文件的存储目录,可以更细分 -->
<property>
<name>hadoop.tmp.dir</name>
<value>指定文件存储路径</value>
</property>
4.3 hdfs-site.xml
<!-- 指定HDFS副本的数量 ,由于是伪分布式 只有一个复本-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
4.4 mapred-site.xml (mv mapred-site.xml.template mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<!-- 指定 mr 运行在 yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
4.5 yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>主机名</value>
</property>
<!-- reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
4.6 格式化namenode(对namenode 进行初始化)
hdfs namenode -format (hadoop namenode -format)
4.7 启动 Hadoop
先启动HDFS: start-dfs.sh
再启动YARN: start-yarn.sh
4.8 验证是否启动成功
使用 jps 命令验证
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode
4.9 成功验证
http://主机名:50070 (HDFS管理界面)
http://主机名:8088 (MR管理界面)
5.0 大数据服务端口汇总
1、HDFS页面:50070
2、YARN的管理界面:8088
3、HistoryServer的管理界面:19888
4、Zookeeper的服务端口号:2181
5、Mysql的服务端口号:3306
6、Hive.server1=10000
7、Kafka的服务端口号:9092
8、azkaban界面:8443
9、Hbase界面:16010,60010
10、Spark的界面:8080
11、Spark的URL:7077
5.1 配置ssh免登陆
教程
5.2 安装好后 HDFS跟 MapReduce 测试
- hdfs 测试 Hadoop-shell
通过 http://主机名:50070 可查看数据,Utilities 栏查看分布式文件,同时可以操作 Hadoop shell指令
- MapReduce :Hadoop自带的一些jar包任务提交
/data/soft/hadoop-2.7.2/share/hadoop/mapreduce$ hadoop jar hadoop-mapreduce-examples-2.7.2.jar pi 5 5
hadoop jar app/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /input /output
PS:HDFS是 应用级的分布式文件存储服务,根据这个思想可以联想到网盘,我们看到的HDFS提供的什么 hdfs://cluster:9000/ljj/sowhat/file 这些都是虚拟的,由namenode来提供的,实际数据跟最终切片后数据的映射关系就由namenode来实现,延伸到如何实现控制别人存储文件的网盘大小等都是可以简单实现的。
当很多人传输跟存储相同一份文件的时候,系统会将最早的一份文件快捷方式存储到你的文件系统中,然后告知我们上传成功,这样不仅减少了公司的网盘空间,还速度极快。
同时再次记住一点 HDFS是一次写入多次读出,不支持随机性读取跟修改,并且Hadoop-shell 权限检查不严格。
常见的分布式文件系统
GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS等。各自适用于不同的领域。它们都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。
Google学术论文,这是众多分布式文件系统的起源
Google File System(大规模分散文件系统)
MapReduce (大规模分散FrameWork)
BigTable(大规模分散数据库)
Chubby(分散锁服务)
一般你搜索Google_三大论文中文版(Bigtable、 GFS、 Google MapReduce)就有了。
做个中文版下载源:http://dl.iteye.com/topics/download/38db9a29-3e17-3dce-bc93-df9286081126
做个原版地址链接:
http://labs.google.com/papers/gfs.html
http://labs.google.com/papers/bigtable.html
http://labs.google.com/papers/mapreduce.html
GFS(Google File System)
Google公司为了满足本公司需求而开发的基于Linux的专有分布式文件系统。。尽管Google公布了该系统的一些技术细节,但Google并没有将该系统的软件部分作为开源软件发布。
下面分布式文件系统都是类 GFS的产品。
HDFS
Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。 Hadoop是Apache Lucene创始人Doug Cutting开发的使用广泛的文本搜索库。它起源于Apache Nutch,后者是一个开源的网络搜索引擎,本身也是Luene项目的一部分。Aapche Hadoop架构是MapReduce算法的一种开源应用,是Google开创其帝国的重要基石。
Ceph
是加州大学圣克鲁兹分校的Sage weil攻读博士时开发的分布式文件系统。并使用Ceph完成了他的论文。
说 ceph 性能最高,C++编写的代码,支持Fuse,并且没有单点故障依赖, 于是下载安装, 由于 ceph 使用 btrfs 文件系统, 而btrfs 文件系统需要 Linux 2.6.34 以上的内核才支持。
可是ceph太不成熟了,它基于的btrfs本身就不成熟,它的官方网站上也明确指出不要把ceph用在生产环境中。
Lustre
Lustre是一个大规模的、安全可靠的,具备高可用性的集群文件系统,它是由SUN公司开发和维护的。
该项目主要的目的就是开发下一代的集群文件系统,可以支持超过10000个节点,数以PB的数据量存储系统。
目前Lustre已经运用在一些领域,例如HP SFS产品等。适合存储小文件、图片的分布文件系统研究
====================================
用于图片等小文件大规模存储的分布式文件系统调研
架构高性能海量图片服务器的技术要素
nginx性能改进一例(图片全部存入google的leveldb)
FastDFS分布文件系统
TFS(Taobao File System)安装方法
动态生成图片 Nginx + GraphicsMagick
MogileFS
由memcahed的开发公司danga一款perl开发的产品,目前国内使用mogielFS的有图片托管网站yupoo等。
MogileFS是一套高效的文件自动备份组件,由Six Apart开发,广泛应用在包括LiveJournal等web2.0站点上。
MogileFS由3个部分组成:
第1个部分是server端,包括mogilefsd和mogstored两个程序。前者即是 mogilefsd的tracker,它将一些全局信息保存在数据库里,例如站点domain,class,host等。后者即是存储节点(store node),它其实是个HTTP Daemon,默认侦听在7500端口,接受客户端的文件备份请求。在安装完后,要运行mogadm工具将所有的store node注册到mogilefsd的数据库里,mogilefsd会对这些节点进行管理和监控。
第2个部分是utils(工具集),主要是MogileFS的一些管理工具,例如mogadm等。
第3个部分是客户端API,目前只有Perl API(MogileFS.pm)、PHP,用这个模块可以编写客户端程序,实现文件的备份管理功能。
mooseFS
持FUSE,相对比较轻量级,对master服务器有单点依赖,用perl编写,性能相对较差,国内用的人比较多
MooseFS与MogileFS的性能测试对比
FastDFS
是一款类似Google FS的开源分布式文件系统,是纯C语言开发的。
FastDFS是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
官方论坛 http://bbs.chinaunix.net/forum-240-1.html
FastDfs google Code http://code.google.com/p/fastdfs/
分布式文件系统FastDFS架构剖析 http://www.programmer.com.cn/4380/
TFS
TFS(Taobao !FileSystem)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器 集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用 在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化 了文件的访问流程,一定程度上为TFS提供了良好的读写性能。
官网 : http://code.taobao.org/p/tfs/wiki/index/
GridFS文件系统
MongoDB是一种知名的NoSql数据库,GridFS是MongoDB的一个内置功能,它提供一组文件操作的API以利用MongoDB存储文件,GridFS的基本原理是将文件保存在两个Collection中,一个保存文件索引,一个保存文件内容,文件内容按一定大小分成若干块,每一块存在一个Document中,这种方法不仅提供了文件存储,还提供了对文件相关的一些附加属性(比如MD5值,文件名等等)的存储。文件在GridFS中会按4MB为单位进行分块存储。
MongoDB GridFS 数据读取效率 benchmark
http://blog.nosqlfan.com/html/730.html
nginx + gridfs 实现图片的分布式存储 安装(一年后出问题了)
http://www.cnblogs.com/zhangmiao-chp/archive/2011/05/05/2038285.html
基于MongoDB GridFS的图片存储
http://liut.cc/blog/2010/12/about-imsto_my-first-open-source-project.html
nginx+mongodb-gridfs+squid
http://1008305.blog.51cto.com/998305/885340
