hive启动之前要把mysql先启动到了。
要不然会报以下错误:
Caused by: java.net.ConnectException: 拒绝连接 (Connection refused)
启动完mysql 查看以下进程是否在:
[root@Tyler01 home]# ss -lntup
然后在启动hive:
[root@Tyler01 home]# hive
hive 的三种执行模式
第一种 hive -e “mysql的语句”。
例如
[root@Tyler01 ~]# hive -e "use default;create table test_1(id int,name string);"
第二种 hive -f a.hql(这个文件是已经编写好了mysql语句,直接执行就可)
[root@Tyler01 home]# vi userinfo.txt
1,xiaoming,20
2,xiaowang,22
[root@Tyler01 home]# vi a.hql
use default;
create table test_2(id int,name string,age int)
row format delimited #关键字,是用来设置创建的表在加载数据的时候,支持的列分隔符;
fields terminated by ','; #这里是按逗号分隔
load data local inpath '/home/userinfo.txt' into table test_2;
select count(*) from test_2;
执行:
[root@Tyler01 home]# hive -f a.hql
结果如下
OK
1 xiaoming 20
2 wahaha 22
Time taken: 3.098 seconds, Fetched: 2 row(s)
第三种
在/home/tyler/apps/hive/bin下有一个服务:hiveserver2
我们启动这个服务
这样这个服务启动完毕,光标停到下一行。在新开一个这个ip窗口。
我们在hadoop2上同样进入hive的bin目录
[root@Tyler01 bin]# ./beeline
Beeline version 1.2.1 by Apache Hive
beeline> !connect jdbc:hive2://Tyler02:10000
Connecting to jdbc:tyler://Tyler02:10000
Enter username for jdbc:tyler://Tyler02:10000: root
Enter password for jdbc:tyler://Tyler02:10000:
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hdp02:10000>
这样我们就链接到了hdp02的服务端了,我们可以在这输入一些hive的语句
0: jdbc:hive2://hdp02:10000> show databases;
0: jdbc:hive2://hdp02:10000> show tables;

这些命令都是发到hdp02上的服务端执行
可以看到hdp02的已经有“ok出现”
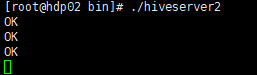
建表
- 表定义信息会被记录到hive的元数据中(mysql的 hive 库)。
- 会在 hdfs 上的 hive 库目录中创建一个跟表名一致的文件夹。

3. 往表目录中放入文件就有数据了。

我们看到test_1下并没有数据,此时我们进入到hive中
查看test_1表的描述信息
hive> desc test_1;
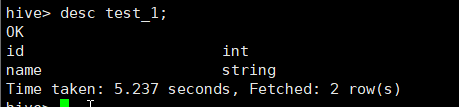
有两个字 段 id和 name。
在创建一个文件 , 写好后上传到hdfs对应的test_1表对应的目录下。
[root@Tyler03 ~]# vi test_1.txt
[root@Tyler03 ~]# hadoop fs -put test_1.txt /user/hive/warehouse/test_1

hive> select * from test_1;
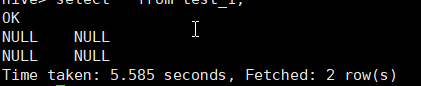
这是因为建表语句是:create table test_1(id string,name string,age int);并没有指定分隔符”,”
所以我们删掉这个表。
hive> drop table test_1;
OK
Time taken: 3.099 seconds
在重新创建个表。
hive> create table test_1(id string,name string,age int)
> row format delimited
> fields terminated by ',';
OK
Time taken: 0.702 seconds
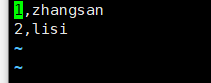
在将test_1文件 重新上传到hdfs对应的test_1目录下
再在hive中查看就有了。
hive> select * from test_1;
OK
1 zhangsan 23
2 lisi 12
Time taken: 0.579 seconds, Fetched: 2 row(s)
如果在test_1文件有的字段没有写,会写入NULL。
内部表和外部表(external)
内部表
创建一个表。
hive> create table t_2(id int,name string,salary bigint,add string)
row format delimited
fields terminated by ','
location '/aa/bb';
在salary.txt文件写入数据
[root@Tyler02 bin]# vi /home/salary.txt
[root@Tyler02 bin]# scp -r /home/salary.txt Tyler01:/home/ #hive在Tyler01上

hive> load data local inpath '/home/salary.txt' into table t_2;
hive> select * from t_2;
结果
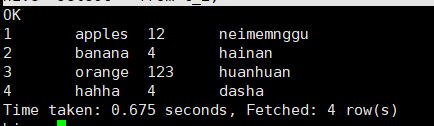
在hdfs中的文件如下;

删除表
hive> drop table t_2;
OK
Time taken: 0.906 seconds
在hdfs中的文件也会被删除。

外部表
首先创建表
hive> create external table t_3(id int,name string,salary bigint,add string)
> row format delimited
> fields terminated by ','
> location '/aa/bb';
OK
Time taken: 0.409 seconds
说明:location '/aa/bb’是hdfs的目录
将salary.txt文件上传到hdfs上。
[root@Tyler02 bin]# hadoop fs -put /home/salary.txt /aa/bb/
在hive中查看。
hive> select * from t_3;
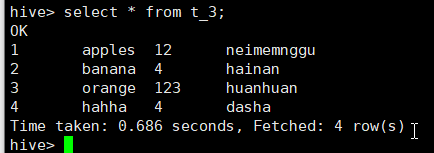
删除t_3表。
hive> select * from t_3;
在hdfs中查看。(数据并没有被删除)
