常用的Java集合有两部分组成Map与Collection
简介
- Collection
- Map
Collection
罗列一下常用的Collection的子类
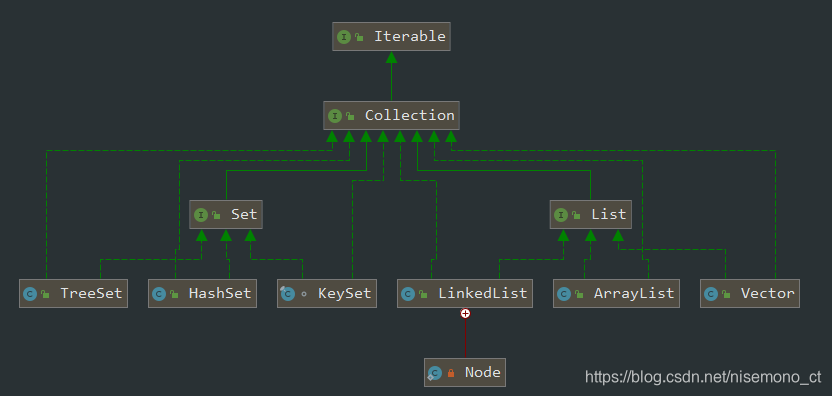
- Iterable
iterable中定义了一个iterator–迭代器
public interface Iterable<T> {
/**
* Returns an iterator over elements of type {@code T}.
*
* @return an Iterator.
*/
Iterator<T> iterator();
这也是为什么实现了Collection的方法都可以使用迭代器的方法进行遍历
有关iterator的方法
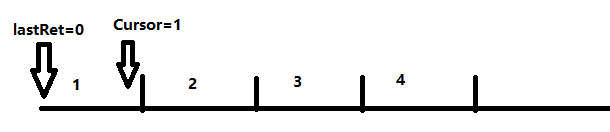
iterator的遍历操作实现原理
初始时cursor=0,lastRet=-1,每次取第elementData[cursor]的节点
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
- ArrayList
ArrayList在数据结构中也叫做顺序表
它是由数组构成的,JDK1.8中默认初始值大小为10
private static final int DEFAULT_CAPACITY = 10; //初始容量
transient Object[] elementData;
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
所以每次new关键字创建ArrayList时,容量为10
但是容量超过10就会出现elementData数组下标越界,这时候就需要创建一个新的数组,将旧的数据copy过去。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); //扩容后大小,每次算数右移,加上原来的长度,也就是1.5倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
可以看到,调用了Arrays工具类的copyOf方法扩容(copyOf扩容,本质上调用的还是System类中的arraycopy方法),当然每次扩容大小
System.arraycopy(original, 0, copy, 0,Math.min(original.length, newLength));
ArrayList大致的样子
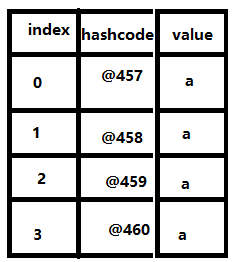
每个地址空间之间都是连续的,因为存在下标,所以查询的访问的时候快
3. LinkedList
linkedList在数据结构中也叫做链表,当然在Java中使用的是双向链表。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}//定义了一个私有的静态Node类
public LinkedList() {
} //初始化空参构造
public boolean add(E e) {
linkLast(e);
return true;
} //add扩容
void linkLast(E e) {
final Node<E> l = last; //last指向链表的最末尾
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null) //如果,链表中没有值,也就是最后一个节点为空
first = newNode; //就将链表首节点指向新增的节点
else
l.next = newNode; //否则,就让最末尾的节点指向新增节点
size++;
modCount++;
}
各个节点之间,地址空间可以不连续,因为只要找寻到对的下标,插入起来只用修改指针指向,所以增删快

- Vector
vector的实现原理与ArrayList差不多,不同的是Vector的很多方法添加了synchronized关键字,所以线程安全,但是因为使用的是synchronized关键字实现的,是以牺牲运行速度为代价换来的线程安全
protected Object[] elementData; //创建Vector容器
public Vector() {
this(10); //调用形参列表为int.class的构造方法
}
public Vector(int initialCapacity) {
this(initialCapacity, 0); //调用形参列表为int.class,int.class的构造方法
}
public Vector(int initialCapacity, int capacityIncrement) {
super(); //super()调用的是父类AbstractList的空参构造
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
Set的实现原理是基于HashMap的,具体实现原理放在Map中讨论
