原始数据:
LZi2ryWsShY!lovejoy71!433!People & Blogs!111!47234!4.94!65!32!9G3rVGW4JrI!UnfbKKvUG9Q!753jCzdr_4w!QwNb2WZu8hE!0KyD0ZA2RRY!T6_91j86v5I!yJDPn0sPgus!uz50jqNcHRw!cFQUvZD8X0w!kHkdIiadj7E!Y0cHBgzhc6k!ioyQi-rb1DM!ncOP-9pZD7c!FThqh3xmcfw!CuToVngYyzc!ZkR9jFGFijo!bqAMoOufevw!_sf_0ICtCDQ!b2L8Y9AIgBE!OnEMs6jlRfo
预处理之后的数据:
LZi2ryWsShY!lovejoy71!433!People&Blogs!111!47234!4.94!65!32!9G3rVGW4JrI&UnfbKKvUG9Q&753jCzdr_4w&QwNb2WZu8hE&0KyD0ZA2RRY&T6_91j86v5I&yJDPn0sPgus&uz50jqNcHRw&cFQUvZD8X0w&kHkdIiadj7E&Y0cHBgzhc6k&ioyQi-rb1DM&ncOP-9pZD7c&FThqh3xmcfw&CuToVngYyzc&ZkR9jFGFijo&bqAMoOufevw&_sf_0ICtCDQ&b2L8Y9AIgBE&OnEMs6jlRfo对原始数据进行预处理,格式为上面给出的预处理之后的示例数据通过观察原始数据形式,可以发现,数据中列与列的分隔符是“!”。视频可以有多个所属分类,每个所属分类用&符号分割,且分割的两边有空格字符,同时相关视频也是可以有多个,多个相关视频又用“!”进行分割。为了分析数据时方便对存在多个子元素的数据进行操作,
我们首先进行数据重组清洗操作。
即:将每条数据的“视频类别”用“&”分割,同时去掉两边空格,多个“相关视频id”也使用“&”进行分割
实现效果【截图】:
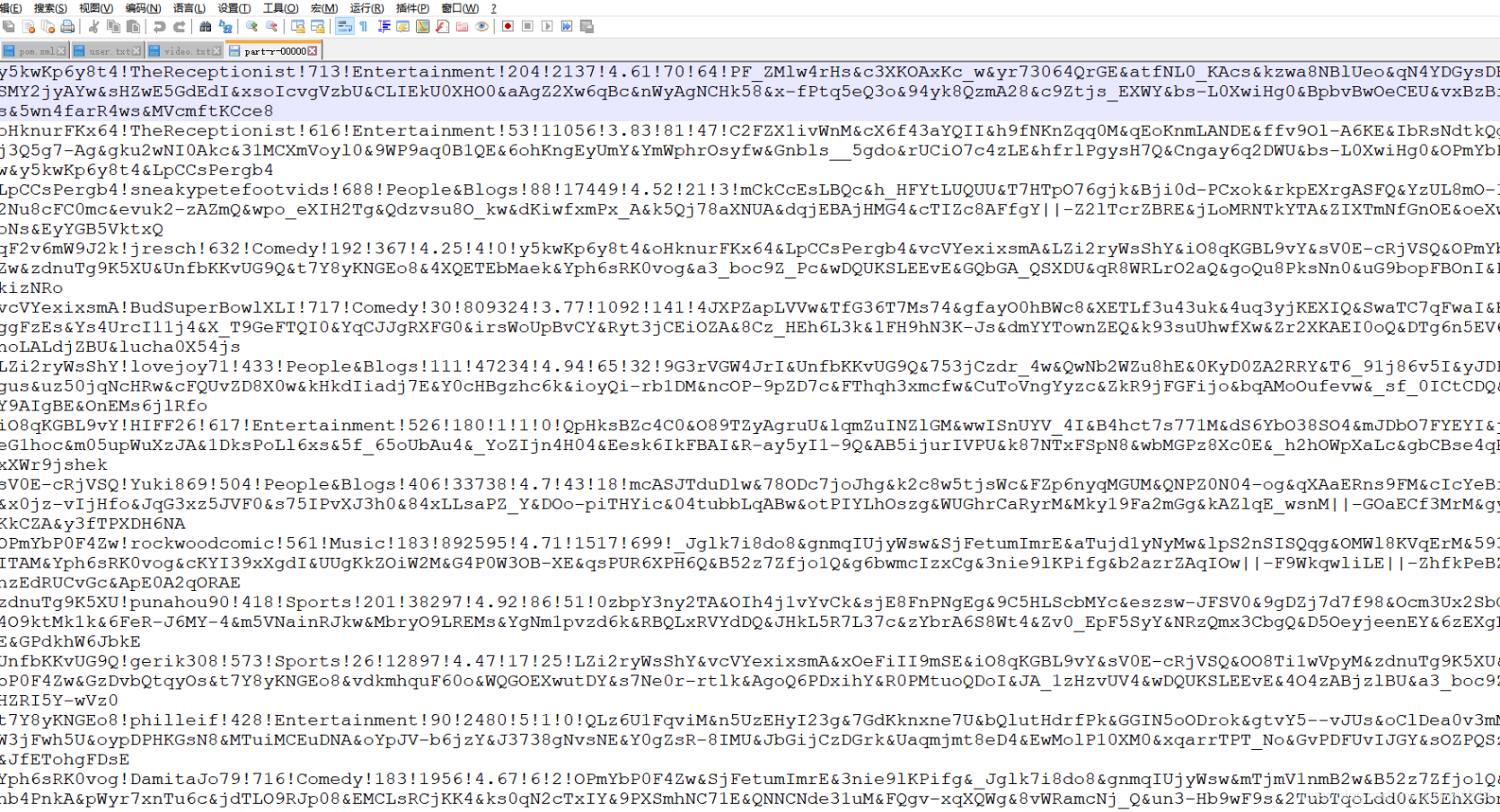
实现代码【截图】
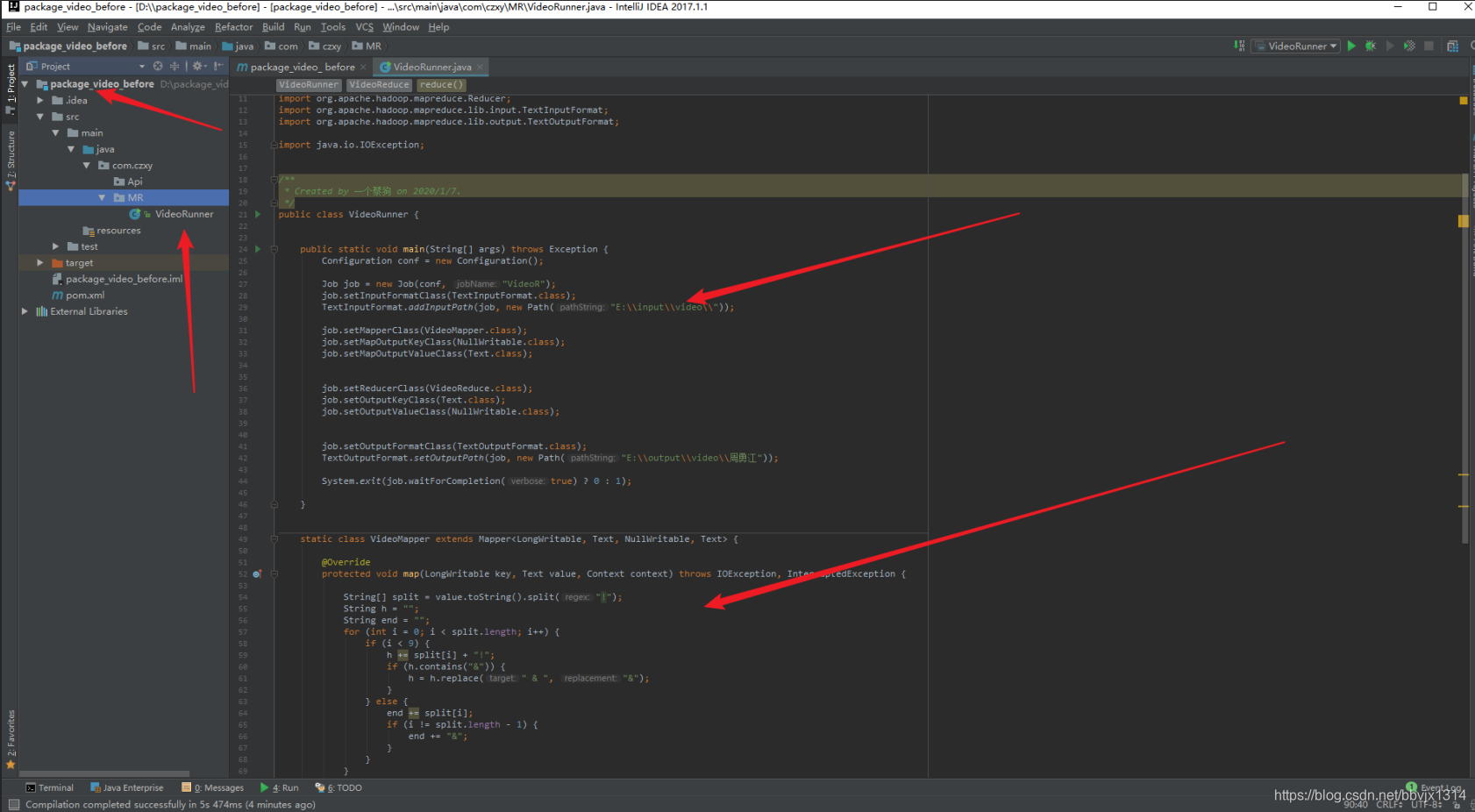
Map代码

这里Reduce 可以省略 不写(所以没有必要画蛇添足)
驱动代码

代码 :
package com.czxy.MR;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
/**
* Created by 一个蔡狗 on 2020/1/7.
*/
public class VideoRunner {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "VideoR");
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("E:\\input\\video\\"));
job.setMapperClass(VideoMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
// job.setReducerClass(VideoReduce.class);
// job.setOutputKeyClass(Text.class);
// job.setOutputValueClass(NullWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("E:\\output\\video"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
static class VideoMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("!");
String h = "";
String end = "";
for (int i = 0; i < split.length; i++) {
if (i < 9) {
h += split[i] + "!";
if (h.contains("&")) {
h = h.replace(" & ", "&");
}
} else {
end += split[i];
if (i != split.length - 1) {
end += "&";
}
}
}
//健壮性判断
if (end.equals("")){
end=null;
}
String t = h+end;
System.out.println(t);
context.write(NullWritable.get(),new Text(t));
}
}
// 可以省略不写
// static class VideoReduce extends Reducer<NullWritable, Text, Text, NullWritable> {
// @Override
// protected void reduce(NullWritable key, Iterable<Text> values, //Context context) throws IOException, InterruptedException {
// for (Text value : values) {
// context.write(value,NullWritable.get());
// }
// }
// }
}
把预处理之后的数据进行入库到hive中
数据的入库操作阶段
创建数据库和表 :
创建数据库名字为:video
create database video;
创建原始数据表:
视频表:douyinvideo_ori 用户表:douyinvideo_user_ori
创建ORC格式的表:
视频表:douyinvideo_orc 用户表:douyinvideo_user_orc
给出创建原始表语句
创建douyinvideo_ori视频表:
create table douyinvideo_ori(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited
fields terminated by "!"
collection items terminated by "&"
stored as textfile;
创建douyinvideo_user_ori用户表:
create table douyinvideo_user_ori(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by ","
stored as textfile;数据入库效果【截图】 :

 数据入库命令【命令】 :
数据入库命令【命令】 :
2.1
| -- 创建 douyinvideo_orc 表
|
2.2
| -- 请写出导入语句,将相应语句写入答题卡中: douyinvideo_ori:
|
2.3
| -- 2.3从原始表查询数据并插入对应的ORC表中 |
- 数据的分析阶段
3.1
| -- #! bin/bash hive -e " select douyinvideo_ori.*
|
3.2
| -- 3.2统计上传视频最多的用户前十名以及他们上传的视频流量在前20的视频,把查询结果保存到 /export/uploader.txt -- 脚本
#! bin/bash
|
- 数据保存到数据库阶段
建表语句
创建ratings外部表的语句:
| -- 4.1创建hive对应的数据库外部表 |
创建uploader外部表的语句:
| -- 请写出创建 uploader 外部表的语句,将相应语句写入答题卡中:
|
4.2
数据加载语句
| -- 4.2加载第3步的结果数据到外部表中
-- 请写出加载语句到 uploader 表中,将相应语句写入答题卡中
|
4.3
创建hive hbase映射表
| -- 创建hbase_ratings表并进行映射,请将相应语句写入答题卡中:
|
4
插入数据
| -- 请写出通过insert overwrite select,插入hbase_ratings表的语句,将相应语句写入答题卡中 |
| -- 请写出通过insert overwrite select,插入hbase_uploader表的语句,将相应语句写入答题卡中 insert overwrite table hbase_uploader select *from uploader; |
数据的查询显示阶段
1 代码【截图】:
请使用hbaseapi 对hbase_ratings表按照rowkey=1查询cf列族下面的videoId,ratings列的值
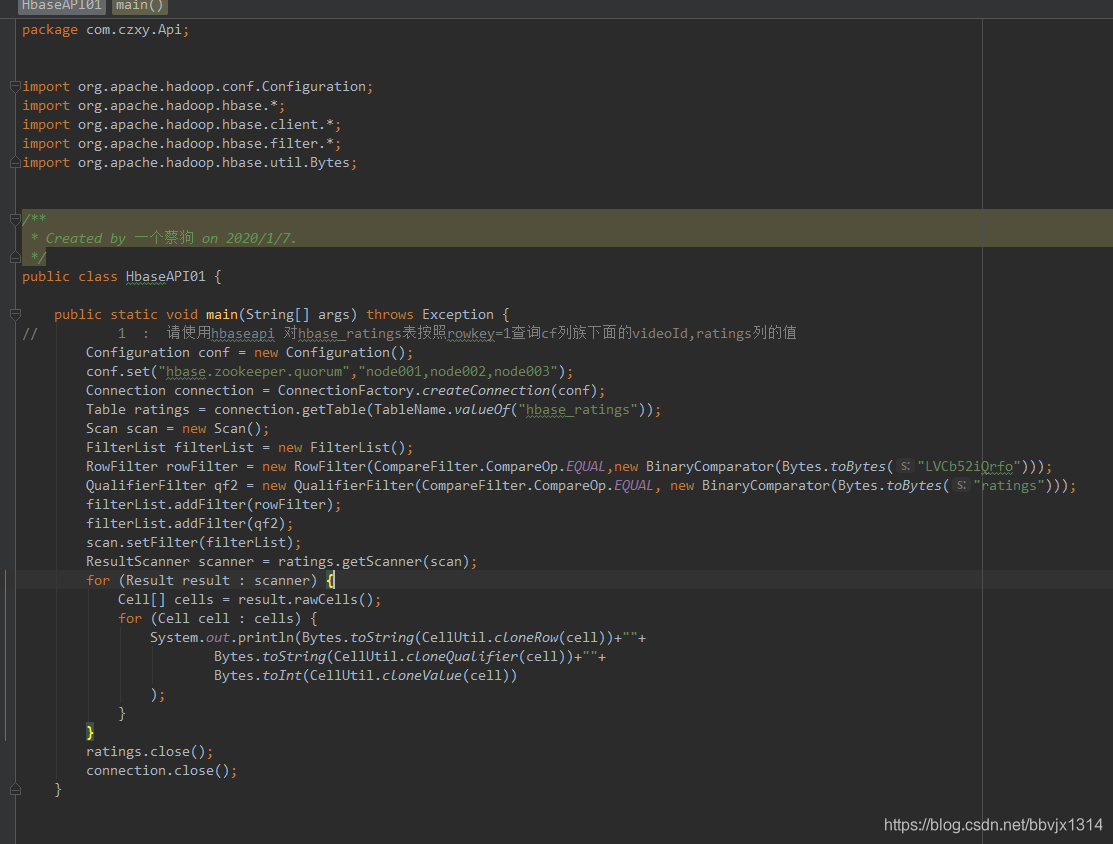
代码 :
package com.czxy.Api;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
/**
* Created by 一个蔡狗 on 2020/1/7.
*/
public class HbaseAPI01 {
public static void main(String[] args) throws Exception {
// 1 : 请使用hbaseapi 对hbase_ratings表按照rowkey=1查询cf列族下面的videoId,ratings列的值
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum","node001,node002,node003");
Connection connection = ConnectionFactory.createConnection(conf);
Table ratings = connection.getTable(TableName.valueOf("hbase_ratings"));
Scan scan = new Scan();
FilterList filterList = new FilterList();
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL,new BinaryComparator(Bytes.toBytes("LVCb52iQrfo")));
QualifierFilter qf2 = new QualifierFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("ratings")));
filterList.addFilter(rowFilter);
filterList.addFilter(qf2);
scan.setFilter(filterList);
ResultScanner scanner = ratings.getScanner(scan);
for (Result result : scanner) {
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+""+
Bytes.toString(CellUtil.cloneQualifier(cell))+""+
Bytes.toInt(CellUtil.cloneValue(cell))
);
}
}
ratings.close();
connection.close();
}
}
2 代码【截图】:
请使用hbaseapi 对hbase_uploader表通过RowFilter过滤比rowKey =MdNyOfjnETI小的所有值出来

代码 :
package com.czxy.Api;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
/**
* Created by 一个蔡狗 on 2020/1/7.
*/
public class HbaseAPI02 {
// 2 : 请使用hbaseapi 对hbase_uploader表通过RowFilter过滤比rowKey =MdNyOfjnETI小的所有值出来
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum","node001,node002,node003");
Connection connection = ConnectionFactory.createConnection(conf);
Table ratings = connection.getTable(TableName.valueOf("hbase_uploader"));
Scan scan = new Scan();
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.LESS,new BinaryComparator(Bytes.toBytes("MdNyOfjnETI")));
scan.setFilter(rowFilter);
ResultScanner scanner = ratings.getScanner(scan);
for (Result result : scanner) {
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+"_"+
Bytes.toString(CellUtil.cloneQualifier(cell))+"_"+
Bytes.toString(CellUtil.cloneValue(cell))
);
}
}
ratings.close();
connection.close();
}
}

