Spark on K8S(spark-on-kubernetes-operator)环境搭建以及demo过程
环境要求
Operator Version:最新即可
Kubernetes Version: 1.13或更高
Spark Version:2.4.4或以上,我用的是2.4.4
Operator image:最新即可
基本原理
Spark作为计算模型,搭配资源调度+存储服务即可发挥作用,一直用的是Yarn+HDFS,近期考虑尝试使用Spark+HDFS进行计算,因此本质上是对资源调度框架进行替换;
Yarn在资源调度的逻辑单位是Container,Container在资源管理上对比K8S存在一些不足,没有完全的做到计算任务的物理环境独立(例如python/java/TensorFlow等混部计算),在K8S上可用过容器实现相同物理资源的不同运行环境隔离,充分利用资源,简单来看两者的区别:
- job on pod VS job on container;
- 集中调度(api-server) VS 两级调度(ResourceManager/ApplicationMaster);
- 容器实现物理资源独立共享,计算环境隔离 VS Container实现物理资源独立共享(磁盘和网络IO除外),计算环境耦合
- I层弹性 VS none
用户角度看,两种提交任务的流程:
Spark on Yarn
spark-submit ---- ResourceManager ----- ApplicaitonMaster(Container) ---- Driver(Container)----Executor(Container)
PS:如果Cluster模式则Driver随机用一个Container启动;Client模式则会在提交方本地启动;
Spark on Kubernetes
spark-submit ---- Kube-api-server(Pod) ---- Kube-scheduler(Pod) ---- Driver(Pod) ---- Executor(Pod)
PS:和Deployment/Statefulset不同,Spark在调度执行时缺少自定义的controller,因此在集群中提交后看到的就是driver+executor的pod,没有deployment/statefulset等类似的controller管理;
本身在1.13的K8S版本也是直接可以submit的,为了方便用户使用,通过CRD(Custumer Resource Definition?),定义SparkApplication,用户可以直接在K8S上申请创建该资源对象,Spark的submit过程在该CRD内完成,我理解operator支持新CRD类型的作用不是很明显,但是可以支持了独立调度,也方便后续的开发和维护,所以尝试一下;
初步的了解可以参考如下两部分内容:
https://www.slidestalk.com/AliSpark/MicrosoftPowerPoint55236?video
http://www.sohu.com/a/343653335_315839
分享一篇调度的文章:
https://io-meter.com/2018/02/09/A-summary-of-designing-schedulers/
关于性能,有人也做过测试比对:
https://xiaoxubeii.github.io/articles/practice-of-spark-on-kubernetes/
官方的图画的比较明白了:
- submit过程拿出来,用sparkctl做
- 加了controller,支持了sparkApplication类型
- 调度抽出来由operator自己做
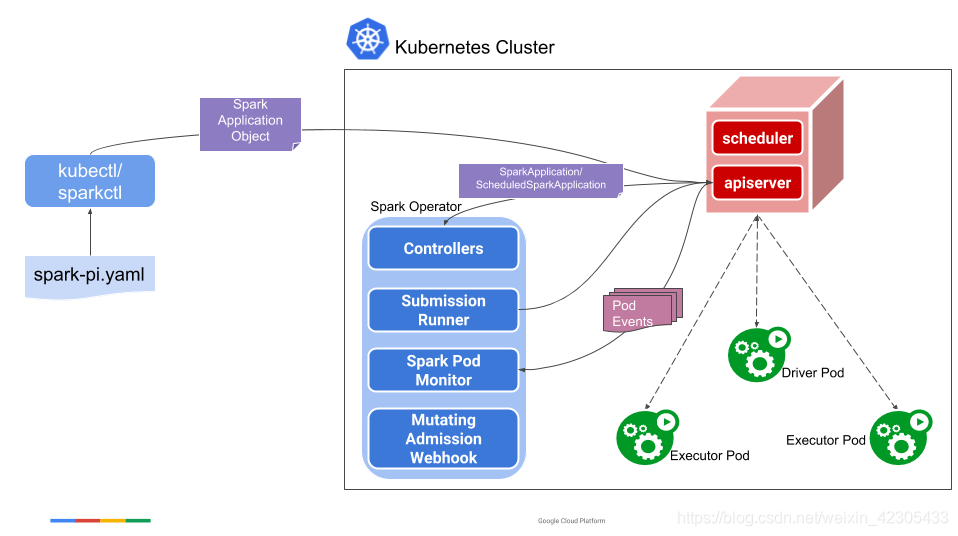 通过这种方式,我们的submit任务过程可以和部署一个deployment/statefulset一样简单,镜像+yaml,同时还可以使用comfigMap、secret、volume等K8S的资源,这样比自己submit,通过–conf或在镜像里固定写死要方便很多(当然Spark在3.0版本也增加了一些配置项,但归根结底还是要在submit过程或打镜像时来管理的)
通过这种方式,我们的submit任务过程可以和部署一个deployment/statefulset一样简单,镜像+yaml,同时还可以使用comfigMap、secret、volume等K8S的资源,这样比自己submit,通过–conf或在镜像里固定写死要方便很多(当然Spark在3.0版本也增加了一些配置项,但归根结底还是要在submit过程或打镜像时来管理的)
环境安装
kubernetes 1.13环境安装
得写一篇流水账,不单独写了,放在这里:
https://blog.csdn.net/weixin_42305433/article/details/103931032
https://blog.csdn.net/weixin_42305433/article/details/103931045
Spark-on-kubernetes-operator环境安装
也得写一篇流水账,不单独写了,放在这里:
https://blog.csdn.net/weixin_42305433/article/details/103930666
关于kerberos
完成环境基本的搭建后,如果在K8S集群中想将Spark任务日志持久化到HDFS上,可以配置:
"spark.eventLog.dir": "hdfs://10.120.16.127:25000/spark-test/spark-events"
此处如果Hadoop集群有kerberos认证机制,得需要单独处理,处理思路可以是:
- 在用户的Spark jar包中自己完成kerberos认证,kerberos的认证过程在hadoop源码中可以看到是一个类静态变量,因此进程共享,任意一次kerberos都可以在不同的configuration/sparkContext生效
- 通过Spark的参数配置实现kerberos的认证,无需用户代码
方法一:经过测试可以通过,只需要将kerberos认证的krb5.conf、user.keytab通过docker镜像ADD或configMap volumeMount挂载目录的方式放入容器即可,此处还需要验证一下,kerberos认证是否只在driver上生效,Executor上仍存在问题
方法二:查阅资料应该是不行,原因是kerberos认证本质是需要:
UserGroupInformation.loginUserFromKeytab(principal, keytabFile);
来完成登陆认证的,所以需要再spark-submit之后执行这行语句来完成登陆认证
Spark 2.4.4有如下说明(gitub官方)
Spark supports automatically creating new tokens for these applications when running in YARN mode.
Kerberos credentials need to be provided to the Spark application via the spark-submit command,
using the --principal and --keytab parameters.
因此,即便是修改/etc/spark/conf中的properties文件或修改sparkCondfigMap(本质一样),也没有办法实现,因为keytab的入参并不是由–conf参数来指定的;
Spark 3.0有如下说明(gitub官方)
When talking to Hadoop-based services behind Kerberos, it was noted that Spark needs to
obtain delegation tokens so that non-local processes can authenticate. These delegation
tokens in Kubernetes are stored in Secrets that are shared by the Driver and its Executors.
As such, there are three ways of submitting a Kerberos job:
1.Submitting with a $kinit that stores a TGT in the Local Ticket Cache:
/usr/bin/kinit -kt <keytab_file> <username>/<krb5 realm>
/opt/spark/bin/spark-submit \
--deploy-mode cluster \
--class org.apache.spark.examples.HdfsTest \
--master k8s://<KUBERNETES_MASTER_ENDPOINT> \
--conf spark.executor.instances=1 \
--conf spark.app.name=spark-hdfs \
--conf spark.kubernetes.container.image=spark:latest \
--conf spark.kubernetes.kerberos.krb5.path=/etc/krb5.conf \
local:///opt/spark/examples/jars/spark-examples_<VERSION>.jar \
<HDFS_FILE_LOCATION>
2.Submitting with a local Keytab and Principal
/opt/spark/bin/spark-submit \
--deploy-mode cluster \
--class org.apache.spark.examples.HdfsTest \
--master k8s://<KUBERNETES_MASTER_ENDPOINT> \
--conf spark.executor.instances=1 \
--conf spark.app.name=spark-hdfs \
--conf spark.kubernetes.container.image=spark:latest \
--conf spark.kerberos.keytab=<KEYTAB_FILE> \
--conf spark.kerberos.principal=<PRINCIPAL> \
--conf spark.kubernetes.kerberos.krb5.path=/etc/krb5.conf \
local:///opt/spark/examples/jars/spark-examples_<VERSION>.jar \
<HDFS_FILE_LOCATION>
3.Submitting with pre-populated secrets, that contain the Delegation Token, already existing within the namespace
/opt/spark/bin/spark-submit \
--deploy-mode cluster \
--class org.apache.spark.examples.HdfsTest \
--master k8s://<KUBERNETES_MASTER_ENDPOINT> \
--conf spark.executor.instances=1 \
--conf spark.app.name=spark-hdfs \
--conf spark.kubernetes.container.image=spark:latest \
--conf spark.kubernetes.kerberos.tokenSecret.name=<SECRET_TOKEN_NAME> \
--conf spark.kubernetes.kerberos.tokenSecret.itemKey=<SECRET_ITEM_KEY> \
--conf spark.kubernetes.kerberos.krb5.path=/etc/krb5.conf \
local:///opt/spark/examples/jars/spark-examples_<VERSION>.jar \
<HDFS_FILE_LOCATION>
如果升级到Spark3.0版本,可以通过Option2修改spark参数来指定对应krb5以及keytab文件来实现;可惜用的2.4.4版本,所以这种方式在当前环境下没办法用起来,只能考虑方式一来实现kerberos认证
