我们在之前的文章中 已经了解了 spark支持的模式,其中一种就是 使用k8s进行管理。
hadoop组件—spark----全面了解spark以及与hadoop的区别
spark on k8s的优势–为什么要把Spark部署在k8s上
大数据和云计算一直分属两个不同的领域。大数据主要关注怎么将数据集中起来,挖掘数据的价值;云计算主要关注怎么更高效地使用资源,提升资源的利用效率。当大数据发展到一定阶段的时候,它就会和云计算不期而遇。
两者的结合有以下优势:
1、技术栈的统一,降低运维成本
一般来说 每个公司 大数据的平台 和 云计算平台都是 不可缺少的。
也就意味着我们有两套体系的集群
一套是Hadoop+spark 或者 是商用的EMR。
一套是k8s,用于部署微服务和常规分析流程等应用。
两套集群意味着 比较复杂的管理成本,两套集群都分别要做好 安全和用户识别,以及 日志监控报警,后续的成本跟踪和优化等措施。
假如我们能把spark运行在k8s中,这样我们的 技术栈体系就会统一成 一套集群体系, 我们所有的安全,用户识别以及日志监控报警 以及 成本跟踪 都可以 使用k8s体系的。
集群的管理成本大大降低。
2、统一资源池,支持混合云,提高资源利用率
假如一共有100台服务器,我们分别有Spark的集群 和 K8s的集群,我们就需要考虑 每种集群分配多少台服务器。
比如Spark集群使用这50台,k8s使用另外50台,作为彼此的资源池。 这样我们有两个资源池,它们是不能共享的,当k8s的服务使用的机子数超过 50台时,不能去借用spark的机子,因为 它们运行在两套不同的资源管理体系中,强行使用同一节点可能会导致 业务受到影响。 同理,spark也不能借用k8s的机子。
如果两个集群的资源池不能复用,不同时期需要的算力是不固定的,存在波峰和波谷。
两种资源池就会存在闲置的情况造成资源浪费。
如果 我们使用 spark on k8s的模式,则 资源管理全部让k8s来进行, 那么 这100台机子都属于 k8s体系的资源池。我们就拥有了更好的伸缩能力。
k8s还有一个特点就是支持混合云和多云,可以摆脱固定某个运营商的绑定,因为容器的口号时"Build,Ship and Run any App,Angwhere",意味着 只要部署了k8s的云环境, 使用同样的容器镜像,可以在不同的linux系统甚至windows系统,阿里云,腾讯云,aws,或者自己搭建的私有云等等云环境中平滑的跑同样的业务。
对比Spark之前的独立集群和yarn等管理方式,Spark本身的设计更偏向使用静态的资源管理,虽然Spark也支持了类似Yarn等动态的资源管理器,但是这些资源管理并不是面向动态的云基础设施而设计的,在速度、成本、效率等领域缺乏解决方案。
YARN的Dynamic Resource Allocation(动态资源分配),主要实现在部分计算任务结束时就能提前释放资源,让给同一集群中的其它用户或者程序使用。主要实现的是spark集群的伸缩,但不能很好的适应 动态的服务器资源池。
因为yarn作为资源管理器的时候,spark在nodeManager启动任务执行器的时候,是需要jdk环境的。而一个动态的服务器资源,需要上去安装 需要的相关环境,有可能还没安装好,服务器就已经回收了。
举个例子,假如我们使用的 云供应商提供的 竞价实例等 会随时回收进行伸缩的 服务器资源,yarn资源管理是没有办法很好的去调控和解决这种快速的资源变化的,也就是 弹性不是很好。
而k8s的资源管理调度结合容器的特点,能很好的快速创建出 适配的环境,利用 云的特性进行 资源分配的。
yarn的资源管理是比较粗粒度的,一般是 node节点层级的,而k8s一般是同一个node会跑很多个pod,粒度更细,资源利用率会比较高。
通过 统一资源池,支持混合云,以及 细粒度的资源伸缩管理,k8s可以提高spark的资源利用率。
Spark on K8S面临的问题和调整
作为最为流行的大数据计算框架Apache Spark,与Kubernetes的集成是成为当前比较热门的话题,这个工作目前是有Google的工程师在力推。除了计算需求以外,大数据还会有大量的数据存储在HDFS之上,当Kubernetes可以轻易调度Apache Spark,为它提供一个安全可靠的运行隔离环境时,数据在多用户之间的安全性又变得非常棘手。
主要存在两个问题:
1、如何利用Kerboros这样的认证体系,打通HDFS和Spark的作业执行的权限控制
2、出于性能的考虑,在Spark的Executor Pod如何仍然保持数据本地性调度优化–本地文件依赖管理支持等。
具体细节可以参见示说网上的ppt文档: apache_spark_on_k8s_and_hdfs_security
Spark与k8s结合的发展历程
Spark本身的设计更偏向使用静态的资源管理,虽然Spark也支持了类似Yarn等动态的资源管理器,但是这些资源管理并不是面向动态的云基础设施而设计的,在速度、成本、效率等领域缺乏解决方案。
随着Kubernetes的快速发展,数据科学家们开始考虑是否可以用Kubernetes的弹性与面向云原生等特点与Spark进行结合。
在Spark 2.3中,Resource Manager中添加了Kubernetes原生的支持。
意味着 我们可以使用k8s对Spark进行管理了,而且能运用云的特性,很好的进行集群伸缩,降低我们的成本以及当运算资源不足时快速增加节点。
Spark on K8S(Spark On Kubernetes)
Spark 对 Kubernetes 的支持是从2.3版本开始的,Spark 2.4 得到提升,Spark 3.0 将会加入 Kerberos 以及资源动态分配的支持。
Spark 2.3提供了对Spark On Kubernetes特性的官方支持。
目前,Spark 2.4中Spark On Kubernetes特性又新增了对Pyspark和R的支持,以及对Client模式的支持。
Spark 3.0中对Spark On Kubernetes特性预计也将有重大改进。
其一,Spark将利用Dynamic Allocation Support特性实现资源的动态调整,比如根据集群负载动态地调整和伸缩集群规模,这同样会依赖于Remote Shuffle Storage特性。
Remote Shuffle Service:当前的 Shuffle 有很多问题,比如弹性差、对 NodeManager 有很大影响,不适应云环境。为了解决上面问题,将会引入 Remote Shuffle Service,具体参见 SPARK-25299
其二,Spark将支持对Kerberos的身份认证。
spark与k8s结合三种方式的区别与优劣
方式一 Spark Standalone on k8s
就是standalone的⽅式,把Kubernetes集群资源中得node节点当作一台服务器,把spark的环境打包到docke镜像中,在Kubernetes集群⾥⾯直接跑⼀套Spark的集群。这个方式没有官⽅⽂档参考。
这种方式只是把Spark集群部署搬到了Kubernetes,不⽀持Kubernetes原⽣资源调度,服务器集群节点交由Kubernetes管,Spark内部的任务调度还是 使用master/work或者 yarn来进行管理,并且是⼀直运⾏着Master和N份Worker等待应⽤的提交。
这种⽅式和服务器节点直接运⾏Spark集群⼏乎没什么⼤得区别,唯⼀⽅便的就是得⼒于Kubernetes的能⼒Worker可以很⽅便任意的伸缩。
提交应⽤⽅式也是通过spark-submit⽅式,和在服务器上部署集群提交⽅式⼀样。
主要问题是需要确认 master的访问链接和一些配置细节。
Spark Standalone on k8s有如下几个缺点:
1、无法对于多租户做隔离,每个用户都想给 pod 申请 node 节点可用的最大的资源。
2、Spark 的 master/worker 或者yarn本来不是设计成使用 kubernetes 的资源调度,这样会存在两层的资源调度问题,不利于与 kuberentes 集成。
这种模式是比较老的方式,目前基本不会考虑使用该模式,感兴趣得可以参考安装方式:
hadoop组件—spark实战----spark on k8s模式Spark Standalone on Docker方式安装spark
kubernetes中部署spark standalone集群–对应2019版本
方式二 Spark使用k8s原生调度
Spark使用k8s原生调度了解
Spark 2.3提供了对Spark On Kubernetes特性的官方支持,Resource Manager中添加了Kubernetes原生的支持。
也就是说 能够使用 原⽣kubernetes的调度⽅式。
这种方式目前是spark官方支持,肯定会越来越好用。
官⽅⽂档《Running Spark on Kubernetes2.3》;
该方式目前最新版本有以下特点:
1、支持 spark客户端和集群的发布
2、动态的资源伸缩
3、支持Java、Scala、PySpark、R等应用客户端
4、支持访问安全访问HDFS
5、可以在同一个k8s集群中跑多不同的spark版本,并进行快速切换spark版本
6、支持对CPU和内存做请求和限制
基本上能够替换yarn了,而且能得到若干额外的好处,例如多版本Spark同时运行。特别是支持secure HDFS,好评。
使用k8s原生调度的spark主要有以下好处:
采用k8s原生调度,不再需要二级调度,直接使用k8s原生的调度模块,实现与其他应用的混布;
资源隔离:任务可以提交到指定的namespace,这样可以复用k8s原生的qouta限制,实现任务资源的限制;
资源分配:可以指定每个spark任务的指定资源限制,任务之间更加隔离;
用户自定义:用户可以在spark基础镜像中打上自己的application, 更加灵活和方便;
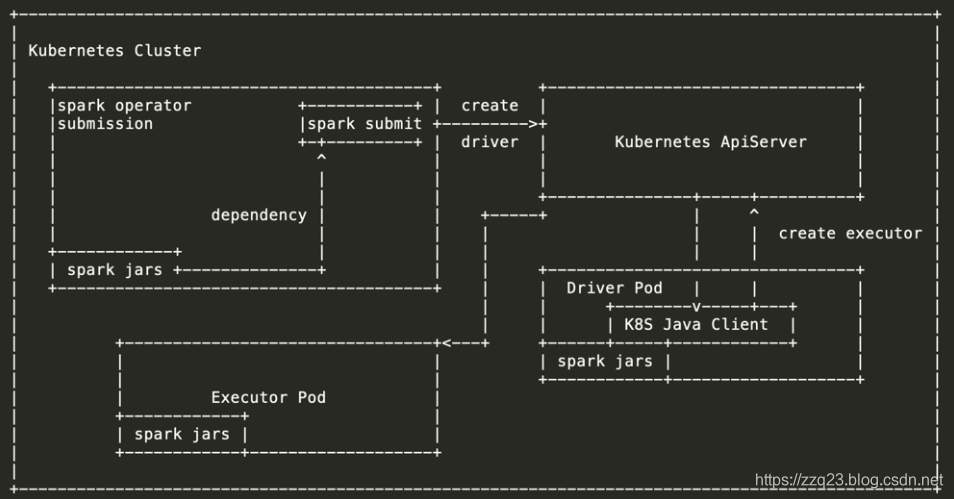
Spark使用k8s原生调度运行原理
该⽅式的调度就没有master、worker的概念了,通过spark submit提交应⽤程序到kubernetes直接启动的是driver和excutor。
具体启动实例的数量和要使⽤的资源根据配置⽽定。
并且在也不会在kubernetes集群中⼀直运⾏着spark的进程,⽽是每次提交应⽤的时候才启动driver和excutor。
当计算应⽤结束后excutor所在的pod⽴⻢被回收。
⽽driver会被留下供查看⽇志等并等待kubernetes⾃动回收策略回收或者⼈⼯⼲预删除pod。
使用kubernetes 原生调度的spark 的基本设计思路是将 spark 的 driver 和 executor 都放在 kubernetes 的 pod 中运行,另外还有两个附加的组件:ResourceStagingServer 和 KubernetesExternalShuffleService。
Spark driver其实可以运行在 kubernetes 集群内部(cluster mode)也可以运行在外部(client mode)。
executor 只能运行在集群内部。
当有 spark 作业提交到 kubernetes 集群上时
调度器后台将会为 executor pod 执行以下操作:
1、使用我们预先编译好的包含 kubernetes 支持的 spark 镜像,然后调用 CoarseGrainedExecutorBackend main class 启动 JVM。
2、调度器后台为 executor pod 的运行时注入环境变量,例如各种 JVM 参数,包括用户在 spark-submit时指定的那些参数。
3、Executor 的 CPU、内存限制根据这些注入的环境变量保存到应用程序的 SparkConf 中。
4、根据配置中指定 spark 参数运行在指定的 namespace 中。
Spark使用k8s原生调度区别
应⽤⽇志查看⽅式不再出现Spark Master UI⻚⾯,也没有History Server存储运⾏后的⽇志。
⽽且Driver UI只能在Driver运⾏期间才能查看,⼀旦Driver⽣命周期结束也就不能查看了。
但是我们可以通过Kubernetes来查看运⾏情况,⽐如通过kubectl logs driverpod-name或者通过Kubernetes Dashboard从界⾯去查看。
资源的分配直接交由kubernetes管理。
方式三 SparkOperator
SparkOperator了解
SparkOperator是由⾕歌发起维护的管理Spark应⽤程序⽣命周期的Kubernetes插件。官⽅⽂档《spark-on-k8s-operator》
这种方式是谷歌大厂支持的,基于k8s原生调度的方式做优化,使spark和k8s深度集成,目前用的公司也比较多,包括Uber和腾讯等,更多使用该方式的公司可参考Who Is Using the Kubernetes Operator for Apache Spark 。(推荐使用这种方式部署安装)
该⽅式需要在Kubernetes集群⾥⾯部署SparkOperator,用于⽀持像部署常规应⽤⼀样来部署Spark应⽤,这样我们就可以直接通过编写yaml⽂件来运⾏Spark应⽤,也不需要应⽤程序提交客户机上要有⽀持spark-submit的⽀持,只需要⼀个yaml⽂件。
除了安装上的优化,也优化了一些 可能会遇到的问题,比如 Pod 驱逐(Eviction)问题。
在 Kubernetes 中,资源分为可压缩资源(比如 CPU)和不可压缩资源(比如内存),当不可压缩资源不足的时候就会将一些 Pod 驱逐出当前 Node 节点。
国内某个大厂在使用 Spark on kubernetes 的时候就遇到因为磁盘 IO 不足导致 Spark 作业失败,从而间接导致整个测试集都没有跑出来结果。
如何保证 Spark 的作业 Pod (Driver/Executor) 不被驱逐呢?
这就涉及到优先级的问题,k8s 1.10 之后开始支持。但是说到优先级,有一个不可避免的问题就是如何设置我们的应用的优先级?常规来说,在线应用或者 long-running 应用优先级要高于 batch job,但是显然对于 Spark 作业来说这并不是一种好的方式。
而 spark-operator使用了增强型的资源调度工具volcano,比较好的解决了这方面的问题。
SparkOperator原理
Operator 在 Kubernetes 中是一个非常重要的里程碑。
我们知道 Kubernetes 给开发者提供了非常开放的一种生态,你可以自定义 CRD,Controller 甚至 Scheduler。而 Operator 就是 CRD + Controller 的组合形式。开发者可以定义自己的 CRD。
CRD–CustomResourceDefinition简介:
在 Kubernetes 中一切都可视为资源,Kubernetes 1.7 之后增加了对 CRD 自定义资源二次开发能力来扩展 Kubernetes API,通过 CRD 我们可以向 Kubernetes API 中增加新资源类型,而不需要修改 Kubernetes 源码来创建自定义的 API server,该功能大大提高了 Kubernetes 的扩展能力。
当你创建一个新的CustomResourceDefinition (CRD)时,Kubernetes API服务器将为你指定的每个版本创建一个新的RESTful资源路径,我们可以根据该api路径来创建一些我们自己定义的类型资源。
你可以在 github 的这个 repo:https://github.com/operator-framework/awesome-operators 中查看目前实现了 Operator 部署的分布式应用。
而SparkOperator就是谷歌发布的一个能够让spark更好的与k8s结合的 自定义资源类型和接口。
这个 Operator 涉及到的 CRD 如下:
|__ ScheduledSparkApplicationSpec
|__ SparkApplication
|__ ScheduledSparkApplicationStatus
|__ SparkApplication
|__ SparkApplicationSpec
|__ DriverSpec
|__ SparkPodSpec
|__ ExecutorSpec
|__ SparkPodSpec
|__ Dependencies
|__ MonitoringSpec
|__ PrometheusSpec
|__ SparkApplicationStatus
|__ DriverInfo
首先定义了两种不同的CRD对象,分别对应普通的计算任务与定时周期性的计算任务,然后解析CRD的配置文件,拼装成为spark-submit的命令,通过prometheus暴露监控数据采集接口,创建Service提供spark-ui的访问。然后通过监听Pod的状态,不断回写更新CRD对象,实现了spark作业任务的生命周期管理。
如果我要提交一个作业,那么我就可以定义如下一个 SparkApplication 的 yaml,关于 yaml 里面的字段含义,可以参考上面的 CRD 文档。
使用yaml的方式进行提交作业,而不再是使用spark-submit进行提交。
对比来看 Operator 的作业提交方式似乎显得更加的冗长复杂,但是这也是一种更 kubernetes 化的 api 部署方式,也就是 Declarative API,声明式 API。
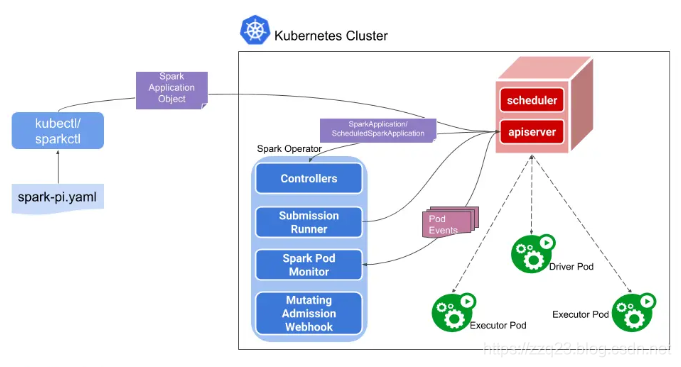
Spark Operator包括如下几个组件:
SparkApplication控制器, 该控制器用于创建、更新、删除SparkApplication对象,同时控制器还会监控相应的事件,执行相应的动作;
Submission Runner, 负责调用spark-submit提交Spark作业, 作业提交的流程完全复用Spark on K8s的模式;
Spark Pod Monitor, 监控Spark作业相关Pod的状态,并同步到控制器中;
Mutating Admission Webhook: 可选模块,基于注解来实现Driver/Executor Pod的一些定制化需求;
SparkCtl: 用于和Spark Operator交互的命令行工具
Spark Operator除了实现基本的作业提交外,还支持如下特性:
声明式的作业管理;
支持更新SparkApplication对象后自动重新提交作业;
支持可配置的重启策略;
支持失败重试;
集成prometheus, 可以收集和转发Spark应用级别的度量和Driver/Executor的度量到prometheus中.
SparkOperator工程结构
Spark Operator的项目是标准的K8s Operator结构, 其中最重要的包括:
manifest: 定义了Spark相关的CRD,包括:
ScheduledSparkApplication: 表示一个定时执行的Spark作业
SparkApplication: 表示一个Spark作业
pkg: 具体的Operator逻辑实现
api: 定义了Operator的多个版本的API
client: 用于对接的client-go SDK
controller: 自定义控制器的实现,包括:
ScheduledSparkApplication控制器
SparkApplication控制器
batchscheduler: 批处理调度器集成模块, 目前已经集成了K8s volcano调度器
spark-docker: spark docker 镜像
sparkctl: spark operator命令行工具
更多原理参考: Kubernetes Operator for Apache Spark Design
案例参考
参考链接:
https://yq.aliyun.com/articles/712297
