环境准备
1、使用spark2.3以上的spark版本
2、已经在运行的k8s集群版本需要大于1.6
使用命令查询
kubectl version
输出为:
zhangxiaofans-MacBook-Pro:Downloads joe$ kubectl version
Client Version: version.Info{Major:"1", Minor:"10", GitVersion:"v1.10.2", GitCommit:"456", GitTreeState:"clean", BuildDate:"2018-05-12T04:12:47Z", GoVersion:"go1.9.6", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"12", GitVersion:"v1.12.9", GitCommit:"123", GitTreeState:"clean", BuildDate:"2019-05-27T15:58:45Z", GoVersion:"go1.10.8", Compiler:"gc", Platform:"linux/amd64"}
3、拥有可以访问k8s集群的kubectl命令控制台
4、执行kubectl命令的用户需要有权限创建编辑和删除pod。
可以使用如下命令进行是否拥有权限的查询
kubectl auth can-i list pods
kubectl auth can-i create pods
kubectl auth can-i edit pods
kubectl auth can-i delete pods
结果输出如下:
zhangxiaofans-MacBook-Pro:Downloads joe$ kubectl auth can-i list pods
yes
zhangxiaofans-MacBook-Pro:Downloads joe$
ps: 不过我这里使用kubectl auth can-i edit pods命令返回的是no - no RBAC policy matched。
5、作为driver的pod使用的账户权限需要能够创建pod和service以及configmap。
下载官方编译好的包
进入到官网下载地址,选择我们需要的包
备用下载地址 http://mirror.bit.edu.cn/apache/spark/
也可以进行进行编译,不过需要mvn环境以及会去下载相关依赖的包可能会比较久。编译使用命令参考如下:
./build/mvn -Pkubernetes -Phadoop-2.7 -Dhadoop.version=2.7.3 -Phive -Phive-thriftserver -DskipTests cleanpackag
下载后放到一个新目录中解压使用命令:
mkdir spark
cd spark
tar -xzvf spark-2.4.4-bin-hadoop2.7.tgz
打包镜像
首先
$ docker login
登陆注册过的dockerhub账户
或者如果使用的是aws的仓库则使用如下命令进行登录
aws ecr get-login --no-include-email --region xxxxxxxxx
# 返回如下信息
docker login -u AWS -p 123
# copy 上面返回信息登录 docker
docker login -u AWS -p 123
#新镜像地址和名字使用如下命令创建
aws ecr create-repository --repository-name spark/xxxxx
aws创建repositoty返回如下:
zhangxiaofans-MacBook-Pro:bin joe$ aws ecr create-repository --repository-name spark
{
"repository": {
"registryId": "123",
"repositoryName": "spark",
"repositoryArn": "arn:aws-cn:ecr:cn-northwest-1:123:repository/spark",
"createdAt": 1579503767.0,
"repositoryUri": "123.dkr.ecr.cn-northwest-1.amazonaws.com.cn/spark"
}
}
方式一 使用官网提供的打包脚本命令
打包的命令在 官网下载到的包里就有。
然后在spark解压的目录下,打包和发布docker 镜像
cd ./spark-2.4.4-bin-hadoop2.7
./bin/docker-image-tool.sh -r <repo> -t my-tag build
./bin/docker-image-tool.sh -r <repo> -t my-tag push
这里 对应我们上面创建的镜像仓库地址,如123.dkr.ecr.cn-northwest-1.amazonaws.com.cn/spark
my-tag是一个标签名字,可以任意取,我们这里可以使用2.4.4,最好使用latest。因为后续使用的时候driver默认拉取latest。
build完毕后一共有三个镜像需要push上传,分别是
123.dkr.ecr.cn-northwest-1.amazonaws.com.cn/spark/spark
123.dkr.ecr.cn-northwest-1.amazonaws.com.cn/spark/spark-r
123.dkr.ecr.cn-northwest-1.amazonaws.com.cn/spark/spark-py
方式二 手动build上传
cd ./spark-2.4.4-bin-hadoop2.7
docker build -t <repo>/spark:2.4.4 -f kubernetes/dockerfiles/spark/Dockerfile .
docker push <repo>/spark:2.4.4
可能遇到的问题–Cannot find docker image. This script must be run from a runnable distribution of Apache Spark
这里说的是 没有找到dockerfile文件,这个脚本只能运行在 可运行的分布式 spark中。
需要检查解压的包里是否有 dockerfile文件,一般在spark-2.4.4-bin-hadoop2.7/kubernetes/dockerfiles/spark 。
如果确认有dockerfile文件,需要注意 运行docker-image-tool.sh脚本的目录层级,必须在spark-2.4.4-bin-hadoop2.7这层。
使用命令
cd ./spark-2.4.4-bin-hadoop2.7
./bin/docker-image-tool.sh -r <repo> -t my-tag build
不能使用命令
cd ./spark-2.4.4-bin-hadoop2.7/bin
./docker-image-tool.sh -r <repo> -t my-tag build
关于安装cluster mode
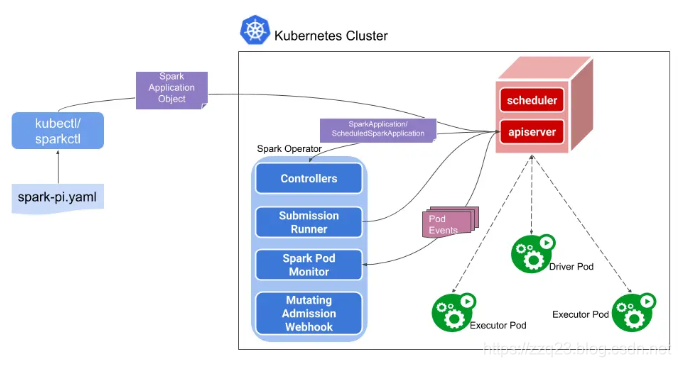
我们在之前的 原理解析中已经了解到 spark on k8s使用原生k8s的cluster mode方式,不会预先部署任何服务。而是 当 我们使用spark-submit进行提交任务给k8s时,k8s才会启动相同的pod作为 spark driver进行资源调配和启动更多pod。
只有 client mode模式的 才会提起部署一个 driver的pod作为常驻服务。
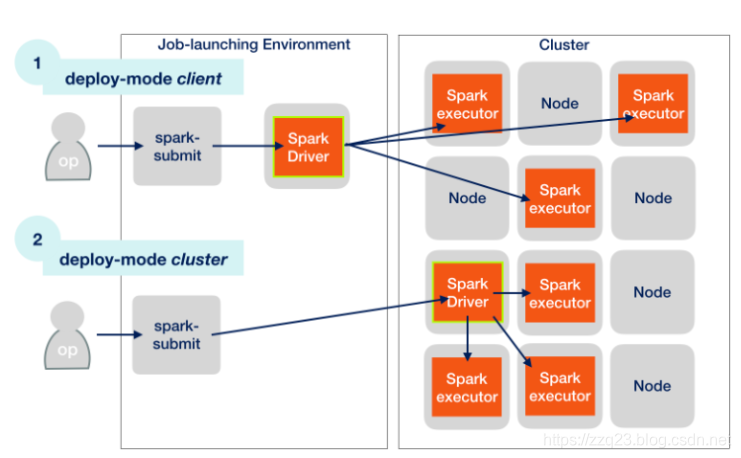
所以 如果是使用原生k8s — cluster mode的 spark on k8s,把镜像打包上传完毕后 就算安装完成了。
如何使用cluster-mode 和 client-mode的部署,我们在后续文章中进行记录。
