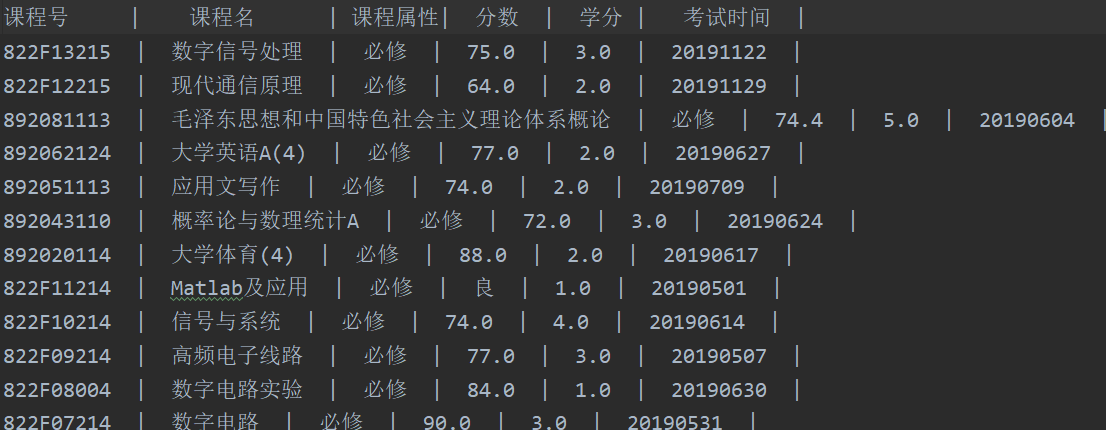
爬取URP班级课程表
1.首先通过抓包工具查看到返回来的是一个json类型
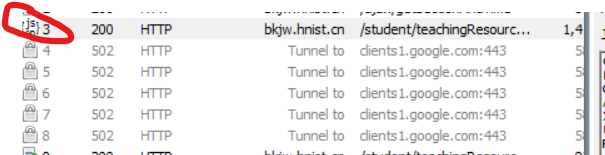
2.再继续查看可以了解到发送的是一个get请求,并且需要携带cookie才能访问
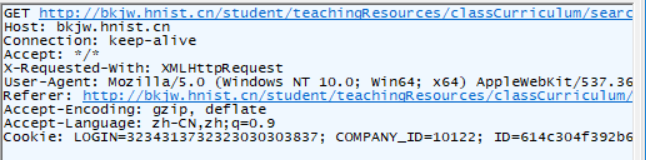
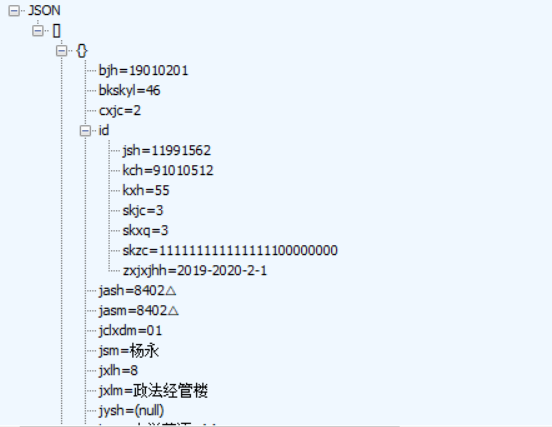
3.根据返回的json我们可以进行一些数据处理,从而得到想要的数据
扫描二维码关注公众号,回复:
8457350 查看本文章

1 import urllib.request 2 import urllib.parse 3 from bs4 import BeautifulSoup 4 5 url= 'http://bkjw.hnist.cn/student/integratedQuery/instructionPlanQuery/detail/index' 6 headers={ 7 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36', 8 9 10 'Cookie': 'LOGIN=3234313732323030303837; COMPANY_ID=10122; ID=30374a53626949763944633d; PASSWORD=6f2f4f6b4d68706c7459453d; SCREEN_NAME=594b7368595246717254325668325047744a357833673d3d; JSESSIONID=abcLf7J_SGjp060VtN-9w; selectionBar=1443377' 11 } 12 13 request = urllib.request.Request(url=url,headers=headers) 14 15 response = urllib.request.urlopen(request).read().decode() 16 17 # print(response.read().decode()) 18 soup =BeautifulSoup(response,'lxml') 19 20 table_list = soup.findAll('table') 21 22 23 file_name='course.txt' 24 file=open(file_name,'ab') 25 file.write(('课程号 | 课程名 | 课程属性| 分数 | 学分 | 考试时间 |\n\n').encode()) 26 27 for i in table_list: 28 for body in i.findAll('tbody'): 29 for tr in body.findAll('tr'): 30 for td in tr.findAll('td'): 31 temp_str=td.getText() 32 new_str=temp_str.strip() 33 # print(new_str,end=" ") 34 file.write((new_str+' | ').encode()) 35 file.write('\n'.encode())
这样就能得到自己的课程表以及成绩了