刚开始,肯定是安装python的环境了
从官网上下载
Python官网:https://www.python.org/
我选择的2.7的版本
安装完成后,需要配置环境变量
可以手动设置,也可以在控制台设置
手动:
C:\Python27\;%SystemRoot%\system3
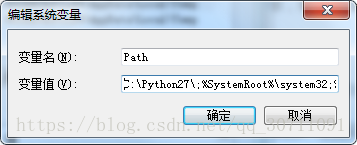
控制台:
path=%path%;C:\Python 在cmd中测试是否环境配好了,输入python就ok了
扫描二维码关注公众号,回复:
2514377 查看本文章

这些做完就可以运行.py的代码
但是为了方便开发,我还是下了个平台PyCharm
感觉用起来和android studio差不多
下面就可以写自己的代码了
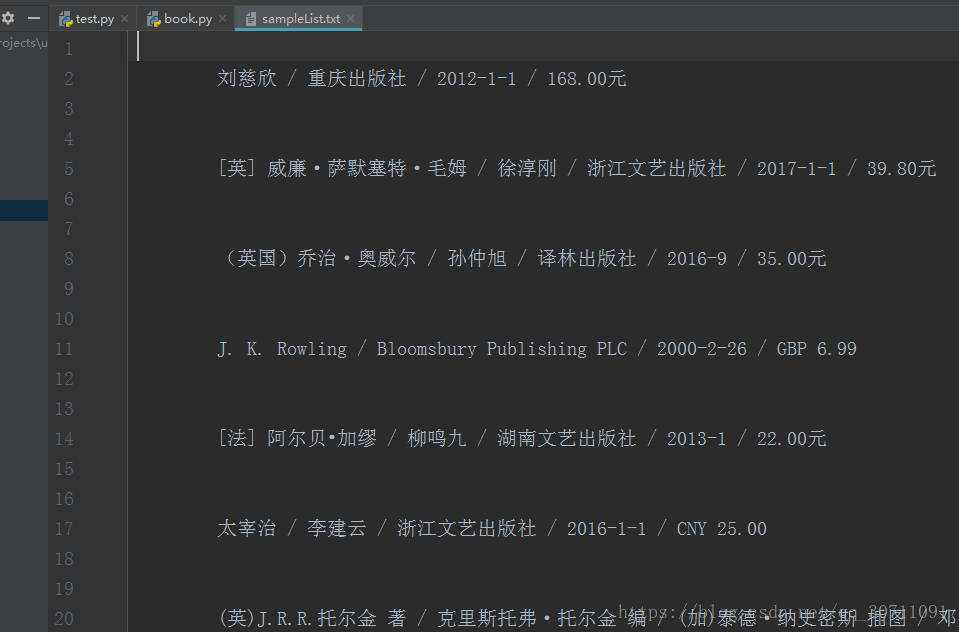
这个自己写的简单的爬虫代码,有的注释都写了
import urllib
from bs4 import BeautifulSoup
import codecs
res = urllib.urlopen("http://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/?focus=book");
soup = BeautifulSoup(res, "html.parser")
book_div = soup.find(attrs={"id": "book"})
#有class的时候
book_a = book_div.findAll(attrs={"class": "desc"})
#修改编码方式,否则write时会报can't encode错误
#正常fileObject = pen('sampleList.txt', 'w')
fileObject = codecs.open('sampleList.txt', 'w', encoding='utf-8')
for book in book_a:
print book.string
fileObject.write(book.string)
fileObject.write('\n')
fileObject.close()
res2 = urllib.urlopen("http://www.ld0769.com/#content")
soup2 = BeautifulSoup(res2, "html.parser")
#有id的时候
time_div = soup2.find(attrs={"id": "text-3"})
#只有标签的格式
time_a = time_div.findAll("a")
for time in time_a:
print time.string下面说一下,第一次写Python遇到的坑和难点
1.有些包因为没有翻墙,真的很难下载,一直报超时
网上有很多解决方法,我在这提供一种
pip --default-timeout=100 install -U 第三方库名(将超时的时间设置长一点)
2.在写入文件时一直报can't encode的错误,因为编码问题,网上百度了好多,都没解决
最后用res2 = urllib.urlopen("http://www.ld0769.com/#content")写入没有报错了