flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性、高吞吐、低延迟等优势,本文简述flink在windows和linux中安装步骤,和示例程序的运行,包括本地调试环境,集群环境。另外介绍Flink的开发工程的构建。
首先要想运行Flink,我们需要下载并解压Flink的二进制包,下载地址如下:https://flink.apache.org/downloads.html
我们可以选择Flink与Scala结合版本,这里我们选择最新的1.9版本Apache Flink 1.9.0 for Scala 2.12进行下载。
下载成功后,在windows系统中可以通过Windows的bat文件或者Cygwin来运行Flink。
在linux系统中分为单机,集群和Hadoop等多种情况。
通过Windows的bat文件运行
首先启动cmd命令行窗口,进入flink文件夹,运行bin目录下的start-cluster.bat
注意:运行flink需要java环境,请确保系统已经配置java环境变量。
$ cd flink
$ cd bin
$ start-cluster.bat
Starting a local cluster with one JobManager process and one TaskManager process.
You can terminate the processes via CTRL-C in the spawned shell windows.
Web interface by default on http://localhost:8081/.
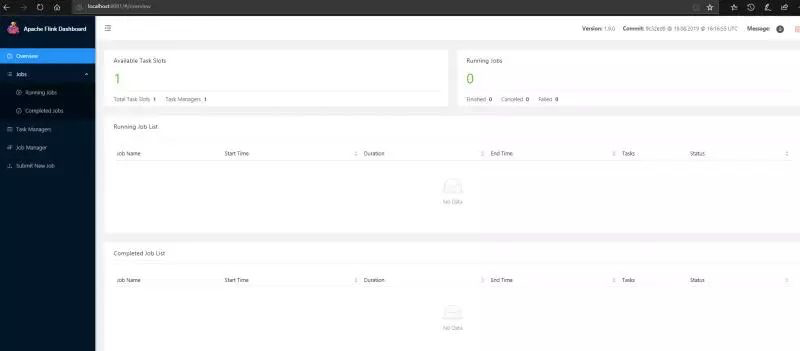
显示启动成功后,我们在浏览器访问 http://localhost:8081/可以看到flink的管理页面。
通过Cygwin运行
Cygwin是一个在windows平台上运行的类UNIX模拟环境,官网下载:http://cygwin.com/install.html
安装成功后,启动Cygwin终端,运行start-cluster.sh脚本。
$ cd flink
$ bin/start-cluster.sh
Starting cluster.
显示启动成功后,我们在浏览器访问 http://localhost:8081/可以看到flink的管理页面。
Linux系统上安装flink
单节点安装
在Linux上单节点安装方式与cygwin一样,下载Apache Flink 1.9.0 for Scala 2.12,然后解压后只需要启动start-cluster.sh。
集群安装
集群安装分为以下几步:
1、在每台机器上复制解压出来的flink目录。
2、选择一个作为master节点,然后修改所有机器conf/flink-conf.yaml
jobmanager.rpc.address = master主机名
3、修改conf/slaves,将所有work节点写入
work01
work02
4、在master上启动集群
bin/start-cluster.sh
安装在Hadoop
我们可以选择让Flink运行在Yarn集群上。
下载Flink for Hadoop的包
保证 HADOOP_HOME已经正确设置即可
启动 bin/yarn-session.sh
运行flink示例程序
批处理示例:
提交flink的批处理examples程序:
bin/flink run examples/batch/WordCount.jar
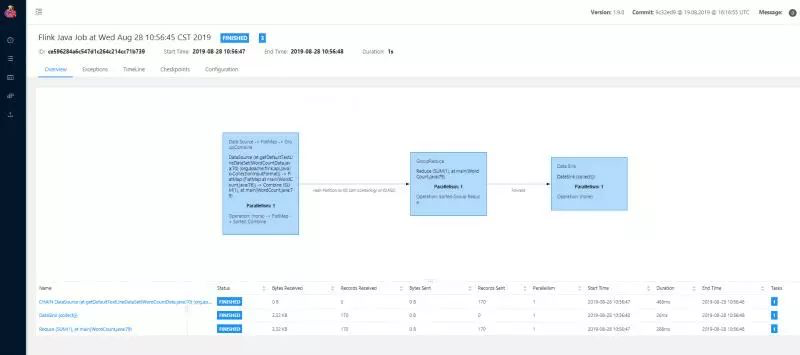
这是flink提供的examples下的批处理例子程序,统计单词个数。
$ bin/flink run examples/batch/WordCount.jar
Starting execution of program
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
(a,5)
(action,1)
(after,1)
(against,1)
(all,2)
(and,12)
(arms,1)
(arrows,1)
(awry,1)
(ay,1)
得到结果,这里统计的是默认的数据集,可以通过--input --output指定输入输出。
我们可以在页面中查看运行的情况:
流处理示例:
启动nc服务器:
nc -l 9000
提交flink的批处理examples程序:
bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000
这是flink提供的examples下的流处理例子程序,接收socket数据传入,统计单词个数。
在nc端写入单词
$ nc -l 9000
lorem ipsum
ipsum ipsum ipsum
bye
输出在日志中
$ tail -f log/flink--taskexecutor-.out
lorem : 1
bye : 1
ipsum : 4
停止flink
$ ./bin/stop-cluster.sh
在安装好Flink以后,只要快速构建Flink工程,并完成相关代码开发,就可以轻松入手Flink。
构建工具
Flink项目可以使用不同的构建工具进行构建。为了能够快速入门,Flink 为以下构建工具提供了项目模版:
Maven
Gradle
这些模版可以帮助你搭建项目结构并创建初始构建文件。
Maven
环境要求
唯一的要求是使用 Maven 3.0.4 (或更高版本)和安装 Java 8.x。
创建项目
使用以下命令之一来 创建项目:
使用Maven archetypes
$ mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.9.0
运行quickstart脚本
curl https://flink.apache.org/q/quickstart.sh | bash -s 1.9.0
下载完成后,查看项目目录结构:
tree quickstart/
quickstart/
├── pom.xml
└── src
└── main
├── java
│ └── org
│ └── myorg
│ └── quickstart
│ ├── BatchJob.java
│ └── StreamingJob.java
└── resources
└── log4j.properties
示例项目是一个 Maven project,它包含了两个类:StreamingJob 和 BatchJob 分别是 DataStream and DataSet 程序的基础骨架程序。 main 方法是程序的入口,既可用于IDE测试/执行,也可用于部署。
我们建议你将 此项目导入IDE 来开发和测试它。IntelliJ IDEA 支持 Maven 项目开箱即用。如果你使用的是 Eclipse,使用m2e 插件 可以 导入 Maven 项目。一些 Eclipse 捆绑包默认包含该插件,其他情况需要你手动安装。
请注意:对 Flink 来说,默认的 JVM 堆内存可能太小,你应当手动增加堆内存。在 Eclipse 中,选择 Run Configurations -> Arguments 并在 VM Arguments 对应的输入框中写入:-Xmx800m。在 IntelliJ IDEA 中,推荐从菜单 Help | Edit Custom VM Options 来修改 JVM 选项。
构建项目
如果你想要 构建/打包你的项目,请在项目目录下运行 ‘mvn clean package’ 命令。命令执行后,你将 找到一个JAR文件,里面包含了你的应用程序,以及已作为依赖项添加到应用程序的连接器和库:target/-.jar。
注意: 如果你使用其他类而不是 StreamingJob 作为应用程序的主类/入口,我们建议你相应地修改 pom.xml 文件中的 mainClass 配置。这样,Flink 可以从 JAR 文件运行应用程序,而无需另外指定主类。
Gradle
环境要求
唯一的要求是使用 Gradle 3.x (或更高版本) 和安装 Java 8.x 。
创建项目
使用以下命令之一来 创建项目:
Gradle示例:
build.gradle
buildscript {
repositories {
jcenter() // this applies only to the Gradle 'Shadow' plugin
}
dependencies {
classpath 'com.github.jengelman.gradle.plugins:shadow:2.0.4'
}
}
plugins {
id 'java'
id 'application'
// shadow plugin to produce fat JARs
id 'com.github.johnrengelman.shadow' version '2.0.4'
}
// artifact properties
group = 'org.myorg.quickstart'
version = '0.1-SNAPSHOT'
mainClassName = 'org.myorg.quickstart.StreamingJob'
description = """Flink Quickstart Job"""
ext {
javaVersion = '1.8'
flinkVersion = '1.9.0'
scalaBinaryVersion = '2.11'
slf4jVersion = '1.7.7'
log4jVersion = '1.2.17'
}
sourceCompatibility = javaVersion
targetCompatibility = javaVersion
tasks.withType(JavaCompile) {
options.encoding = 'UTF-8'
}
applicationDefaultJvmArgs = ["-Dlog4j.configuration=log4j.properties"]
task wrapper(type: Wrapper) {
gradleVersion = '3.1'
}
// declare where to find the dependencies of your project
repositories {
mavenCentral()
maven { url "https://repository.apache.org/content/repositories/snapshots/" }
}
// 注意:我们不能使用 "compileOnly" 或者 "shadow" 配置,这会使我们无法在 IDE 中或通过使用 "gradle run" 命令运行代码。
// 我们也不能从 shadowJar 中排除传递依赖(请查看 https://github.com/johnrengelman/shadow/issues/159)。
// -> 显式定义我们想要包含在 "flinkShadowJar" 配置中的类库!
configurations {
flinkShadowJar // dependencies which go into the shadowJar
// 总是排除这些依赖(也来自传递依赖),因为 Flink 会提供这些依赖。
flinkShadowJar.exclude group: 'org.apache.flink', module: 'force-shading'
flinkShadowJar.exclude group: 'com.google.code.findbugs', module: 'jsr305'
flinkShadowJar.exclude group: 'org.slf4j'
flinkShadowJar.exclude group: 'log4j'}
// declare the dependencies for your production and test code
dependencies {
// --------------------------------------------------------------
// 编译时依赖不应该包含在 shadow jar 中,
// 这些依赖会在 Flink 的 lib 目录中提供。
// --------------------------------------------------------------
compile "org.apache.flink:flink-java:\({flinkVersion}" compile "org.apache.flink:flink-streaming-java_\){scalaBinaryVersion}:${flinkVersion}"
// --------------------------------------------------------------
// 应该包含在 shadow jar 中的依赖,例如:连接器。
// 它们必须在 flinkShadowJar 的配置中!
// --------------------------------------------------------------
//flinkShadowJar "org.apache.flink:flink-connector-kafka-0.11_${scalaBinaryVersion}:${flinkVersion}"
compile "log4j:log4j:${log4jVersion}"
compile "org.slf4j:slf4j-log4j12:${slf4jVersion}"
// Add test dependencies here.
// testCompile "junit:junit:4.12"}
// make compileOnly dependencies available for tests:
sourceSets {
main.compileClasspath += configurations.flinkShadowJar
main.runtimeClasspath += configurations.flinkShadowJar
test.compileClasspath += configurations.flinkShadowJar
test.runtimeClasspath += configurations.flinkShadowJar
javadoc.classpath += configurations.flinkShadowJar}
run.classpath = sourceSets.main.runtimeClasspath
jar {
manifest {
attributes 'Built-By': System.getProperty('user.name'),
'Build-Jdk': System.getProperty('java.version')
}
}
shadowJar {
configurations = [project.configurations.flinkShadowJar]
}
setting.gradle
rootProject.name = 'quickstart'
或者运行quickstart脚本
bash -c "$(curl https://flink.apache.org/q/gradle-quickstart.sh)" -- 1.9.0 2.11查看目录结构:
tree quickstart/
quickstart/
├── README
├── build.gradle
├── settings.gradle
└── src
└── main
├── java
│ └── org
│ └── myorg
│ └── quickstart
│ ├── BatchJob.java
│ └── StreamingJob.java
└── resources
└── log4j.properties
示例项目是一个 Gradle 项目,它包含了两个类:StreamingJob 和 BatchJob 是 DataStream 和 DataSet 程序的基础骨架程序。main 方法是程序的入口,即可用于IDE测试/执行,也可用于部署。
我们建议你将 此项目导入你的 IDE 来开发和测试它。IntelliJ IDEA 在安装 Gradle 插件后支持 Gradle 项目。Eclipse 则通过 Eclipse Buildship 插件支持 Gradle 项目(鉴于 shadow 插件对 Gradle 版本有要求,请确保在导入向导的最后一步指定 Gradle 版本 >= 3.0)。你也可以使用 Gradle’s IDE integration 从 Gradle 创建项目文件。
构建项目
如果你想要 构建/打包项目,请在项目目录下运行 ‘gradle clean shadowJar’ 命令。命令执行后,你将 找到一个 JAR 文件,里面包含了你的应用程序,以及已作为依赖项添加到应用程序的连接器和库:build/libs/--all.jar。
注意: 如果你使用其他类而不是 StreamingJob 作为应用程序的主类/入口,我们建议你相应地修改 build.gradle 文件中的 mainClassName 配置。这样,Flink 可以从 JAR 文件运行应用程序,而无需另外指定主类。
声明:本号所有文章除特殊注明,都为原创,公众号读者拥有优先阅读权,未经作者本人允许不得转载,否则追究侵权责任。
关注我的公众号,后台回复【JAVAPDF】获取200页面试题!
5万人关注的大数据成神之路,不来了解一下吗?
5万人关注的大数据成神之路,真的不来了解一下吗?
5万人关注的大数据成神之路,确定真的不来了解一下吗?