urllib为python内置的HTTP请求库,包含四个模块:
-
request:最基本的HTTP请求模块, 只需要传入URL和参数
-
error:异常处理模块
-
parse:工具模块,处理URL,拆分、解析合并等
-
robotparser:识别robots.txt文件
1. urlopen()
实现最基本的请求发起,urlopen(url, data=None, [timeout,]*,cafile=None,capath=None,cadefault=False,context=None)
代码:

输出:
<class 'http.client.HTTPResponse'>
response为HTTPRsponse对象:
方法包含:read(),readinto(),getheader(name),getheaders(),fileno()
属性包含:msg,version,status,reason,debuglevel、closed
.data参数
如果不加参数为GET请求,加参数则为POST请求,参数需要先转化为bytes类型
代码:
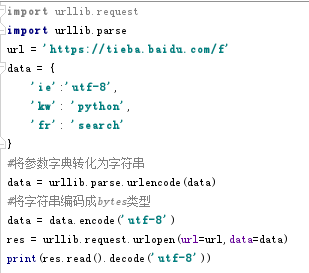
.timeout参数
设置超时时间,单位为秒,如果请求在设置时间内没有响应,就会抛出异常,默认为全局时间
.其他参数
cafile和capath指定CA证书和路径,context必须是ssl.SSLContext类型,用来指定SSL设置
2. Request
urlopen()只能发起简单的请求,Request可以构建完整的请求信息,然后将Request对象传递给urlopen
Request(url, data=None, headers={},origin_req_host=None, unverifiable=False,method=None)
参数:
- url:必填,其余为选填
- data:同上
- headers:是一个字典,请求头,可以用req.add_headers()方法添加
- origin_req_host:请求方的主机名称或ip地址
- unverifiable:请求是否是无法验证的,默认False
- method:请求方法,GET,POST,PUT等
代码:

3.高级用法Handler
处理更高级的操作,如Cookies,代理,登录验证等。Handler是urllib.request的类
思路:用Handler类构建一个handler------通过build_opener()方法和handle构造一个opener------通过opener的open()方法发送请求
- 案例---构造普通的handler

踩坑:
1.新建python文件时命名为urllib,导包报错---py文件名不能用库和关键字名称命名;