随着云计算大数据技术的日益普及,分布式技术快速发展,微服务大行其道,业务系统之间的调用层次越来越深,调用关系日益复杂。当业务系统出现故障时,如何从错综复杂的调用关系中快速分析问题,准确定位引起故障的根因点,并通过自动运维实现系统自愈,是智能运维重点关注的问题。根因分析作为智能运维的重点和难点,是学术界及工业界一直在探索的运维课题,除了见诸报道的特定场景下的少数案例,鲜有实质性突破,真正要攻克这个难关,还有很长的路要走。
特来电新能源有限公司(以下简称“特来电”)作为国内充电生态行业的领军企业,在业务快速发展过程中积累了海量监控数据,针对线上运维故障,同样面临根因分析的痛点问题。特来电云平台SRE人员紧跟AIOps发展趋势,将机器学习与运维实践相结合,经过不断探索,在根因分析方面取得了一定成效。
本文将从监控体系、根因分析体系、超时根因分析、异常根因分析等方面总结一下相关工作,愿与运维圈同仁共同探讨,为根因分析的发展贡献一份力量。
一、监控体系
特来电云平台监控体系经过几年迭代发展,目前已建成基于实时流计算的高性能、高并发、高可用的全方位立体化监控体系,作为业务系统稳定运行的眼睛,时刻紧盯系统运行状态,以下是监控体系的逻辑架构:
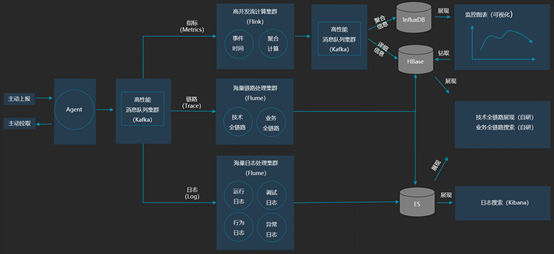
监控数据主要来自三个方面:
指标(Metrics):用于记录可聚合的数据。
链路(Trace):用于记录请求范围内的信息以及信息间的相关关系。
日志(Log):用于记录离散的事件,比如运行日志、调试日志、行为日志、异常日志等。
根因分析本质上是从海量监控数据中寻找相关关系、因果关系,因此构建完备的全链路监控体系是根因分析的基础。
监控系统主要有四个黄金指标:
流量:业务在单位时间内的调用量,如:服务的QPS、每秒订单笔数等。
耗时:业务的具体处理时长,需区分成功耗时和失败耗时。
错误:调用出错数量、成功率、失败率。
饱和度:应用已使用资源的占比。
根因分析的目的在于分析系统存在的问题,更多关注耗时及错误指标,因此超时及错误类型的全链路是根因分析的主要关注点。
我们将全链路进一步细分为技术全链路(TTrace)、业务全链路(BTrace),分别用于追踪技术请求流转以及业务节点流转,并通过高效的还原技术,将系统间错综复杂的调用关系条分缕析的展现出来。
技术全链路(TTrace)发轫于Google的Dapper论文,开源软件基金会CNCF的OpenTracing协议提供了针对Trace的统一概念和数据标准。TTrace可以跟踪一次请求经过的集群、机器、进程(分布式服务框架HSF、服务网关SG、消息应用中心MAC)、中间件(RabbitMQ、Kafka、关系数据库、Redis),是排查跨应用、跨节点、跨进程的分布式请求调用性能问题的一柄利器。
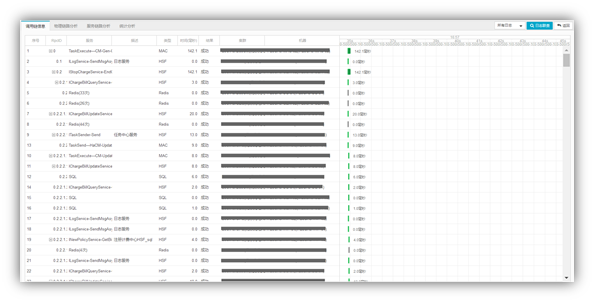
业务全链路(BTrace)就是从业务的视角出发,监控整个业务流程的流转状况及健康状况,无需切换多个业务系统,直观查看全局和上下游业务状况,用于业务系统快速发现问题、定位问题。
技术全链路及业务全链路沉淀了监控对象间的关联关系,为根因分析提供了有力的分析支撑。
二、根因分析体系
针对监控的四个黄金指标,根因分析主要关注两类场景:系统存在的超时及异常问题,对应超时根因分析、异常根因分析。
以下是根因分析的功能架构:
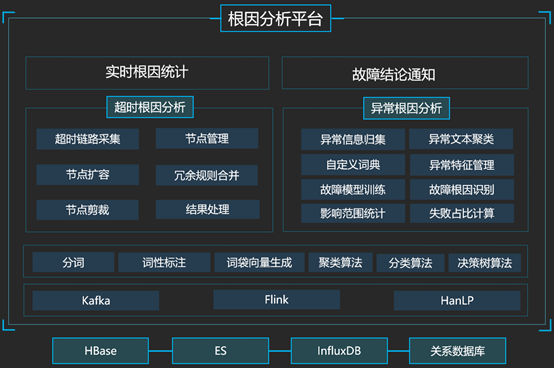
根因分析引擎基于Kafka、Flink等高性能监控数据处理中间件,结合HanLP等高效的自然语言处理框架,通过引入决策树算法、聚类算法、分类算法等机器学习手段,对超时及异常问题进行根因分析,并对根因分析结果进行实时统计,同时以预警消息的方式发送到对应负责人。
三、超时根因分析
针对超时链路根因分析,决策树算法是比较有效的机器学习算法,涉及到超时链路采集、节点管理、节点扩容、节点裁剪、冗余规则合并、结果处理等多个步骤。通过从链路根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的根因类别作为最终决策结果。
由于偶发超时的情况比较多,并不是每一个超时都是故障,我们的做法是在触发超时预警后进行根因分析,并且保证根因分析引擎在预警发生后1分钟内给出超时根因分析结果,将根因分析结果跟在上一条预警信息后面,同时提供层层穿透联查功能,可以查看根因分析过程,以及对应的超时全链路信息。

超时的根因情况很多,比较常见的故障是某个节点发生了阻塞,这种情况是比较严重的故障,需要重点对待。但是针对一次超时链路的根因分析只能反映一条链路存在的问题,当故障发生时,往往会产生大量的超时,这种单链路超时根因分析,并不能掌握所有链路的超时情况,因此需要将超时根因分析的结果进行二次聚类,以便从全局层面找到阻塞点。
四、异常根因分析
异常根因分析之所以很难有成效,一个重要的原因是开发人员在处理异常时,对异常进行了层层封装,导致异常被不断向外抛出时,很多有价值的信息被隐藏在了最底层,因此进行根因分析时需要采用抽丝剥茧的方式,从最外层异常一直找到最内层异常,(开发人员)系铃容易(根因分析)解铃难,根因分析效果很不理想。
解铃还须系铃人,针对异常层层封装难于分析的现状,我们从源头抓起,在各中间件层对捕获到异常进行逐层分析,然后将最内层异常埋点上报监控系统,从而在客户端就对异常进行初步根因分析。
从各客户端上报到服务端的异常信息,虽然是最内层异常,但是文本结构仍然比较杂乱,因此需要采用NLP机器学习技术对其进行自然语言处理:对异常文本进行分词,并将分词后的文本进行特征提取,生成词袋向量模型,然后代入到聚类算法,实现异常文本的聚类,如下所示:

经过对最内层的异常信息进行实时聚类后,结合上报的其他异常设置(客户端地址、访问目标地址、源服务ID、目标服务ID等),全局层面的异常根因分析统计便会一览无余的呈现在运维人员面前,如下所示:

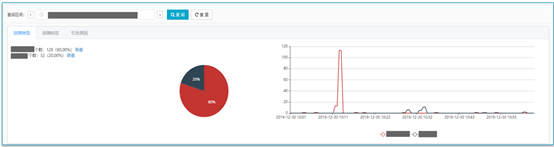
异常信息文本聚类只是迈出了异常根因分析的第一步,因为尽管系统有很多异常,但并不一定代表系统有故障,所以需要建立故障特征库,并将异常聚类信息与识别出的故障特征进行匹配,从而实现故障根因分析,如下所示:
五、应用价值
随着业务系统的日益复杂,互联网企业7*24小时的线上运维压力越来越大,依靠传统的运维手段,完全无法应对线上故障的根因分析及故障恢复,经常会陷入手忙脚乱、束手无策的混沌局面,因此具备基于机器学习的智能运维根因分析能力,是每个运维人员的必备技术保障。
我们基于机器学习技术,结合自身运维实践研发的根因分析产品,有效应对了线上海量监控数据的运维压力,将故障定位分析能力从以前的30分钟缩短到1分钟,极大提升了故障定位能力,为故障的快速恢复赢得了宝贵时间。
通过根因分析技术,不仅实现了故障的快速定位,还实现预警消息的收敛发送,保证只把根因预警发送给运维人员,极大提升了运维人员处理问题的效率。
六、发展规划
根因分析虽然能定位问题产生的原因,但有时并不一定是问题产生的源头,所以需要做进一步的根源分析,也即系统变更分析,比如补丁发布、促销活动、混沌工程演练等,正是这些源头上的变更,导致了潜在故障的发生。
要实现真正的智能运维,除了要有强大的根因分析、故障分析能力,还必须有强大的自动运维能力,因此将根因分析、故障分析结果对接自动运维,实现故障的自发现、自分析、自愈,是每个运维人员的终极梦想。
七、总结
健全的海量高并发实时监控体系,完善的全链路监控能力,强大的根因分析能力是互联网企业必备的监控运维必杀技,进一步强化故障分析能力、根源分析能力,并辅以自动运维能力,智能运维甚至无人运维并非遥不可及。
八、特来电云计算与大数据微信公众号
1.微信公众号名称:特来电云计算与大数据
2.二维码:
