具体算法代码网上有现成的工具类。不一一列举了。我在做某个项目的时候发现LD算法有个弊端。就是对于较大文本(>5w)的相似度计算会特别慢,原因在于LD的计算形式是:
LD 可能衡量两字符串的相似性。它们的距离就是一个字符串转换成那一个字符串过程中的添加、删除、修改数值。如果文本变的非常的大可以想象计算的次数
如果两个字符串都是20000字符,则LD矩阵的大小为20000*20000*2=800000000Byte=800MB。故,在比较长字符串的时候,还有其他性能更好的算法。
下面介绍下余弦算法 余弦相似度量:计算个体间的相似度。相似度越小,距离越大。相似度越大,距离越小。
如何计算:一个向量空间中两个向量夹角间的余弦值作为衡量两个个体之间差异的大小,余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋于90度,表明两个向量越不相似。1、分词;2、列出所有词;3、分词编码;4、词频向量化;5、套用余弦函数计量两个句子的相似度。
下面是个人的比较,文本为一段文字复制出的(不要忽略这个前提)
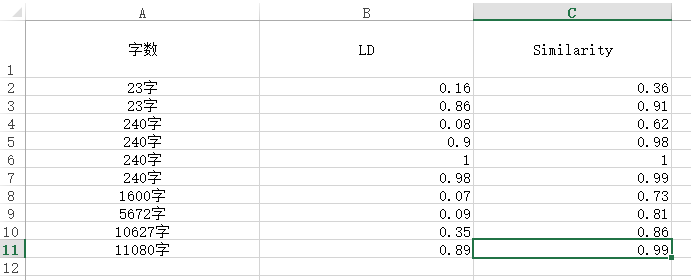
精度问题,个人更加偏向于LD算法,这个余弦算法对于(复制的)大篇章修改的计算精度有问题,可能理解有误望指正