1. 文本向量化
1.1 词袋模型
词袋模型,顾名思义,就是将文本视为一个 “装满词的袋子” ,袋子里的词语是随便摆放的,没有顺序和语义之分。
1.1.1 词袋模型的步骤
- 第一步:构造词典
根据语料库,把所有的词都提取出来,编上序号 - 第二步:独热编码,D维向量
记词典大小为D,那么每个文章就是一个D维向量:每个位置上的数字表示对应编号的词在该文章中出现的次数。
1.1.2 词袋模型的缺点
- 只统计词语是否出现或者词频,会被无意义的词汇所影响
解决:文本预处理(a.去除停用词;b.文字、字母、标点符号统一;c.利用TF-IDF去除不重要的词) - 无法识别语义层面的信息
解决:基于深度学习的文本表示(词向量、句向量等) - 无法关注词语之间的顺序关系
解决:深度学习
1.2 TF-IDF
TF-IDF是一种统计方法,用以评估某一字词对于语料库中的一篇文章的重要程度。其算法简单快速,结果也比较符合实际情况。
1.2.1 TF-IDF的步骤
- 第一步:统计词频TF
统计每个词在文本中出现的次数,出现的越频繁,那么就越可能是这个文章的关键词。
词频TF = 某个词在文章中出现的次数/文章的总词数
词频TF = 某个词在文章中出现的次数/文章中出现的最多的词出现的次数
- 第二步:计算逆文档频率IDF
IDF用于衡量每一个词在语料库中的重要性,一个词在语料库中越少见,它的权重就越大;反之,一个词在语料库中越常见,它的权重就越小。
//首先需要有一个语料库,来模拟语言的使用环境。
逆文档频率IDF = log(语料库的文章总数/(包含该词的文章数+1))
- 第三步:计算TF-IDF
TF-IDF用于衡量某个词在文章中的重要性。TF-IDF与该词在文章中的出现次数成正比,与该词在整个语料库中的出现次数成反比。
TF-IDF = TF * IDF
TF-IDF还可以用于关键词的自动提取:在计算出文章中的每个词的TF-IDF值后,按降序排列,取排在最前面的几个词。
1.2.2 TF-IDF的缺点
- 维度太高,不易于计算
解决:引入了LSI,从语义和文本的潜在主题来分析。
LSI是概率主题模型的一种,基于统计学和概率论方法实现,类似的模型有LDA等。
核心思想:每篇文本中有多个概率分布不同的主题,每个主题中都包含所有已知词,但是这些词在不同主题中的概率分布不同。LSI通过奇异值分解的方法,计算文本中的各个主题的概率分布。
优点:向量从词的维度下降到主题的维度,维度更少,计算更快。
- 无法体现词的位置信息
解决:对全文的第一段和每一段的第一句话,给予较大的权重。 - 无法识别语义层面的信息
解决:基于深度学习的文本表示(词向量、句向量等) - 无法关注词语之间的顺序关系
解决:深度学习
1.3 词向量:word2vec
详见本人博客:词向量(从one-hot到word2vec) - 银山词霸的碎碎念 - CSDN博客
https://blog.csdn.net/weixin_38493025/article/details/85245044
2. 距离公式
2.1 余弦相似度
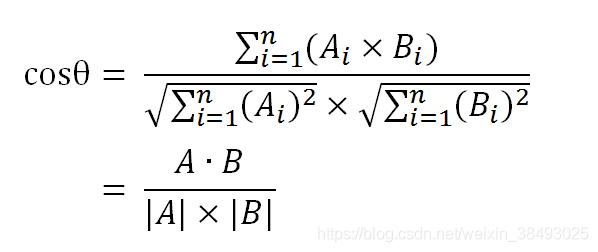
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
参考教程
- 文本相似度算法小结 - 云+社区 - 腾讯云
https://cloud.tencent.com/developer/article/1038872
