转载大神的很多优秀文章,可以前往:https://zhuanlan.zhihu.com/p/53181893
这里仅做自我学习使用。
本文内容
- 介绍了机器学习间接性的特点,给出机器学习问题的形式化定义,并在此基础上将误差的来源分解成近似误差,估计误差和优化误差。
- 从优化的角度分析了模型的训练。介绍了梯度下降的动机。以梯度估计噪声的视角介绍了 SGD,mini-batch SGD 以及 full -batch GD 三者的联系和区别。从梯度下降的假设出发,分析了其收敛的条件,并给出了常见训练技巧的动机(learning rate 和 batch size 的调试、训练集的 shuffle 以及 learning rate annealing)。分析了梯度作为参数更新依据的局限性,并简单介绍了二阶方法的动机。最后介绍了梯度优化稳定性与模型结构的关系。
- 从泛化的角度分析了模型的训练,以 batch size 大小对模型训练的影响为主线。介绍了 "Generalization Gap",即大 batch size 带来的泛化性能低的现象。分析了一个主要原因:更新量不足,并介绍了两种解决方案:将更新步数和小 batch size 对齐,以及增大 learning rate。增大 learning rate 符合训练加速的期望,但会带来训练稳定性和泛化性能的下降, 经验上可以通过 learning rate warmup 以及对各层参数的梯度进行归一化来缓解。原理上泛化性能似乎与优化过程更新的"噪声"有关。来自 Google Brain 一篇文章定义了"噪声"的表达式,其与 learning rate,batch size 和训练集大小有关。初步的实验显示对于某个任务-模型的组合,似乎存在一个最优的"噪声",固定这个"噪声"值和其他变量后训练集大小和 batch size,learning rate 和 batch size 均呈线性关系。
前言
在介绍完分布式训练后,为了将故事讲完整,本文涉及的内容其实是绕不开的。本文会以综述和简介的方式,将笔者读过的东西串成一条线,希望能为读者提供一些实践中使用的 tricks 的动机。如有事实上的错误,希望能够指出并赐教。
本文由于信息量比较密集,且有部分来回引用,推荐在电脑屏幕上细读。知乎并不支持页内跳转,所以文中引用对应的链接可以直接打开论文的网页。为了方便读者阅读,每个部分结束时都会带上简单的小结。对机器学习比较熟的朋友可以跳过第一小节本文重在直观结论,公式和符号的存在是为了更精确地表达概念,所以跳过部分公式也不会造成理解上的困难,文中也并没有太多推导。
1. 机器学习问题的简单拆解
1.1 简单的概率论符号
遵从一般的习惯,我们用大写字母 代表随机变量,小写字母
代表随机变量的特定取值。
的每个取值区间对应了样本空间(sample space)里的一个事件(event)。这里的随机变量可以是一个标量(scalar),也可以是一个向量(vector),这里不做区分。随机变量
的概率分布
定义了每个取值区间对应的概率值。
记 为随机变量
的函数
(也是一个随机变量) 在分布
中的期望(均值)。可以认为期望
抹去了变量
的随机性,转用一个常量来描述在分布
中变量
的性质(平均取值/中心点)。
联合概率分布 描述了两个随机变量
的概率分布。在联合概率分布的基础上可以定义条件概率分布
,表示给定
的取值后
的概率分布 — 样本空间随着
取值的确定而改变了。在条件概率分布的基础上可以定义条件期望
。
1.2 机器学习和泛化
机器学习里最典型的问题是监督学习(Supervised learning):给定输入 ,预测输出
。产生输入
和输出
的机制通常用一个联合概率分布
描述。给定输入
后,
的分布转由条件概率分布
描述。我们通常会使用条件期望
去描述这个分布,这是一个关于
的确定性函数(deterministic function)。
我们通常用一个函数(通常称为 Hypothesis function) 来近似
,
。
为了刻画 对
近似的好坏,我们通常会定义一个损失函数(loss function/cost function)
来描述
产生的近似错误:当
离输出
比较远时值比较大,反之比较小。在二分类任务中,
为 0-1 标签,我们可以用
,其中
为指示函数,当
时为 1, 否则为 0。
有了在单个取值上的损失函数后,我们可以定义期望风险(Expected Risk) ,描述
在分布
下的平均近似错误。
比较低时,我们会说
的泛化性能比较好。
有了评价指标后,我们自然想要找出最小化 的函数
。然而我们并没有分布
的全部信息(否则就没机器学习什么事了)。但我们可以采集到分布
产生的一系列样本
。假设我们有
个样本,我们可以通过这些样本的平均错误对
进行估计:
,
被称作是经验风险(Empirical Risk),对应的样本称为训练集。在机器学习文献中 ,
有时也被叫做 Loss。
我们只能找到最小化 的函数
,并期待对应的
比较小 。这种做法叫做 ERM(Empirical Risk Minimization)。用经验风险去估计期望风险,这是机器学习间接性的一种体现。
但最小化 不一定能带来比较小的
:假设我们找到的函数
为 “记住所有样本
,我们可以让
变得很小,但是
的值却没法保障。
也被称为泛化误差(Genaralization Error),是一个关于
的函数。机器学习的核心问题之一泛化(Genaralization)就是定量确定影响泛化误差的因素。
我们通常会用一个与训练集不相交的样本集,即测试集去估计 。在固定
并比较
时,泛化性能和泛化误差
在讨论中表达的意思是一致的。
1.3 优化的限制
优化(Optimization)算法对问题的定义也有一定的限制。
通常我们会要求 对
可导,从而可以用上基于梯度的优化算法。然而上述二分类问题的损失函数
对
不可导,所以我们通常用一个可导的函数,如 cross entropy 或者 hinge loss 来作为二分类的损失函数。这是机器学习间接性的另一种体现。
我们还需要对搜索的范围做限制。以所有可能的函数作为搜索空间会带来优化算法设计的困难。我们往往会根据问题的类型确定一个模型(Model),从而定义以向量 为参数(Parameter)的一族函数
。给定模型后参数
和函数
一一对应。
模型的确定通常还需要其他不参与训练的参数,如模型层数的多少,隐层的维度等,我们称之为超参数(Hyper-Parameter)。
1.4 误差的拆解[Bottou et al, 2008]
出于种种原因,我们往往没办法找到最优化 的函数
。定义以下符号:
为最小化期望风险
的函数。这是我们想要找到的函数
为模型中最小化期望风险
为模型中最小化经验风险
的函数
为利用优化算法在模型中找到的最小化经验风险
机器学习的误差可以拆解成以下三点:
- 近似误差(Approximation error)
。
- 估计误差(Estimation error)
。
并不能完美估计
- 优化误差(Optimization error)
:优化算法不一定能找到全局最小
我们找到的是 ,但想要的是
,这中间的误差便为:
在传统机器学习中,我们 trade-off 的是近似误差和估计误差,优化误差基本上可以忽略不计。但在深度学习中,通常会认为近似误差可以忽略不计,我们 trade-off 的主要是估计误差和优化误差。
模型的设计控制着模型的表达能力,这决定了近似误差 。设计中归纳偏差(inductive bias) 的使用使得不同模型有着不同的样本复杂度(sample complexity),这决定了在有限数据集下估计误差
的大小,以及模型优化的难度。由于模型类型限制,部分模型无法使用梯度下降的优化方法,只能使用 EM 算法(Expectation-Maximization),极端情况下甚至只能用黑箱优化方法;而即使能使用梯度下降,
对应的 Loss surface 的光滑程度也受模型设计影响(见 2.5 节),这也决定了梯度下降(见 2.1 节)的收敛性和稳定性(见 2.3 节)。
模型的训练方案决定了估计误差 和优化误差
。通常我们不会让模型收敛到
最低的点,因为这会带来比较大的估计误差
。trick 和超参数的选择,如 learning rate schedule 的方法,batch size,optimizer,normalization,early stop 的轮数和 dropout 等,在影响优化误差
的同时,也是在做估计误差
和优化误差
间的 trade-off。
1.5 小结和符号的简化
至此我们介绍完机器学习问题的定义。
1.2 中我们谈到机器学习的目标是找到最小化期望风险(Expected risk) 的函数。由于我们没有数据生成分布的信息,只能通过优化算法找到最小化经验风险(Empirical risk)
的函数。1.3 中提到由于优化算法的限制,我们只能定义一个模型,并在模型定义的函数族内搜索最优解。
在 1.4 中我们将机器学习任务的误差拆解成了三部分:近似误差、估计误差和优化误差,并简单分析了传统机器学习以及深度学习的不同之处。
下面的讨论中我们着重关注模型的训练方案带来的影响,并把重点放在优化方法上。为了讨论方便,我们对符号做一定的简化,以突出机器学习中优化问题的核心。
在上面的讨论中,随机变量 总是成对出现,我们可以把它们合成一个随机变量
,其取值对应为
,作为损失函数
随机性的来源。给定模型后,
完全由
决定。
综合这些考虑,我们将损失函数 改写成
。损失函数
同时受确定性变量(Deterministic variable)
和随机变量(Random variable)
影响,是关于
的随机函数(Stochastic function)。
对应的经验风险为:
对应的期望风险为:
2. 对 ![[公式]](https://www.zhihu.com/equation?tex=R_N%28%5Ctheta+%29) 的优化: SGD [Bottou et al, 2018]
的优化: SGD [Bottou et al, 2018]
2.1 梯度下降的动机
下面简单介绍梯度下降的动机。
假设我们有一个多元变量函数 。
在
处的梯度(Gradient)
对应函数 在
附近极小范围内增长最快的方向,模长
对应在这个范围内
的变化速度。梯度的反方向为下降最快的方向。
“ 附近” 可以写成点集
,其中
为任意向量。极小范围意味着
。
顺着梯度方向走一小步:
其中 为更新的步长(学习率,learning rate)。
我们放宽梯度定义中对于 的限定。假设
在
附近变化不大,即
若令沿着梯度方向的更新量足够小,即 ,我们可以保证函值的下降,即
因为在 附近梯度
的反方向一直指向
附近
下降最快的方向。
持续不断地进行迭代, 最终会无法继续下降,此时称
收敛到
的一个局部最小值或者定点。这便是梯度下降(Gradient Descent) 的基本思路。对于凸函数,可以证明其为全局最小值。
值得注意的是梯度的模长 并没有包含步长信息,即在一步更新中,为了使函数值下降量最大,即令
最小,更新量的模
需要多大。
假设 在
处使函数值下降量最大的更新量的模为
对 简单地乘上一个常量
后,更新量的模变成了
但由于乘上常量 只是对值域做了纵向拉伸,并没有影响定义域,所以更新量的模
应保持不变。由此可见梯度的模
不是确定更新量的模
的好依据。这也启发了 3.4 介绍的算法。
2.2 梯度估计噪声的控制:Stochastic, Mini-batch Stochastic 和 Full-batch
我们可以用梯度下降优化经验风险 ,并期待收敛到的解的期望风险
比较小。优化过程也称作模型的训练过程。
如果我们定义一个梯度估计函数去估计每一步更新的梯度
以及参数更新规则:
在这个定义的基础上:
- Stochastic Gradient Descent(SGD):
- Mini-batch Stochastic Gradient Descent:
- Full-batch Gradient Descent:
其中 为参与梯度估计的样本数量,即 batch size。我们将一个 batch 里面采样的随机变量拼成一个向量
,其中元素
为第
个 batch 中第
个样本对应的随机变量
的采样。采样向量
对应的随机向量为
。batch size 越大,
越趋近于
。注意随机变量
本身也是一个向量,但因为和下面讨论无关所以不做区分。
所以三种不同的梯度下降的区别在于对单步更新的计算复杂度和梯度估计噪声的 trade-off。Full-batch Gradient Descent 的梯度估计完全没有噪声,但是每一步更新的代价很高。 时每步更新的代价很低,但是梯度估计的噪声很高。
在深度学习的实践中,由于并行加速的普遍性,我们通常用的是 Mini-batch Stochastic Gradient Descent,并通过调整 batch size 去对梯度估计噪声和更新速度进行 trade-off。如无特别说明,当我们提到 SGD 时,我们通常是指 Mini-batch Stochastic Gradient Descent。
2.3 噪声下 SGD 的收敛性
梯度估计噪声的存在可能会导致优化无法收敛。我们在 2.1 中提到了梯度下降收敛的前提条件: 在
附近变化不大,即
。
“变化不大”可以理解成局部梯度估计的可靠性,或者是函数 对应曲面
的光滑性。这可以用 Lipschitz-continuous gradient 假设来描述:
函数 对于任意
,
满足
,其中
为 Lipschitz 常数。
这个假设规定 的梯度变化速度被一个线性函数约束住。
这个假设有一个重要推论:
在优化 的过程中,第
步的更新量为
。代入上面的推论有
取决于对梯度的估计
。而梯度估计取决于采样向量
,这取决于随机向量
。我们将每一步更新的随机性用期望抹掉:
为了保证优化能够收敛,即平均上看, 的值在每一步更新后都能下降,我们需要保证不等式左边满足
,即不等式右边要满足
由于 ,上式等价于
姑且把第一项称为更新噪声项,第二项称为更新信息项。我们希望噪声项比较小,信息项比较大,此时优化的收敛速度最快。
为了让噪声项 比较小,我们可以
- 让步长(learning rate)
的取值足够小
- 让梯度估计模平方的期望
足够小,即让梯度估计的方差及其均值平方都足够小。 梯度估计的方差可以通过增大 batch size 来减小。
为了让信息项 比较大,我们可以
- 让梯度估计的期望
和 full batch 梯度
夹角足够小
- 让梯度估计的期望
变大,从而使噪声项变大。
到这里我们不难理解深度学习调参过程中几个做法的用意了:
- 对训练集进行随机打乱以保证样本的 i.i.d(independent and identical distributed) 分布。这是为了保证对梯度的无偏估计,从而使
,此时梯度估计和 full batch 梯度间的平均夹角最小。在 i.i.d. 的假设下,这个关系对于任意
都成立。
- 步长(学习率,learning rate) 和 batch size 的调试。减小步长或者增大 batch size 可以减小噪声项
,使优化得以收敛。在一定限度内,增大 batch size 的同时增大步长
光滑程度
限制,
- Learning rate annealing 。 在优化迭代的过程中,由于
会不断减小直至趋近于 0,此时噪声项
会使优化陷入停滞,参数不断在最小值附近抖动。我们可以将
假设每一步更新 都有一个步长
。可以证明当
序列满足
及
时,凸函数可以收敛到全局最优解(global optima),非凸函数可以收敛到定点(stationary point)。
2.4 比梯度更好的更新:二阶方法的动机
“ 附近” 可以写成点集
,其中
为任意向量。极小范围意味着
。梯度方向只是代表在一个极小范围内函数增长最快方向。但是一旦把范围
扩大,梯度代表的方向便不一定是最优的更新方向了。我们在 2.1 中也讨论过梯度的模长不含更新步长的信息。所以即使梯度下降的收敛性可以得到保障,在有了步长信息以及更好的更新方向后,优化收敛速度的还可以进一步加快。
函数 在
附近可以用泰勒展开去近似。泰勒展开的项越多,在更大的局部范围内(对应更大的
) 对函数
的近似就越准。由于高维空间中的泰勒展开计算的复杂度极大,这里我们只保留两项:
其中 为向量函数
在
附近的 Hessian 矩阵,描述了
在
附近的曲率特性。上式右边对
求导并令其为 0,我们可以求解出一个局部二次方程的解:
这便是二阶优化方法中的牛顿法。当 为二次函数的时候,上述迭代只需要一步就能到达全局最小值。
局部的曲率信息 可以用来估计更优的更新方向以及更新的步长。在知道局部曲率后,我们可以缓解下图中无谓的剧烈抖动,加快收敛速度。图来源于[Goh et al, 2017]。

Hessian 矩阵的估计和求逆有较大的时间/空间复杂度,所以一般都会对 进行一些计算或者近似的处理。我们还可以做更简化的处理,如 LBFGS,利用一阶信息去估计一个矩阵
来对梯度做变换。更激进的做法是只近似
的对角线,甚至抛弃估计 Hessian 矩阵的目标,直接稳定各个维度更新的速度,如 RMSProp 和 Adagrad。
2.5 调整 ![[公式]](https://www.zhihu.com/equation?tex=R+_N%28%5Ctheta%29) 的 Lipschitz 常数
的 Lipschitz 常数
我们常说的 loss surface 即为高维曲面 。Lipschitz 常数
越大(或者更极端的,
不满足 Lipschitz continuous gradient 的假设),说明 loss surface 越不光滑,局部的梯度估计的有效范围很小,即
中 很小。系统输出值随输入的变化速度在数值分析中用 condition number 去刻画。condition number 高,小的输入扰动带来较大的输出值扰动,这通常被称为 ill conditioned。
此时我们需要用一个很小的步长(或学习率,learning rate) 来防止优化发散甚至梯度爆炸。 但
太小的话会带来收敛速度的减慢,甚至使模型无法训练。
的 loss surface 由数据分布和模型结构共同决定。但由于 loss surface 是一个极高维度的曲面,分析和可视化都存在近似错误的可能性,所以这一方向的结论都不是很强,只能提供一些感性认知。
[Li et al, 2017] 通过高清无码(误)的可视化提供了一些结构和 loss surface 间关系的直觉:
- 网络层数越多,网络隐层越窄,loss surface 越不光滑。
- Skip-connection,如 Residual connection 可以将 loss surface 变得光滑。
- Loss Surface 上有很明显的大片连续的光滑区域和大片连续的不光滑区域。这可能对应了不同初始化位置对优化效果的影响。
下图为 [Li et al, 2017] 中比较 impressive 的展示。直觉上 skip connection 使得 loss surface 变得很光滑。

[Santurkar et al, 2018] 对 Batch Normalization 的原理做了很精彩的分析。Batch normalization 的实际作用并不是降低 internal covariate shift,而是通过对网络参数进行 reparameterization,从而将 的 loss surface 变得光滑,进而使得网络训练对参数初始化和训练步长不敏感。
2.6 小结
2.1 中我们讨论了梯度下降的动机,并强调梯度的模不包含步长信息。以梯度估计的噪声为标尺,在 2.2 中我们介绍了三种更新方式:Stochastic Gradient Descent,Mini-batch Stochastic Gradient Descent, 以及 Full Batch Gradient Descent。接着在 2.3 中我们讨论了在梯度估计存在噪声时,梯度下降收敛的条件,并分析了这些条件对调参实践的指导。最后在 2.4 中我们简单介绍了二阶优化方法的动机,并在 2.5 中讨论了模型设计对梯度下降稳定性的影响。
至此我们在优化的视角下对模型训练过程做了简单的分析。在优化的视角下,我们的最终目标是最小(大)化给定的函数。但正如 1.2 中提及的,机器学习的核心在于最小化期望风险 ,以达到比较高的模型泛化性能。下面我们开始讨论模型训练过程对泛化性能的影响,重点放在 batch size 上。
3. Large Batch Training 和 Generalization Gap
3.1 Generalization Gap 提法的由来
在 2.2 中我们提到现在的主流做法通常是 Mini-batch SGD。在分布式训练的方案和效率对比一文中我们重点介绍了多卡同步更新的范式。为了充分利用计算节点的计算资源,每个节点需要拿到足够大的 mini batch,这就意味着总的 batch size 会随着节点数量的增大而增大。
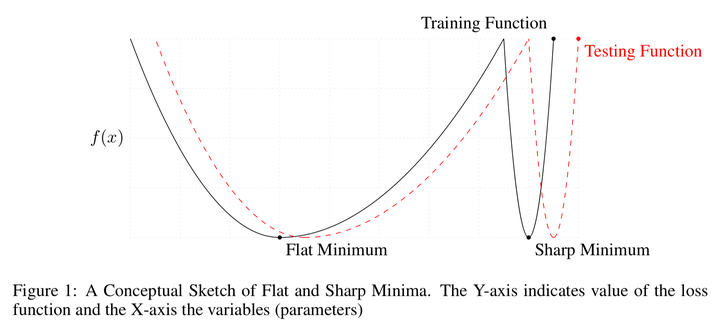
然而在早期深度学习的文献中,过大的 batch size 训出的模型往往会比小 batch size 训出的模型差([Krizhevsky, 2014], [Lecun, 1998])。[Keskar et al, 2016] 深入地探讨了这种现象。他们发现在训练集准确率一致时,用大 batch size 训练得到的模型的泛化性能会明显低于小 batch size 训练的模型,并将其称为 generalization gap。他们使用 sharp/flat minima 的猜想去解释 gap 的产生,并提出了一个简单的 sharpness 的估计方案去论证大 batch size 训练收敛到的解比较 sharp。
3.2 Gap 并不存在:更新量不足
Sharpness 的解释呼应了 [Hochreiter et al, 1997] 中的猜想,也是一个很符合直觉的解释。对于一个局部最小值解,flat minima 对应的是局部曲率比较平缓的解。这些解在分布的变化下有更好的鲁棒性。下图摘自 [Keskar et al, 2016],可以看到在数据分布偏移带来的 loss surface 的偏移中,flat minima 对应的解的 loss 值变化不大。
我们其实可以绕开 sharp/flat minima 的解释,单纯去匹配大 batch 和小 batch 在训练过程中的行为。[Hoffer et al, 2017] 用实验表明,gap 的产生似乎来自于不充分的参数更新。
令 为 batch size,
为更新步长,在
步内参数的总更新量为
其中 是第
个 batch 里面的第
个样本。如果我们令 batch size 的大小
,以及使对应的步长
,同样的数据只够更新一步
在深度学习的实践中我们通常会用训练数据的使用轮数(epoch)来调整训练过程,比如决定 learning rate schedule 的方法,以及确定终止训练的条件。[Keskar et al, 2016] 的实验便是如此。
但从上面的分析中可以看出,在相同 epoch 数下,batch size 越大,训练时参数的总更新步数会越小,相应的总更新量也会越小。由于最优解通常和初始化点有一定的距离,当总更新量小的时候,优化算法在参数空间内的探索便被局限于初始化点附近的有限范围,找到的解自然可能比较差。
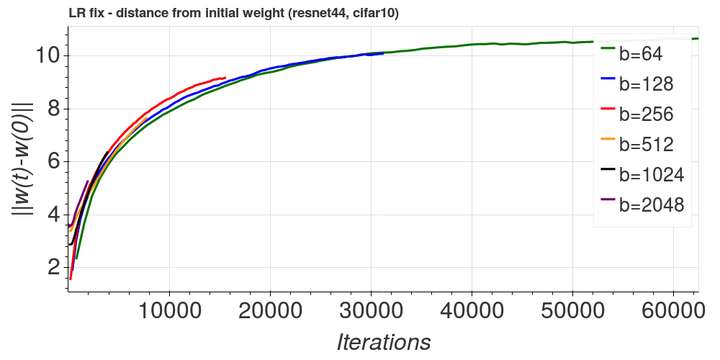
下图便为各个 batch size 下,参数离其初始化点的距离 随迭代次数的变化。可以看到大 batch size 训练对应的最终参数离初始化点很近。图摘自[Hoffer et al, 2017]。

上图中还可以看出另一个有趣的现象:在相同迭代次数下,不同 batch size 大小对应的 也不同。在这个实验中,
对应的参数远离初始化点的速度最快,而其他
的取值则会使速度变慢。
[Hoffer et al, 2017] 利用随机游走(random walk)对训练初期进行建模,由此推出距离 的增长速度和更新量的协方差矩阵
有关。更新量的协方差矩阵取决于 batch size
。我们可以使 batch size
和步长
保持关系
(square root scaling)来使不同 batch size 更新量的下协方差矩阵一致。我们也可以对梯度乘上一个高斯噪声来达到此目的。
将协方差矩阵调整一致后,我们可以看到曲线趋于重合,参数的”游走”速度保持一致。简单地做了这种修正后,即使不增加更新步数,所谓的 generalization gap 也能够被部分缓解。图同样摘自[Hoffer et al, 2017]。
在 2.4 中我们提到 和
控制着更新的噪声,由此可以看出训练过程中的噪声控制着参数”游走”的速度。过大的 batch size 减小了噪声,过早的 annealing 也是减少了噪声较大的更新步数。噪声似乎控制着训练过程中对参数空间的探索方式,从而影响找到的解的泛化能力
在保持其他因素不变,将小 batch size 和大 batch size 的 learning rate schedule 以及更新的总步数调整一致后,[Hoffer et al, 2017] 发现所谓的 generalization gap 消失了。
3.3 减少迭代次数:Linear Scaling
3.2 的结论是我们可以增加更新步数以保证足够的更新量,从而保证模型的泛化性能。但这抵消了并行训练带来的收益。在增加了计算节点之后,我们仍然需要跑同样的步数,而且由于 work 间同步通信带来的的耗时,每一步的时间开销反而变得更大了。
回到 3.2 中对于两种 batch size 的分析:
小 batch size :
大 batch size
假设 成立,我们只需要让
,就能保证在读取相同的数据量的情况下更新量也相同,此时大 batch size 需要的更新步数会变少,进而达到加快训练速度的目的。
更一般地,在上述假设成立的前提下,步长和 batch size 可为线性关系(linear scaling) 并保证训练过程一致。Linear scaling 很早就在[Krizhevsky, 2014] 中被提出,然而在 AlexNet 上使用 batch size 为 1024 时,测试准确率会比小 batch size 低 1% 左右。
我们来简单分析一下问题。上述 成立有两个前提:
- 对于相同的
和不同的
,
的值很接近。这一点可以由不同 batch 对应的
分布稳定,以及
- 对于相邻的几次迭代的不同参数
,
的值比较相近。这一点需要更新步长
第一个前提很好满足,只需要将训练集很好地 shuffle 就好了, 是一个常用取值,在这个取值下
的 variance 可能不会太大 。第二个前提中要求的
比较小也很好处理。
对于局部的 loss surface 比较光滑这一点,除了受模型结构影响之外,也受参数在高维空间中的位置的影响。在模型初始化点附近的 loss surface 通常会比较粗糙,抖动很大。这个假设可以从训练集的 loss 曲线的变化行为找到支持。我们通常会将 随 epoch/step 变化的曲线称为 loss 曲线。在训练开始时梯度更新的方向会很不稳定,loss 在开始训练的时候可能会停滞不动一段时间,然后进入一个快速下降的时段。在 2.5 提到的 [Li et al, 2017] 中也提到 loss surface 中光滑和粗糙的区域可能是成片的。
由于训练开始时 loss surface 比较粗糙, 并不成立,所以 linear scaling 后的更新路径和小 batch size 对应的路径不一致,这可能是最后测试结果比较差的原因。同时 linear scaling 后的 learning rate 会很大,直接使用这个 learning rate 可能会使训练发散。
在这种直觉理解的支持下,[Goyal et al, 2017] 提出使用 learning rate warmup 来解决这个问题。learning rate warmup 在训练开始的时候使用小 batch size 设置下对应的的学习率,然后在头几个 epoch 里面将 learning rate 线性增长到 linear scaling 后的学习率(这对应[Goyal et al, 2017]中的 gradual warmup,也是表现最好的方法)。这可以使训练开始时更加稳定,也成功在 ResNet 上将 batch size 提高到 8096 并保持泛化性能不变。更有趣的是,不同 batch size下 loss 关于 epoch 的曲线几乎重合,只在头几个 epoch 处有所偏离。这种偏离来源于 warmup 阶段更新量的差异。图摘自[Goyal et al, 2017]。
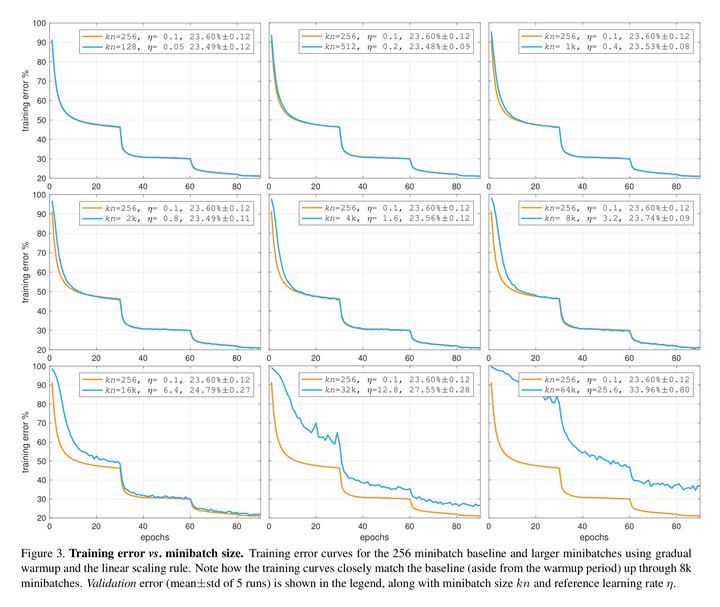
注意到将 batch size 继续提高直至超过 8096 后,模型测试准确率开始变差,loss 曲线开始大幅偏离。正如 2.3 中分析的,learning rate 不能无限上升,这是由 loss surface 的光滑程度,即 loss function 的 决定的。
2.5 中提及 skip connection 和 batch normalization 可以使 loss surface 变光滑。在 [You et al, 2017] 中的实验可以映证这一点:在使用 linear scaling 的情况下,ResNet 可以采用比 AlexNet 更大的 learning rate 进行训练而免于发散,而 AlexNet 在加上了 batch normalization 之后,也可以在比较大的 learning rate 下训练。
3.4 更大的 Batch Size: Layer-wise Adaptive Rate Scaling
[Goyal et al, 2017] 在保证泛化性能的前提下, batch size 最大只能提高到 8096 。我们可以使用更大的 batch size 吗?
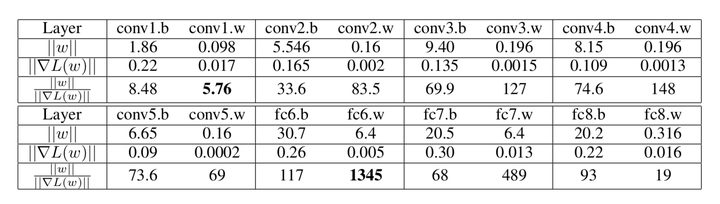
在初始化时各个参数通常都有相近的模。然而在每一步更新中,模型各个参数的模和对应梯度的模之比 通常是不一致的。这导致更新时参数的相对更新量不一致,在learning rate 比较大的时候甚至会出现更新量比参数大的情况。这可能是训练不稳定性的来源之一。下表截自[You et al, 2017] ,展示了 AlexNet 各层的
。
而在 2.1 中我们也提到梯度的模 中并不带有步长的信息。
基于以上的观察,[You et al, 2017] 将各层参数的相对更新量做了归一化,这便是其提出的 Layer-wise Adaptive Rate Scaling(LARS) 的基本想法。
对于第 层的参数
,普通的更新为
LARS 的更新为
这里增加了更新量的归一化。此时梯度的模包含的信息被丢弃,只使用了梯度的方向信息。
而实验也证实了其对训练过程的稳定效应。使用了LARS 后,[You et al, 2017] 将 ResNet 的 batch size 提高到了夸张的 32k,同时保持和小 batch size 设置下相同的泛化性能。
值得一提的是 LARS 和 adaptive optimizer 如 RMSProp,Adagrad 等的区别。Adaptive optimizer 对每个 tensor 的每个元素都做了梯度的 rescale,但 LARS 选择了更粗的粒度—每个构建计算图的 tensor。这可能是一个更合理的方案,因为每个 tensor 都是作为计算图的一个节点,tensor 内的元素在计算上是同级的,而它们的梯度则共同由其在计算图中的位置决定。
3.5 训练噪声和泛化
3.2-3.3 中提到的方法都是为了匹配小 batch size 和大 batch size 下的训练行为。3.4 则是用实验证明了一个直觉想法。他们其实都绕过了对一个问题的正面回答:训练过程的什么特性能够帮助我们找到泛化性能更好的解?
这是一个仍未有定论的问题。这里介绍一点 intuition 以及初步的工作。
在 2.3 的介绍中,我们提到了梯度更新中的”噪声项” 。这个”噪声项”由 batch size
和步长
决定。提高
或者降低
,我们可以使”噪声项”的值降低,从而使优化得以收敛。
在 3.2 的介绍中我们提到,参数更新的“噪声”对参数的”随机游走”速度的影响。似乎存在一个最优的噪声水平,使得随机游走的速度最快。同时在 3.3 的 linear scaling 中,似乎是在保持一个稳定的“噪声”水平。
似乎”噪声”的概念不仅与优化的收敛有关,还与找到解的泛化性能有关。这个思路启发了[Smith et al, 2017a] 的理论推导。由于缺乏随机微分方程的知识,笔者没法对推导的可靠性进行评判,具体推导可以看论文第五节。
文章推导了噪声的表达式
其中 为更新步长,
为训练数据总量,
为batch size 大小。当
时
。这正是 linear scaling rule。
为了验证 这个关系,以及最好的泛化性能对应某个固定的
,作者做了一些有趣的控制变量实验。可以从下图看到各个步长(leanring rate)下面的最佳 batch size 和步长呈线性关系。图截自 [Smith et al, 2017a],下同。

在后续的文章 [Smith et al, 2017b] 中,作者也证明了增大 batch size 和减小 learning rate 在泛化效果上近乎等价。这也为 linear scaling 提供了更强的证据。
另一个不是很强的结果里,训练集大小和其最佳 batch size 大致呈正相关关系。
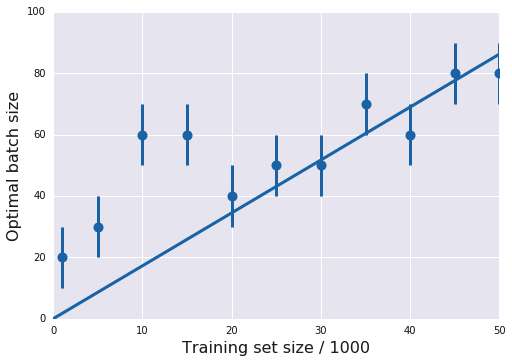
3.6 小结
在 3.1 中我们介绍了什么是 generalization gap。在 3.2 中我们指出 generalization gap 的问题根源来自于更新量的不足,并介绍了解决 generalization gap 的一个方案: 多更新几步。然而这和分布式训练的初衷相违背。所以在 3.3 中我们介绍了 batch size 和步长 linear scaling 的方法,分析了这个方法的早期尝试失败的原因,并介绍了 learning rate warmup 来解决其问题。但即使这样,linear scaling 能达到的 batch size 规模仍然有限。在 3.4 中我们更进一步介绍了 LARS,通过归一化各层的梯度来使训练稳定,使得 linear scaling 能达到夸张的 batch size 规模。
3.5 整合了分散在 2.2 以及 3.2-3.3 中的直觉概念—噪声,并介绍了一个初步的分析结果 ,同时分享了一些实验证据。其中
为噪声,
为更新步长,
为训练集样本数,
为 batch size。
4. 展望
深度学习只是在做 pattern recognition:这是近年来不得不回避的事实。现有的模型通常只是学到肤浅的规律。然而就算,只是 pattern recognition,萦绕在深度学习头上的理论阴霾仍未解决。深度神经网络的结构和其表达能力的关系,泛化性能的影响因素,以及对 loss surface 性质的刻画,这些都是难以跨越的大山。所幸近两年来看到了许多进展,作为旁观者的笔者也是觉得 excited。同时笔者也越来越期待超越浅层 pattern recognition 的工作,这也是 NLPer 必须跨越的大山。
5. 参考文献
[Bottou et al, 2008] The Tradeoffs of Large Scale Learning
[Bottou et al, 2018] Optimization Methods for Large-Scale Machine Learning
[Li et al, 2017] Visualizing the Loss Landscape of Neural Nets
[Santurkar et al, 2018] How Does Batch Normalization Help Optimization?
[Krizhevsky, 2014] One weird trick for parallelizing convolutional neural networks
[Lecun, 1998] Efficient backprop
[Keskar et al, 2016] On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
[Hoffer et al, 2017] Train longer, generalize better: closing the generalization gap in large batch training of neural networks
[Hochreiter et al, 1997] Flat Minma
[Goyal et al, 2017] Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
[You et al, 2017] Large Batch Training of Convolutional Networks
[Smith et al, 2017a] A Bayesian Perspective on Generalization and Stochastic Gradient Descent
[Smith et al, 2017b] Don’t Decay the Learning Rate, Increase the Batch Size