目录
6.1 假设 1:与大 Batch Size 极小值相比,小 Batch Size 极小值距离初始权重更远
6.2 假设 2:小 Batch Size 训练会找到更平坦的极小值
七、增大学习率能够改善大 Batch Size 训练的性能吗?
八、 小 Batch Size 训练总是优于大 Batch Size 训练吗?
一、简介
在本文中,我们将试图更好地理解 Batch Size 对训练神经网络的影响,并特别介绍以下内容:
- 什么是 Batch Size?
- 为什么 Batch Size 很重要?
- 经验上,大 Batch Size 和小 Batch Size 分别表现如何?
- 为什么大 Batch Size 倾向于表现更糟,我们如何弥补性能鸿沟?
二、什么是 Batch Size?
注:原文对本节的描述与笔者所学知识有所出入,笔者决定按自身所学来表述,若有谬误望不吝赐教,多谢!
神经网络被训练以最小化以下形式的总损失函数:

其中, 表示模型参数,
表示训练样本总数,
为单个训练样本的下标,
则表示单个训练样本的损失函数。
通常,使用梯度下降法最小化损失函数。梯度下降法计算损失函数相对于参数的梯度,并朝该方向迈出一步。随机梯度下降 (SGD) 在 单个训练样本 上计算梯度,批量梯度下降法 (BGD) 在 整个训练集 上计算梯度,而 小批量梯度下降法 (Mini-Batch GD) 则介于二者之间,在训练集子集 上计算梯度,其参数更新公式为:

是一个采样自训练集的 batch,大小可以从
(SGD) 设到
(BGD),介于二者之间时即为 Mini-Batch GD。我们可以将这些 batch-level 梯度 视为 “真实” 梯度的近似值,即总损失函数相对于参数
的梯度。我们通常使用 趋向于更快收敛的小 batch size,因为它无需计算所有训练集样本的梯度来更新权重。
三、为什么 Batch Size 很重要?
Keskar 等人指出,Mini-Batch GD 下降是连续的且使用小 batch size 的,因此不容易并行化。使用更大的 batch size 将允许更大程度上的并行计算,因为我们 可以在不同的工作节点之间分离训练样本,从而 大大加快模型训练的速度。
然而,较大 batch size 虽能够达到与较小 batch size 相似的训练误差,但往往会产生更糟的测试误差。训练和测试误差之间的差距被称为 “泛化差距”。
因此,“holy grail” 旨在实现使用大 batch size 达到与小 batch size 相同的测试误差。这将允许我们在不牺牲模型准确性的情况下显著加快训练速度。
四、如何设置实验?
我们将使用不同的 batch size 来训练神经网络,并比较它们的性能。

数据集:我们使用猫狗二分类数据集,该数据集由 23262 张猫、狗两类图像各参半组成。我们先将图像调整为相同大小,然后用 20% 的数据集作为验证数据 (开发集),其余作为训练集。
评估指标:我们使用验证数据上的二元交叉熵损失作为衡量模型性能的主要指标。

基本模型:我们定义了一个受 VGG16 启发的基本模型。在该模型中,我们重复使用 Conv + Maxpool 操作,使用 ReLU 作为卷积层激活函数。然后,我们将输出张量展平以馈入两个全连接层,最后是一个带 Sigmoid 激活函数的单神经元层,结果输出介于 0 和 1 之间,指示模型预测的是猫 (0) 还是狗 (1)。
训练:我们用学习率为 0.01 的 SGD 训练,直到验证损失超过 100 次迭代后仍无法改善 (早停)。
五、Batch Size 如何影响训练?
我们用猫狗数据集尝试不同的 batch size 比较性能如何:

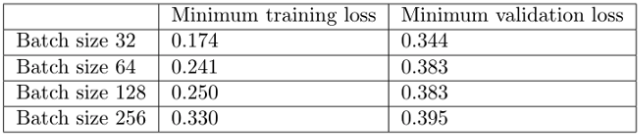

综上可知,batch size 越大:
- 训练损失降低得越慢。
- 最小验证损失越高。
- 每个 epoch 训练所需时间越少。
- 收敛到最小验证损失所需时间越长。
更具体地,首先,大 batch size 训练的损失降低得更慢,如红线 (batch size=256) 和蓝线 (batch size=32) 之间斜率的差异所示。
其次,大 batch size 训练产生了比小 batch size 更糟的最小验证损失。例如,batch size=256 的最小验证损失为 0.395,而 batch size=32 的最小验证损失为 0.344。
第三,大 batch size 训练的每个 epoch 所需时间比小 batch size 稍短 —— batch size=256 为 7.7 秒,而 batch size=256 为 12.4 秒,这反映了与按顺序加载较少数量的大 batch size (而非许多小 batch size) 的相关开销较低。如果使用多 GPU 并行训练,这个时间差会更明显。
然而,大 batch size 训练需要更多的时间才能收敛到一个最小值 —— batch size=256 为 958 epochs,batch size=32 epochs 为 158。正因如此,大 batch size 训练总体上花费的时间更长:batch size=256 的训练花费的时间几乎是 batch size=32 的 4 倍!
注意,此处并未 并行化训练,否则大 batch size 训练可能会像小 batch size 训练一样快。如果将训练并行化会发生什么?为回答该问题,我们用 TensorFlow 中的 MirroredStrategy 在四个 GPU 上并行训练:
with tf.distribute.MirroredStrategy().scope():
# Create, compile, and fit model
# ...MirroredStrategy 将模型的所有变量复制到每个GPU,并将前向/后向传播计算分 batch 分发到所有 GPU。接着,用 all-reduce 合并来自各 GPU 的梯度,然后将结果应用于每个 GPU 的模型副本。本质上,它是划分 batch 并将每个 chunk 分配给GPU。
我们发现,并行化使小 batch size 训练在每个 epoch 上稍慢些,而使大 batch size 训练更快 —— 对于 batch size=256 的训练,每个 epoch 的时间从 7.70 秒减少到 3.97 秒。然而,即便使用每 epoch 加速,它也无法在总训练时间方面与 batch size=32 匹敌 —— 当乘以总 epoch 数 (958) 时,得到约 3700 秒的总训练时间,这仍远大于 batch size=32 的 1915 秒。

到目前为止,大 batch size 训练似乎不值得这么费事,因为需要更长的时间,且会产生更差的训练和验证损失。为什么会这样,有没有办法缩小性能差距?
六、为什么小 Batch Size 表现得更好?
Keskar 等人对 小 batch size 和大 batch size 之间的性能差距 给出了一种解释:小 batch size 的训练往往收敛于平坦的极小值 (flat minimizers),在极小值的一个小邻域内变化很小;而大 batch size 的训练则收敛于急剧变化的尖锐极小值 (sharp minimizers)。平坦极小值倾向于更好的泛化能力,因为它们对训练集和测试集之间的变化更具鲁棒性。

此外,他们发现,与大 batch size 训练相比,小 batch size 训练通常会找到离初始权重较远的最小值。他们解释称,小 batch size 训练可能会引入足够的噪声,以便训练退出尖锐极小值的损失域,并可能找到更远的平坦极小值。
让我们来验证这些假设。
6.1 假设 1:与大 Batch Size 极小值相比,小 Batch Size 极小值距离初始权重更远
我们首先测量 初始权重 和 每个模型找到的极小值 之间的 欧氏距离。


可见,通常,batch size 越大,模型找到的极小值越接近初始权重 (除 batch size=128 比 batch size=64 远离初始权重外)。同时,该结论在模型的不同层中都是适用的。
为什么大 batch size 训练最终会更接近初始权重呢?是因为它使用更小的更新步长吗?让我们通过测量 batch size=32 和 batch size=256 的 epoch 距离 (即 epoch 中的初始权重 (iter=0) 和最终权重 (iter=num_samples/batch_size) 之间的距离) 来找出原因。

以上左图显示,较大的 batch size 确实会在每个 epoch 中移动较少的距离。训练 batch size=32 的 epoch 距离在 0.15 ~ 0.4 之间变化,而训练 batch size=256 的 epoch 距离约为 0.02~0.04。事实上,正如右图所示,epoch 距离的比率 (大 batch size / 小 batch size) 随着时间的推移而增加!
然而,为什么大 batch size 训练在每个 epoch 中移动的距离更小呢?是因为 batch 数更少使得每个 epoch 的更新更少吗?或是因为每次 batch 更新所经过的距离更小?或是两个原因的结合?为回答该问题,我们测量每个 batch 更新的大小 (size)。

Median batch update norm for batch size 32: 3.3e-3
Median batch update norm for batch size 256: 1.5e-3可见,当 batch size 较大时,每个 batch 更新都较小。为什么会这样?
为理解这种行为,让我们建立一个虚拟场景,其中有 两个梯度向量 a 和 b,每个向量代表一个训练示例的梯度。接下来,比较一下 batch size=1 和 2 的平均 batch 更新大小。

如果用 batch size=1,我们将先朝 a 然后朝 b 方向依次迈出一步,最后到达 a+b 表示的点。(从技术上讲,b 的梯度将在应用 a 后重新计算,但现在我们忽略它)。这导致平均 batch 更新大小为 (|a|+|b|) / 2 —— batch 更新大小之和 除以 batch 更新次数。
如果用 batch size=2,那么 batch 更新将一次性迈到 a+b 点,由向量 (a+b) / 2 表示 (图中红色箭头)。因此,平均 batch 更新大小为 |(a+b)/2| / 1 = |a+b| / 2。现在,让我们比较两种平均 batch 更新大小 (看图也能明显看出三角不等式关系):

在最后一行中,我们用三角形不等式来说明 batch size=1 的平均 batch 更新大小始终大于等于 batch size=2 的。换言之,为使 batch size=1 和 batch size=2 的平均 batch 更新大小相等,向量 a 和 b 必须严格指向同一方向 (a 和 b 共线共向)。
更进一步地,将参数扩展到 n 个向量 —— 当且仅当所有 n 个向量都指向同一方向时,batch size=1 和 batch size=n 的平均 batch 更新大小才相同。然而,这种情况 几乎从未发生过,因为 梯度向量不可能都指向完全相同的方向。

回到上图中的 mini-batch 更新方程,在某种意义上可以说,当我们 放大 batch size 时,梯度总和放大的速度相对较慢。这是因为 梯度向量指向了不同的方向 (几乎不存在所有梯度向量共向),因此 batch size 的加倍 (即要加在一起的梯度向量总数) 不会使梯度向量总和加倍。同时,我们将除以一个两倍于
的分母,从而使整个更新步长更小。
以上可以解释为什么 较大 batch size 的 batch 更新往往较小 —— 梯度向量的总和虽然变大了,但不能完全超过或抵消更大的分母 (分子增加的梯度向量的总和仍小于分母的 batch size 绝对值,从而整个分数仍然是小的)。
6.2 假设 2:小 Batch Size 训练会找到更平坦的极小值
现在让我们测量两个极小值的尖锐程度,并评估小 batch size 训练将发现更平坦极小值的说法。注意,第二种假设可以与第一种假设共存 ——二者并非互斥关系。为此,我们参照了 Keskar 等人的两种方法。
在第一种方法中,我们沿着小 batch size 最小值 (batch size=32) 和大 batch size 最小值 (batch size=256) 之间的直线绘制训练和验证损失。该线由以下方程描述:
![]()
其中, 是大 batch size 的极小值,
是小 batch size 的极小值,
是一个介于 -1 和 2 之间的系数。

正如我们在图中所看到的,小 batch size 极小值 () 比大 batch size 极小值 (
) 平坦得多,后者的周围变化更为剧烈/尖锐 (例如右侧激增的 Loss)。
注意,这是一种相当简单的测量尖锐程度方法,因为它 只考虑一个方向。因此,Keskar 等人提出了一种尖锐程度指标,用于度量损失函数在极小值附近的变化程度。首先,我们对 邻域 的定义如下:
![]()
其中 是定义邻域大小的参数,
是极小值 (权重)。然后,我们将 尖锐程度指标 定义为 该极小值周围邻域中的最大损失:
![]()
其中 为损失函数,其输入为权重。根据上述定义,让我们计算不同 batch size 下极小值的尖锐程度,
=1e-3:

上述结果表明,大 batch size 的极小值确实更为尖锐。
最后,让我们试着用 Li 等人提出的滤波器归一化损失 (filter-normalized loss) 可视化来绘制最小值。这种类型的图选择两个维度与模型权重相同的随机方向,然后对每个卷积滤波器 (或 FC 层的神经元) 进行归一化,使其具有与模型权重中相应滤波器相同的范数。这确保了最小化的尖锐程度不受其权重大小的影响。然后,它沿着这两个方向绘制损失图,图的中心是我们希望描述的最小值。


同样,我们可以从等高线图中看到,大 batch size (256, 右) 相对于小 batch size (32, 左) 极小值,损失变化更为剧烈/尖锐。
七、增大学习率能够改善大 Batch Size 训练的性能吗?
在假设 1 中,我们发现对于大 batch size,每个 epoch 的更新大小和更新频率都较低;而在假设 2 中,我们发现大 batch size 无法探索出与小 batch size 一样大的区域。为此,我们是否可以增大学习率来提高大 batch size 训练的效果呢?这种方法之前已经提出过,例如 Goyal 等人的 线性缩放规则:当小 batch size 乘 k 时,学习率也相应乘 k。让我们试试 batch size 为 32、64、128 和 256。对于 batch size=32,我们将用 0.01 的基本学习率,并对其他 batch size 进行相应放缩。
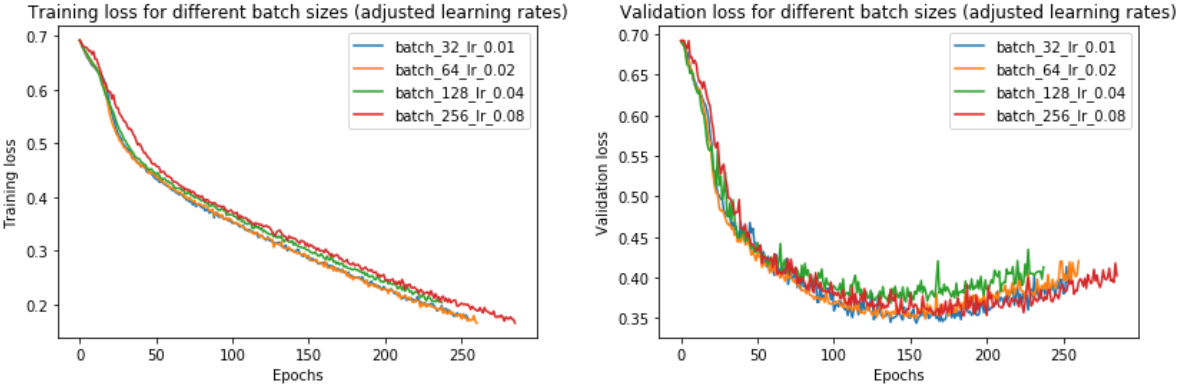

事实上,我们发现 调整学习率确实消除了小 batch size 和大 batch size 之间的大部分性能差距。现在,batch size=256 达到了 0.352 而非 0.395 的验证损失 —— 更接近 batch size=32 的验证损失 0.343。
提高学习率如何影响训练时间?由于大 batch size 训练现在可以 以与小 batch size 训练大致相同的迭代次数 收敛,如上左图所示,因此现在训练所需的总体时间较短,batch size=256 为 2197 秒,而 batch size=32 为 3156 秒。如果我们在 4 个 GPU 上并行化,则加速比更为明显。

但这是否意味着大 batch size 现在正在收敛到平坦的即小值呢?如果绘制尖锐程度分数,可以看到 调整学习率确实会使大batch size 极小值变得更平坦:

有趣的是,尽管调整学习率会使大 batch size 极小值更平坦,但它们仍然比最小 batch size 极小值更尖锐 (介于4–7之间,而非 1.14)。为什么会发生这种情况仍是一个有待进一步调查的问题。大 batch size 的训练运行是否与小 batch size 的训练运行一样远离初始权重?

答案在很大程度上是肯定的。如果我们看上面的图,调整学习率有助于缩小 batch size=32 与其他 batch size 之间在距离初始权重方面的差距。注意,128 似乎是一种异常现象,学习率的提高会缩短距离 —— 为什么会出现这种情况,有待进一步研究。
八、 小 Batch Size 训练总是优于大 Batch Size 训练吗?
鉴于上述观察结果和文献,如果保持学习率不变,可以预期小 batch size 训练总是优于大 batch size 训练。然而,事实并非如此,当使用 0.08 的学习率时,可以看到:
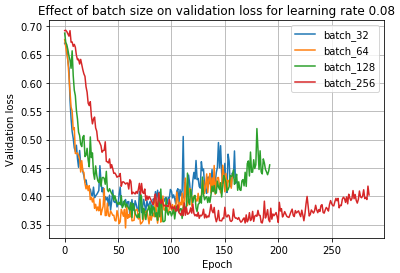
在这里,我们看到 batch size=64 实际上优于 batch size=32!这是因为 学习率和 batch size 密切相关 —— 小 batch size 在学习率较低时表现最好,而大 batch size 在学习率较高时表现最好。我们可以在下面看到这种现象:
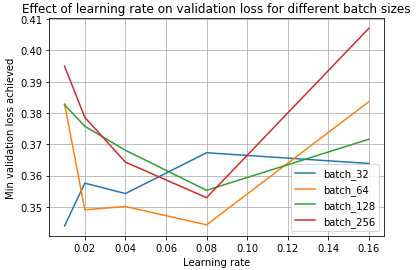
我们发现,学习率 0.01 对 batch size=32 最佳,而学习率 0.08 对其他 batch size 最佳。因此,如果注意到,在相同的学习率下,大 batch size 训练优于小 batch size 训练,这可能表明 大 batch size 训练的最佳学习率 大于 小 batch size 训练的最佳学习率。
九、结论
那么,这一切意味着什么?我们能从这些实验中得到什么?
线性缩放规则:当小 batch size 乘 k 时,学习率也乘 k。虽然我们 最初发现大 batch size 的表现更差,但我们能够通过提高学习率来弥补大部分差距。我们看到这是由于较大的 batch size 应用较小的 batch 更新,以及 batch 内梯度向量之间的梯度竞争。当选择正确的学习率时,较大的 batch 可以更快地训练,尤其是并行化时。对于大 batch size,其较少受到 SGD 更新的顺序性质的限制,因为不会遇到顺序将许多小 batch 加载到内存中的开销。我们还可以跨训练示例并行计算。
然而,当学习率不因较大的 batch size 而向上调整时,大 batch size 训练可能比小 batch size 训练花费更长的时间,因为它需要更多的训练时间来收敛。因此,需要调整学习率,以实现更大 batch size 和并行化的加速。在实验中,大 batch size,即使调整学习率,表现也稍差,但需要更多的数据来确定大 batch size 是否总体表现更差。我们仍然观察到最小 batch size (验证损失0.343) 和最大 batch size (验证损失 0.352) 之间存在轻微的性能差距。一些人认为,小 batch size 具有正则化效果,因为它们在更新中引入噪声,有助于训练避开次优局部极小值的盆地。然而,这些实验的结果表明,性能差距相对较小,至少对于这个数据集是如此。这表明,只要您找到适合 batch size 的正确学习率,您就可以专注于训练的其他方面,这些方面可能会对最终效果产生更大的影响。
参考资料:
https://medium.com/deep-learning-experiments/effect-of-batch-size-on-neural-net-training-c5ae8516e57