李宏毅老师的课件:
http://speech.ee.ntu.edu.tw/~tlkagk/courses/MLDS_2018/Lecture/ForDeep.pdf
B站的课件讲解:
https://www.bilibili.com/video/av9770302/?p=11
大部分内容转载于用户SpareNoEfforts :
https://www.jianshu.com/p/d216645251ce
真的需要认真学习相关内容的可以去上面的几个网址,自行选择学习。对于不太愿意看很长时间的同学,我在这里用最简短的话来阐述。
(sigmoid、tanh和maxout这里就不介绍了)
1. Relu激活函数
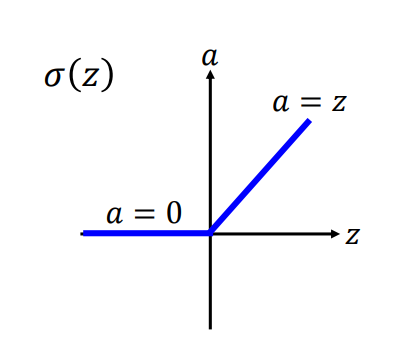
上述的relu是使用最多的一类激活函数了,也就是将传进来的值限制在一个范围。(x小于0即为0,x大于0即y=x计算)
2.Relu变形体:Leaky Relu和Parametric Relu函数
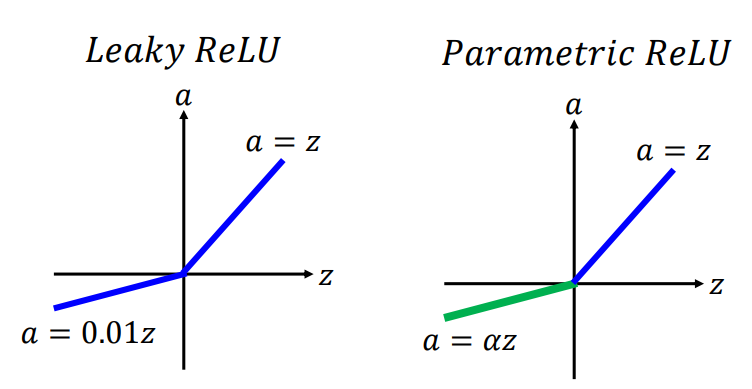
性质一样,参考上面1。
3.转载博主还介绍了个Randomized ReLU函数
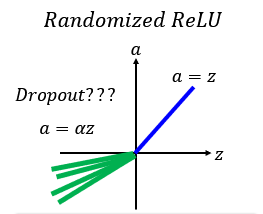
training:的值每一次都不一样。
testing:的值fix。
4.ELU和SELU函数
selu论文地址:https://arxiv.org/abs/1706.02515
为什么单独贴出来呢,因为这篇作者的推导过程在论文中写了97页,
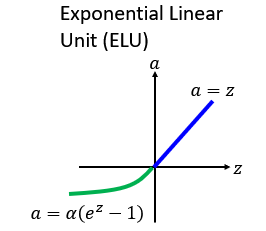
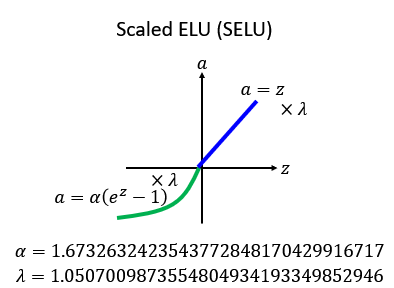
相信大家一下就可以看懂,elu函数也就是将小于0的部分做个处理y=(e^x-1),大于0部分没有做任何改变。而selu函数就是在elu基础上将大于0部分变为了y=
x,加了一个斜率,而这个斜率的值大家可以注意到是大于0的,所以input的值是会被放大的,其中推导过程省去,若是有需要可以参考课件和(https://www.jianshu.com/p/d216645251ce)其中推导内容。
5.GELU
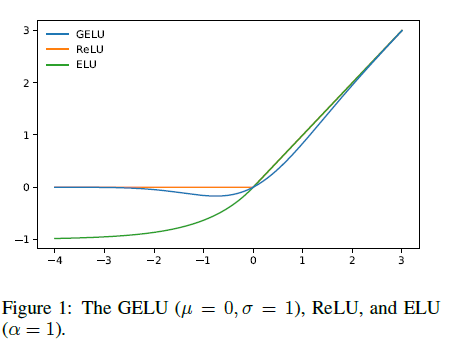
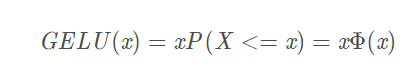
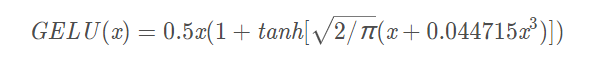
6.SWITH
财大气粗谷歌大脑在selu出了不久就提出了swish激活函数方法,秒杀所有激活函数。
论文地址:https://arxiv.org/abs/1710.05941

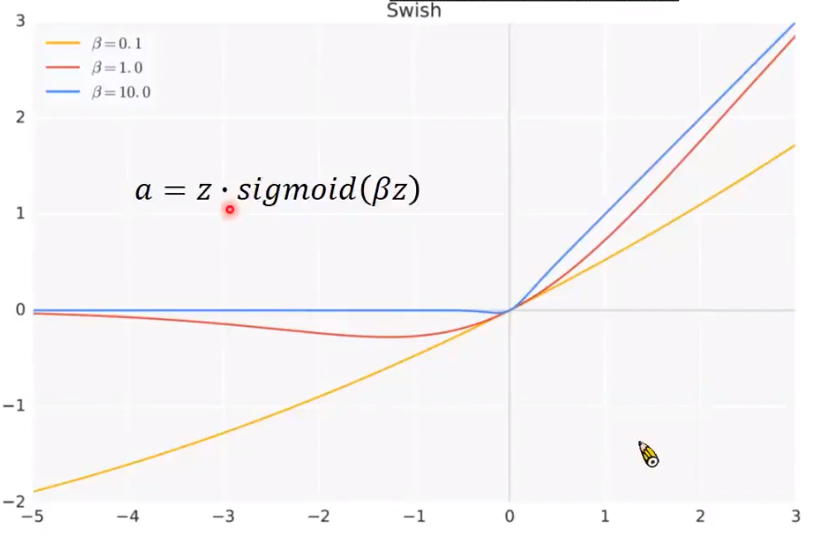
论文中贴出的计算公式为:f(x) = x · sigmoid(βx)
论文中提到的TensorFlow中也有自带的tf.nn.swith(x),但是我发这篇文章之前找了,没有,根本没有。所以只能使用论文中使用的方法,x * tf.sigmoid(beta * x),当然一般beta为1,所以直接x * tf.sigmoid(x)即可。
贴出来论文中的结果:
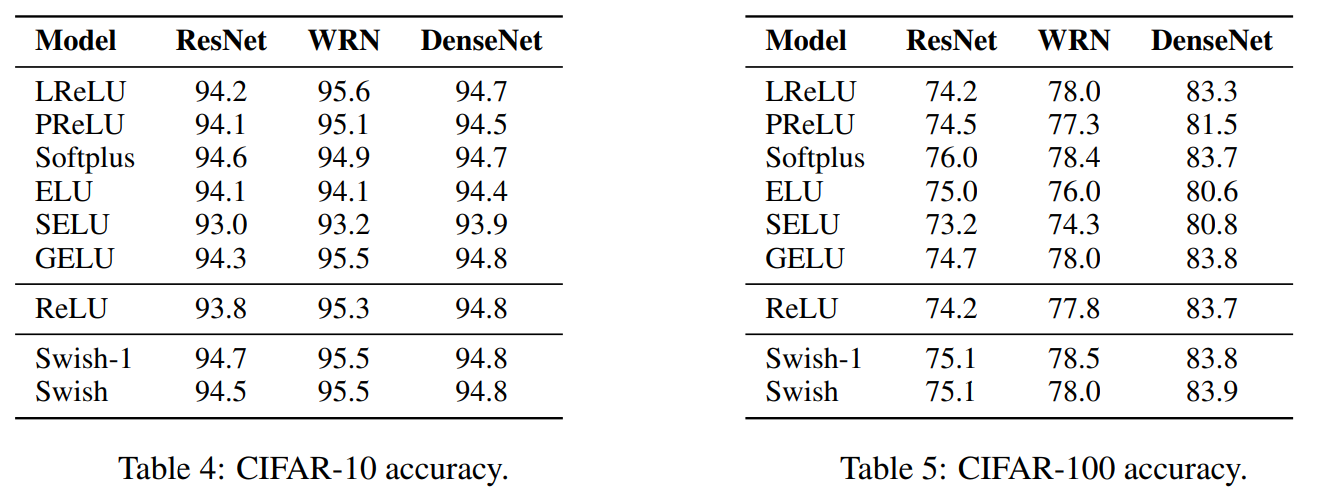
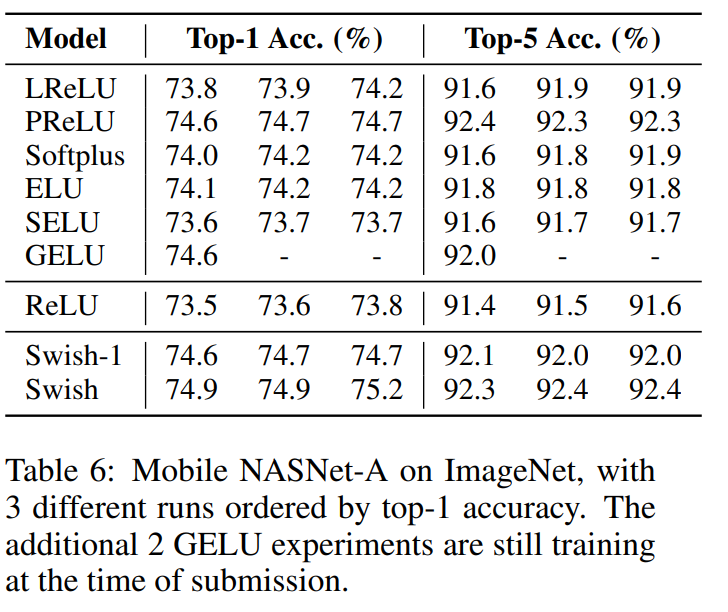
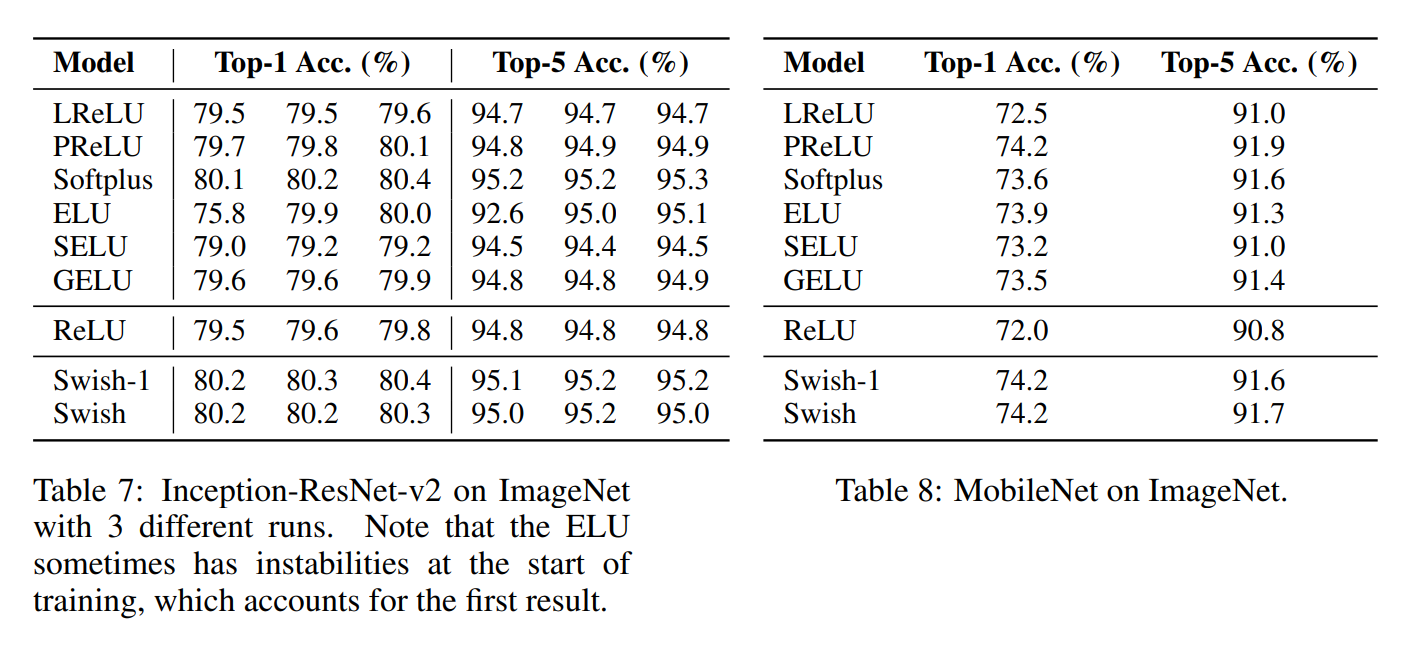
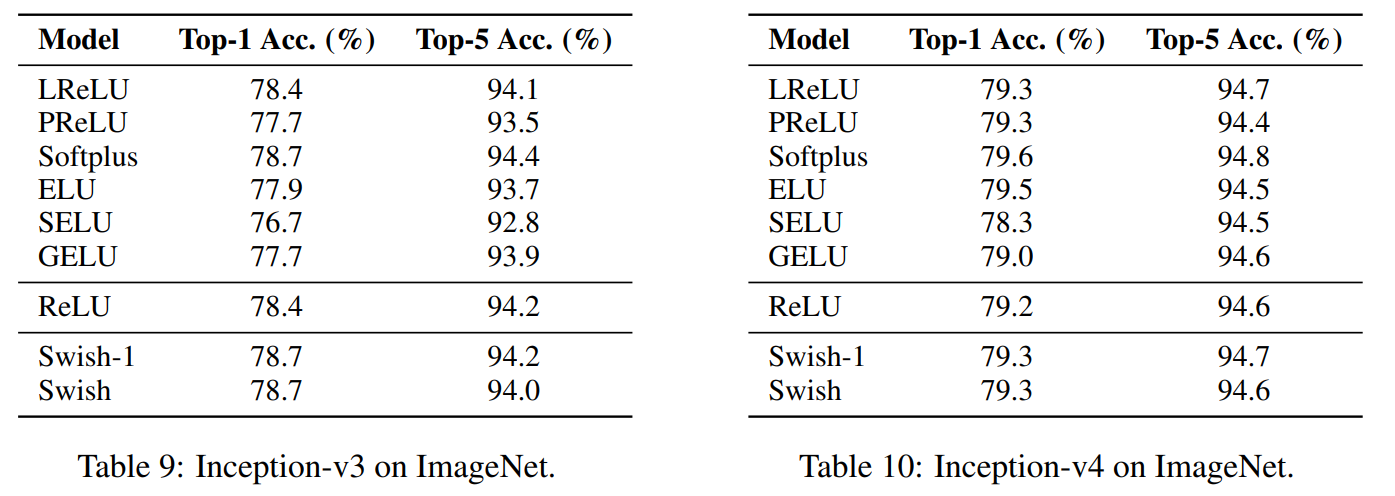
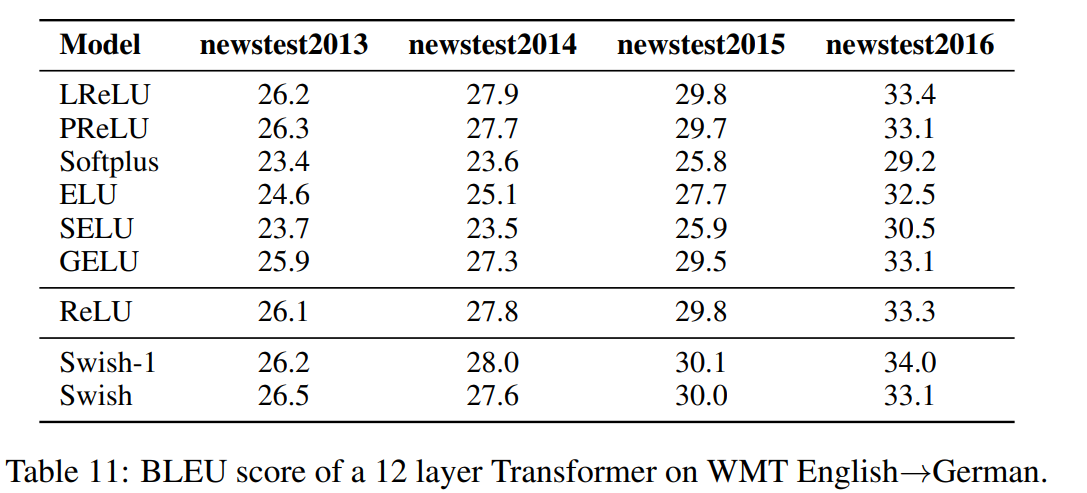
以上结果贴给能看懂得人,不懂得没有关系,我帮你说。
就是说swish的方法要强过其他所有的方法,感觉自己在说废话。其中注意到使用selu和gelu的结果会比较低,甚至比relu的结果还低,这真的很谷歌大脑。
附:
本人的建议是自己去尝试一下,各个方法的实现也不麻烦。接下来我就把基于TensorFlow的方法贴出来,以供参考:
relu函数:tf.nn.relu(features, name=None)
leakyrelu函数:tf.nn.leaky_relu(features, alpha=0.2, name=None)
sigmoid函数:tf.sigmoid( features, name=None )
elu函数:tf.nn.elu( features, name=None )
selu函数:tf.nn.selu(features, name=None) 或者
1 def selu(x): 2 with ops.name_scope('elu') as scope: 3 alpha = 1.6732632423543772848170429916717 4 scale = 1.0507009873554804934193349852946 5 return scale*tf.where(x>=0.0, x, alpha*tf.nn.elu(x))
swish函数:tf.nn.swish(x)或者input=x * tf.sigmoid(beta * x) //beta一般为1
怎么选择激活函数呢?
(转载于明也无涯:https://www.cnblogs.com/makefile/p/activation-function.html)
-
首先尝试ReLU,速度快,但要注意训练的状态.
-
如果ReLU效果欠佳,尝试Leaky ReLU或Maxout等变种。
-
尝试tanh正切函数(以零点为中心,零点处梯度为1)
-
sigmoid/tanh在RNN(LSTM、注意力机制等)结构中有所应用,作为门控或者概率值.
-
在浅层神经网络中,如不超过4层的,可选择使用多种激励函数,没有太大的影响。
只有在实践中才可以找到最适合自己的激活函数。