什么是文档
Elasticsearch是面向文档的,文档是可搜索数据区的最小单元,例如:日志文件中的日志项,一个电影的详细信息等。在Elasticsearch中文档被序列化为包含键值对的 JSON 对象。 一个 键 可以是一个字段或字段的名称,一个 值 可以是一个字符串,一个数字,一个布尔值, 另一个对象,一些数组值,或一些其它特殊类型诸如表示日期的字符串,或代表一个地理位置的对象:
{
"GenTime" : """"2019-12-26 09:13:36"""",
"EventName" : "HTTP_XSS脚本注入",
"EventID" : "152526081",
"SerialNum" : "0113211811149999",
"@timestamp" : "2019-12-26T01:13:36.670Z",
"deamon" : "IPS",
"time" : "Dec 26 09:13:36",
"SMAC" : "f4:15:63:d4:3a:05",
"EventLevel" : "2",
"EventsetName" : "All",
"SecurityID" : "28",
"SrcPort" : "65320",
"Action" : "PASS Vsysid=0",
"syslog5424_pri" : "212",
"DstIP" : "10.3.160.112",
"EvtCount" : "1",
"Protocol" : "TCP",
"InInterface" : "ge0/3"
}
文档元数据
元数据是丰富文档的相关信息
... { "_index" : "ips-event2019.12.26", "_type" : "_doc", "_id" : "UYHEP28BhfJeQd0SJfMF", "_score" : 1.0, "_source" : { "GenTime" : """"2019-12-26 09:13:36"""", "EventName" : "HTTP_XSS脚本注入", "EventID" : "152526081", ..... }
- _index 文档所属索引名称
- _type 文档所属的类型名
- _id 文档唯一id
- _score 相关性打分
- _source 文档的原始数据
什么是索引
索引是文档的容器,是一类相似文档的集合
- Index体现了逻辑空间的概念,每个索引都有自己的mapping定义,用于定义包含的文档的字段名和字段类型
- Shard 体现物理空间的概念,索引中的数据分散到各个Shard上
索引的Mapping和Setting
- Mapping是定义索引中的所有文档中的字段类型
- Setting是定义数据的不同分布
常见API使用
以下可以在DevTools中实验
#查看索引相关信息,可以看到Mapping和Setting的定义 GET movies #查看索引的文档总数 GET movies/_count #查看索引前10条文档 GET movies/_search { }
节点
master节点
- 每一个节点启动后,默认就是mastrt eligible节点(可以设置node.master: flase 禁止)
- mastrt eligible节点可以参加选主流程,成为master节点
- 当第一个节点启动时,它将会把自己选举成master节点
- 每一个节点都保存集群状态,只有master节点才能修改集群的状态
- 集群状态,维护一个集群中的必要信息
- 所有节点信息
- 所有索引和其相关的Mapping和Setting信息
- 分片的路由信息
- 集群状态,维护一个集群中的必要信息
Data节点
- 可以保存数据的节点,负责保存分片数据,在数据扩展中起到了至关重要的作用
Coordianting 节点
- 负责接收Clent端的请求,将请求分发到合适的节点,最终把结果汇集到一起
- 每个节点默认都起到了Coordianting Node的职责
Hot & warm节点
- 不同硬件配置的Data Node。把热门索引或者近期索引放在高配置节点(Hot节点)上,反而冷门索引和相对久远的数据放到低配置节点(warm节点)上。从而节省资源
Machine Learning 节点
- 用来跑机器学习的job,来发现数据中的异常
配置节点类型
- 开发环境中一个节点可以承担多个角色
- 生产环境,应该设置单一的角色节点
| 节点类型 | 配置参数 | 默认值 |
| master eligible | node.master | true |
| data | node.data | true |
| ingest | node.ingest | true |
| Coordianting only | 无 | 每个节点默认都是Coordianting。设置其他类型为false |
| machine learning |
node.ml | true(需要enable x-pack) |
分片
分片分为两种,主分片和副本:
主分片用于解决数据水平扩展的问题,通过主分片,可以将数据分布到集群内的所有节点之上
- 一个分片是一个运行的Lucene实例
- 主分片数在索引创建时指定,后续不允许修改,除非Reindex
副本用以解决数据高可用的问题,分片是主分片的拷贝
- 副本分片数,可以动态调整
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
查看一个三节点集群的分片和副本的分布情况:
创建一个三分片一副本的索引:

查看分布情况:
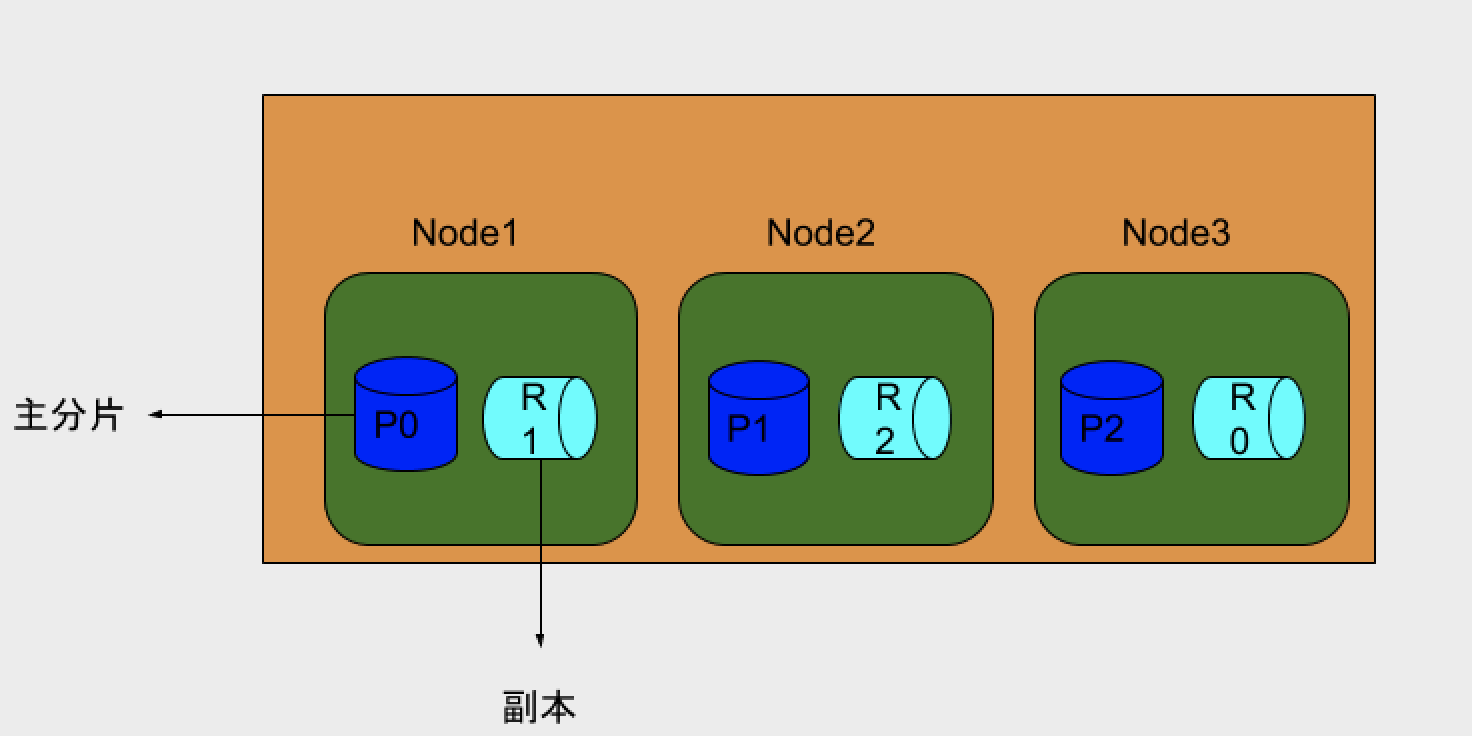
分片设定
对于生产的分片设定,需要提前设计好容量规划
- 分片数设置过下
- 导致后续无法增加节点实现水平扩展
- 单个分片数据量过大,导致数据重新分片耗时
- 分片数设置过大,7.0之后,默认主分片是1,解决了over-sharding的问题
- 影响搜索结果的相关性打分,影响统计结果的准确性
- 单个节点上过多分片,会导致资源浪费,同时会影响性能
集群监控状态说明:
GET _cluster/health { "cluster_name" : "Sxp-Ops-ES-Cluster", "status" : "green", "timed_out" : false, "number_of_nodes" : 3, "number_of_data_nodes" : 3, "active_primary_shards" : 10, "active_shards" : 20, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }
Green
- 主分片和副本分配正常
Yellow
- 主分片全部正常,有副本未能正常分配
Red
- 有主分片未能分配
文档的CRUD
| Index | PUT myindex/_doc/1 |
| Create | PUT myindex/_create/1 POST myindex/_doc(不指定ID 自动生成) |
| Read | GET myindex/_doc/1 |
| Update | POST myindex/_update/1 |
| Delete | DELETE myindex/_doc/1 |
创建文档
#创建文档POST方法 POST jaxzhai/_doc { "user": "jaxzhai", "Postdate":"20191226T20:23", "message":"This test create doc" } #指定ID存在 就报错 PUT jaxzhai/_doc/1?op_type=create { "user": "jax", "Postdate":"20191226T20:26", "message":"This test create doc" }
获取一个文档
#获取一个文档,通过ID GET jaxzhai/_doc/1
执行结果
{ "_index" : "jaxzhai", "_type" : "_doc", "_id" : "1", "_version" : 1, "_seq_no" : 1, "_primary_term" : 1, "found" : true, "_source" : { "user" : "jax", "Postdate" : "20191226T20:26", "message" : "This test create doc" } }
PUT更新一下文档 通过ID
PUT jaxzhai/_doc/1 { "user": "zhaikun" } #执行结果 { "_index" : "jaxzhai", "_type" : "_doc", "_id" : "1", "_version" : 2, "result" : "updated", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 2, "_primary_term" : 1 }
我们看到version发生变化
源文档增加字段
#增加字段 POST jaxzhai/_update/1/ { "doc":{ "postdate":"20191226T20:34", "message":"This test update" } } #执行结果 { "_index" : "jaxzhai", "_type" : "_doc", "_id" : "1", "_version" : 3, "result" : "updated", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 3, "_primary_term" : 1 } #GET结果 { "_index" : "jaxzhai", "_type" : "_doc", "_id" : "1", "_version" : 3, "_seq_no" : 3, "_primary_term" : 1, "found" : true, "_source" : { "user" : "zhaikun", "postdate" : "20191226T20:34", "message" : "This test update" } }
BULK API
BULK API是一次调用中执行多种操作,这样节省网络开销
支持以下4种操作:
- Create
- Update
- Index
- Delete
可以在URI中指定Index 也可以在请求的Playload中进行
操作中单条失败,并不会影响其他操作
返回结果包含每条执行结果
#Bulk POST _bulk {"index":{"_index": "test","_id":"1"}} {"field1":"v1"} {"delete":{"_index": "test","_id":"2"}} {"create":{"_index": "test2","_id":"3"}} {"field1":"v3"} {"update":{"_index": "test","_id":"1"}} {"doc":{"field2":"v2"}} #执行结果 { "took" : 184, "errors" : false, "items" : [ { "index" : { "_index" : "test", "_type" : "_doc", "_id" : "1", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1, "status" : 201 } }, { "delete" : { "_index" : "test", "_type" : "_doc", "_id" : "2", "_version" : 1, "result" : "not_found", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 1, "_primary_term" : 1, "status" : 404 } }, { "create" : { "_index" : "test2", "_type" : "_doc", "_id" : "3", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1, "status" : 201 } }, { "update" : { "_index" : "test", "_type" : "_doc", "_id" : "1", "_version" : 2, "result" : "updated", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 2, "_primary_term" : 1, "status" : 200 } } ] }
批量读取 mget
GET /_mget { "docs":[ { "_index": "test", "_id": "1" }, { "_index": "test", "_id": "2" } ] } #执行结果 { "docs" : [ { "_index" : "test", "_type" : "_doc", "_id" : "1", "_version" : 2, "_seq_no" : 2, "_primary_term" : 1, "found" : true, "_source" : { "field1" : "v1", "field2" : "v2" } }, { "_index" : "test", "_type" : "_doc", "_id" : "2", "found" : false } ] }
常见错误返回
| 问题 | 原因 |
| 无法连接 | 网络故障或集群挂了 |
| 连接无法关闭 | 网络故障或节点错误 |
| 429 | 集群过于繁忙 |
| 4xx | 请求体格式错误 |
| 500 | 集群内部错误 |