Lucene是一个由Java语言开发的开源全文检索引擎工具包。把Lucene用Netty封装成服务,使用JSON访问就是Elasticsearch。
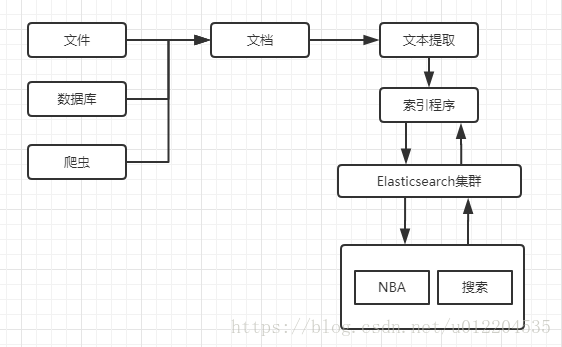
Elasticsearch内置了对分布式集群和分布式索引的管理,所以相对Solr来说,不需要额外安装ZooKeeper,其更容易分布式部署。使用Elasticsearch的搜索系统整体架构如下图所示:
Elasticsearch的每一个运行实例称为一个节点,既可以在同一台计算机上运行多个实例,也可以在每台计算机上只运行一个实例。
在一个分布式系统里,多个Elasticsearch运行实例可以组成一个集群(cluster),该集群里有一个动态选举出来的主节点(master)。如果主节点失败,会自动选出新的节点作为主节点,所以不存在单点故障。
在同一个子网中,只需要在每个节点上设置相同的集群名,这些集群名相同的节点会自动组成一个集群。Elasticsearch包含了节点和节点之间通信模块及节点之间的数据分配和平衡模块。
为了实现容错,Elasticsearch会把查询文档集合分解为多个小的索引,每一个小的索引就叫做分片(shards)。每一个分片都可以有0到多个副本(replicas),而每一个副本也都是分片的完整复制品,这样也提高了查询速度。
一旦Elasticsearch的某个节点数据损坏或服务不可用的时候,就可以用其他节点来代替坏掉的节点,以达到高可用的目的。当有节点加入或退出时,主节点会根据机器的负载对索引分片进行重新分配,当“挂掉”的节点再次重新启动的时候也会进行数据恢复(recovery)。
Elasticsearch通过网关(Gateway)来管理集群恢复,可以配置集群需要加入多个节点才能启动恢复数据。网关配置用于恢复任何失败的索引。当节点奔溃并重新启动时,Elasticsearch将从网关读取所有的索引和元数据。
Transport代表Elasticsearch内部的节点或者集群与客户端之间的交互方式,默认使用TCP协议进行交互,同事支持HTTP协议(JSON格式)、thrift、Servlet、Memcached、ZeroMQ等多种的传输协议(通过插件方式集成)。
为了让集群在运行时动态附加额外的功能,可以使用插件机制加载实现公共接口的程序集。Elasticsearch插件用于各种特定的方式扩展基本的Elasticsearch功能。
笔记:Elasticsearch基本概念
版权声明: https://blog.csdn.net/u012204535/article/details/82956065
猜你喜欢
转载自blog.csdn.net/u012204535/article/details/82956065
今日推荐
周排行