在使用之前,先介绍组件Flume的特点和一些组件
Flume的优势:
1. Flume可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase
2. 当收集数据的速度超过将写入数据的时候,也就是当收集信息遇到峰值时,这时候收集的信息非常大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供平稳的数据.
3. 提供上下文路由特征
4. Flume的管道是基于事务,保证了数据在传送和接收时的一致性.
5. Flume是可靠的,容错性高的,可升级的,易管理的,并且可定制的。
Flume的特征:
1. Flume可以高效率的将多个网站服务器中收集的日志信息存入HDFS/HBase中
2. 使用Flume,我们可以将从多个服务器中获取的数据迅速的移交给Hadoop中
3. 除了日志信息,Flume同时也可以用来接入收集规模宏大的社交网络节点事件数据,比如facebook,twitter,电商网站如亚马逊,flipkart等
4. 支持各种接入资源数据的类型以及接出数据类型
5. 支持多路径流量,多管道接入流量,多管道接出流量,上下文路由等
6. 可以被水平扩展
============================================================================================================================================================
Flume的三个组件:
1、Source
是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。 Flume提供了很多内置的Source, 支持 Avro, log4j, syslog 和 http post(body为json格式)。可以让应用程序同已有的Source直接打交道,如AvroSource 如果内置的Source无法满足需要, Flume还支持自定义Source。
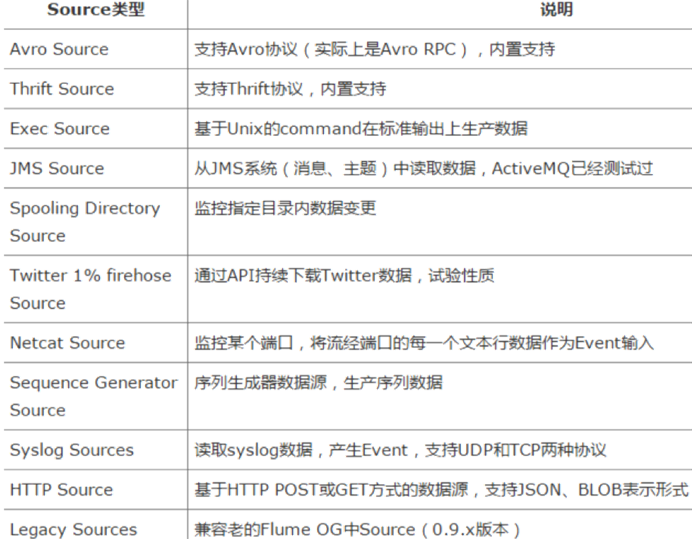
source的类型:
Source具体作用:
AvroSource:监听一个avro服务端口,采集Avro数据序列化后的数据;
Thrift Source:监听一个Thrift 服务端口,采集Thrift数据序列化后的数据;
Exec Source:基于Unix的command在标准输出上采集数据;
JMS Source:Java消息服务数据源,Java消息服务是一个与具体平台无关的API,这是支持jms规范的数据源采集;
Spooling Directory Source:通过文件夹里的新增的文件作为数据源的采集;【测试header】
Kafka Source:从kafka服务中采集数据。
NetCat Source: 绑定的端口(tcp、udp),将流经端口的每一个文本行数据作为Event输入
HTTP Source:监听HTTP POST和 GET产生的数据的采集
=================================================================================================================================================
2、Channel
Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件。
介绍两个较为常用的Channel : MemoryChannel和FileChannel。

Channel:一个数据的存储池,中间通道。
主要作用:接受source传出的数据,向sink指定的目的地传输。Channel中的数据直到进入到下一个channel中或者进入终端才会被删除。当sink写入失败后,可以自动重写,不会造成数据丢失,因此很可靠。 channel的类型很多比如:内存中、jdbc数据源中、文件形式存储等。
常见采集的数据类型: Memory Channel、File Channel、JDBC Channel、Kafka Channel等
详细查看: http://flume.apache.org/FlumeUserGuide.html#flume-channels
Channel具体作用:
Memory Channel:使用内存作为数据的存储。
JDBC Channel:使用jdbc数据源来作为数据的存储。
Kafka Channel:使用kafka服务来作为数据的存储。
File Channel:使用文件来作为数据的存储。
Spillable Memory Channel:使用内存和文件作为数据的存储,即:先存在内存中,如果内存中数据达到阀值则flush到文件中。
=============================================================================================================================================================
3、Sink
Sink从Channel中取出事件,然后将数据发到别处,可以向文件系统、数据库、 hadoop存数据, 也可以是其他agent的Source。在日志数据较少时,可以将数据存储在文件系统中,并且设定一定的时间间隔保存数据。
Sink:数据的最终的目的地.
主要作用:接受channel写入的数据以指定的形式表现出来(或存储或展示)。 sink的表现形式很多比如:打印到控制台、hdfs上、avro服务中、文件中等。
常见采集的数据类型: HDFS Sink、Hive Sink、Logger Sink、Avro Sink、Thrift Sink、File Roll Sink、HBaseSink、Kafka Sink等
详细查看: http://flume.apache.org/FlumeUserGuide.html#flume-sinks HDFSSink需要有hdfs的配置文件和类库。
一般采取多个sink汇聚到一台采集机器负责推送到hdfs。
Sink具体作用:
HDFS Sink:将数据传输到hdfs集群中。
Hive Sink:将数据传输到hive的表中。
Logger Sink:将数据作为日志处理(根据flume中的设置的日志的级别显示)。
Avro Sink:数据被转换成Avro Event,然后发送到配置的RPC端口上。
Thrift Sink:数据被转换成Thrift Event,然后发送到配置的RPC端口上。
IRC Sink:数据向指定的IRC服务和端口中发送。
File Roll Sink:数据传输到本地文件中。
Null Sink:取消数据的传输,即不发送到任何目的地。
HBaseSink:将数据发往hbase数据库中。
MorphlineSolrSink:数据发送到Solr搜索服务器(集群)。
ElasticSearchSink:数据发送到Elastic Search搜索服务器(集群)。
Kafka Sink:将数据发送到kafka服务中。
Flume 使用事务性的方式保证传送Event整个过程的可靠性。
Sink 必须在Event 被存入Channel 后,或者,已经被传达到下一站agent里,又或者,已经被存入外部数据目的地之后,才能把 Event 从 Channel 中 remove 掉。这样数据流里的 event 无论是在一个 agent 里还是多个 agent 之间流转,都能保证可靠,因为以上的事务保证了 event 会被成功存储起来。比如 Flume支持在本地保存一份文件 channel 作为备份,而memory channel 将event存在内存 queue 里,速度快,但丢失的话无法恢复。