参考
https://zh.wikipedia.org/wiki/%E5%AD%97%E8%8A%82%E5%BA%8F
https://www.ruanyifeng.com/blog/2016/11/byte-order.html
https://blog.csdn.net/XiyouLinux_Kangyijie/article/details/72991235
字节顺序,又称端序或尾序(英语:Endianness),在计算机科学领域中,指存储器中或在数字通信链路中,组成多字节的字的字节的排列顺序。
在几乎所有的机器上,多字节对象都被存储为连续的字节序列。例如在C语言中,一个类型为int的变量x地址为0x100,那么其对应地址表达式&x的值为0x100。且x的四个字节将被存储在存储器的0x100, 0x101, 0x102, 0x103位置。[1]
字节的排列方式有两个通用规则。例如,一个多位的整数,按照存储地址从低到高排序的字节中,如果该整数的最低有效字节(类似于最低有效位)在最高有效字节的前面,则称小端序;反之则称大端序。在网络应用中,字节序是一个必须被考虑的因素,因为不同机器类型可能采用不同标准的字节序,所以均按照网络标准转化。
今天在调试的时候,突然想到了这个。结果发现,原理是知道,但是具体大小端是什么意思?网络序是大端还是小端?如何判断系统是否是大小端?发送网络序的时候如何设置数据?都不能详细的描述出来,所以写一篇博客总结一下。
小端就是默认有效值所在的地址空间是初始地址(低地址),大端就是默认有效值所在的地址是高地址。这样更好理解一些。
比如我们有一个int类型的数据,需要占用4个字节,那么如果保存一个1,这个1所在的位置是放到4个字节的哪一个呢?这必须要有一个统一的标准。小端的标准就是放到低地址,大端的就是放到高地址。
Windows系统在x86-64下是小端,我们定义一个整数为1,看一下内存,1放在了低地址。

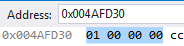
第一个问题解决了,那么网络序呢?网络序使用的是大端标准。那么对我们有什么影响呢? 如果是同一平台(网络传输双方都是大端或是小端),双方可以不用考虑大小端,直接发送接收就可以(当然这是不标准的)。因为数据发送就是发送,是一个数据流,abcdef发送过去,接收也是abcdef,数据没有变化。但是如果不同的平台,比如abcdef在我的平台保存序列就是badcfe,那么发送就是badcfe,接收也是badcfe,如果是同一平台,那么我认为badcfe就是abcdef,那么是无所谓的,如果是不同平台,我认为badcfe是badcfe,那么数据就乱了。所以网络字节序规定了一个标准,大家都按照这样存储,都按照这样转换,那么不同平台就可以互通了。比如小端abcdef在网络字节序上是badcfe,如果是小端接收,那么获得数据badcfe知道是大端,那么就转换成自己的abcdef,大端系统接收到badcfe,同样知道是大端,与自己一样,就不需要转换直接保存badcfe,也表示abcdef,这样数据就没有乱掉了。
最后一个问题就是,如何判断系统是大端还是小端,如果知道原理,那么就简单了
int a = 1; if (*((char*)&a) == 1) { cout << "little"; }
上面就是赋值1给a,a是一个int类型,占用4个字节,如果是小端,那么1应该先放到低地址;如果是大端,那么 1应该放到高地址。(char*)&a是把a的指针强转成一个char的指针,那么默认指的位置也就是低地址,低地址的第一个字节如果保存的是1,那么就是小端,如果不是1,就是大端。