本篇将以what,why,how三个维度讲述字节序
what
字节序,字面理解可知是字节(Byte)的顺序,是计算机科学针对多字节结构(变量或者文件等)的一种约定,目前分为大端字节序和小端字节序
以一个 uint32_t 的4字节类型为例,在该类型的变量中存入0x12345678,从变量的角度来看,0x12为变量的高字节,0x78为变量的低字节。
当变量的 高 字节存放在内存的 高 地址,变量的 低 字节存放在内存的 低 地址时,为小端字节序,如下图:
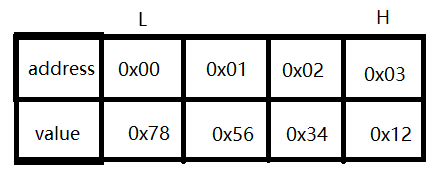
当变量的 高 字节存放在内存的 低 地址,变量的 低 字节存放在内存的 高 地址时,为大端字节序,如下图:
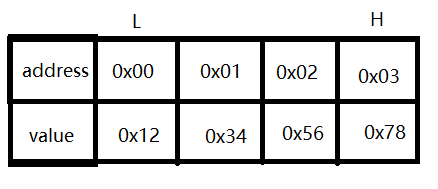
why
定义只是约定,当然可以直接记忆,但是为什么要这么约定?为什么要分成两种字节序?有什么好处?
两种字节序针对两类对象,大端字节序 面向的是 人类,小端字节序 面向的是 计算机。
大端字节序符合人类阅读的习惯,对字节流的处理也是按照阅读习惯来定义,这样能减少人类的处理负担,因此如网络字节序用的就是大端字节序,当网络socket传输一个多位数时,按照阅读习惯,接收到的是高字节数,因此直接左移8位相加。
小端字节序符合计算机处理的顺序
1.计算机读取数据不关心格式,仅按照内存地址顺序读取
2.计算机处理数据从数据低位开始处理,这个也是计算机设计定义的,因此我们需要把变量低地址的数据主动放到内存低地址处,这样计算机取到数据处理才是我们所期望的从低地址开始。如累加操作时,个位相加,进位置位CF,再做十位相加,依次进行累加最终得到结果。
综上,大端字节序面向人类为了简化思维,小端字节序面向计算机为了加快处理速度。
how
如何判别计算机是大端字节序还是小端字节序?
可以简单的用一段C语言程序做判断
#include <cstdio>
#include <cstdint>
int main()
{
uint32_t test_code = 0x12345678;
uint8_t* first = (uint8_t*)&test_code; //指针指向变量的内存首字节
printf("first address value is %x,is %s\n",
*first, *first == 0x12 ? "Big Endian" : "Little Endian");
return 0;
}可以看到输出为
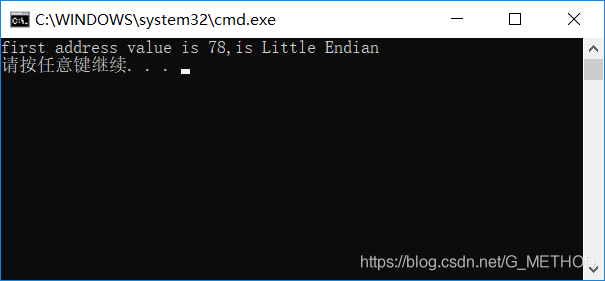
first指针指向了变量test_code的内存首地址(内存低地址),取出的结果为0x78(变量低地址),由上文定义可知为小端序
除了直接查看输出,我们还能通过查看内存方式自己看看存储的情况,这里使用ollyDbg调试上述程序debug模式输出的exe文件,使用ollyDbg打开该exe文件:

右键搜索程序中所有的字符串,这里主要要找printf中的字符串,因为是简单程序没有加密,很容易能够找到调用的地方:
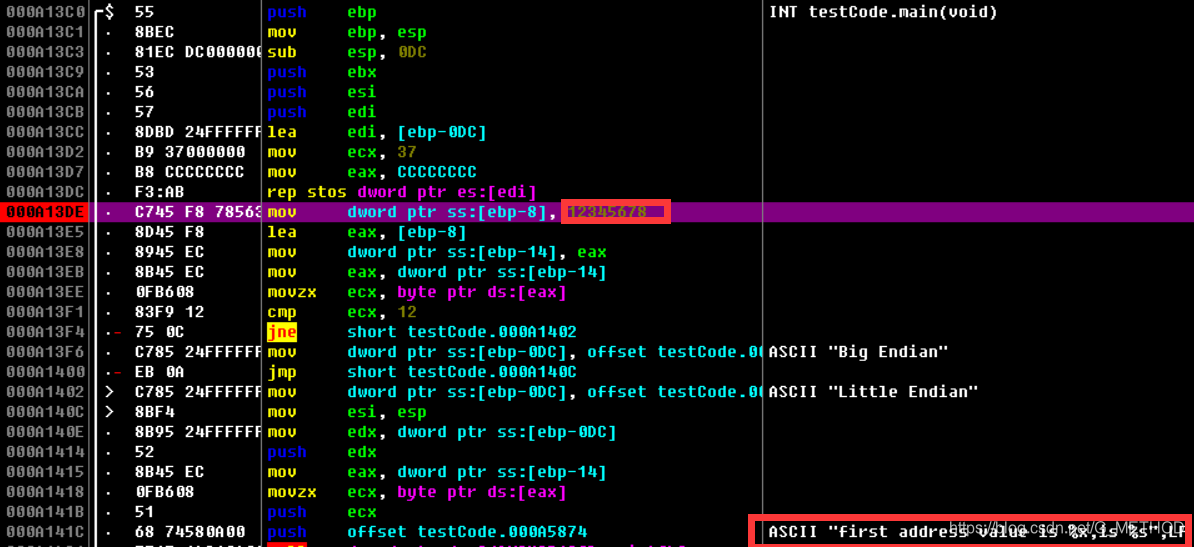
直接查看该变量地址的dump
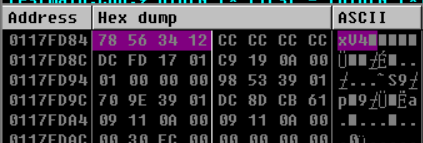
与程序输出一直,低地址存放着0x78,高地址存放着0x12,因此为小端序。
