标题:PointRend: Image Segmentation as Rendering
链接:http://arxiv.org/abs/1912.08193
概要
尽管从题目感觉和渲染有联系,但其实现和渲染相关技术并没有什么联系。论文要解决的是图像分割质量问题,往往图像分割在物体边界处的分割质量很差,不能细致的分割出每个细节。因此作者提出了针对目标轮廓进行细化预测的一个模型:PointRend,其思想是以迭代的方式细化从目标轮廓区域选择的点的分割预测,从而提升目标轮廓分割质量。提出的模型适用于实例分割和语义分割,能预测清晰的目标轮廓,同时也提升了相应的分割精度。如下图,每一步对平滑区域进行双线性上采样,对那些有可能是物体边界的少量点进行高分辨率预测。
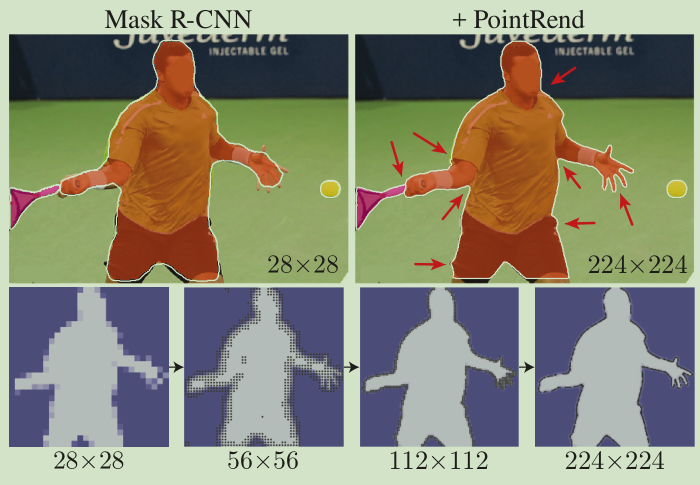
作者认为图像或者特征这种规则的像素网格在进行预测时,不可避免的在平滑区域过采样,在物体轮廓欠采样。个人理解是将预测的低分辨率特征上采样到原始尺寸时,平滑区域像素较多而轮廓边缘的像素较少,所以造成在平滑区域得到很好的预测,而在目标轮廓的预测却很不精细。
方法
PointRend模块包含3个部分:(1)点选择策略(预测和训练时的策略不同),对少量选择的点预测其在高分辨率图中的类别;(2)对选择的每个点的特征表示。(3)point head。根据每个点的特征表示预测类别标签
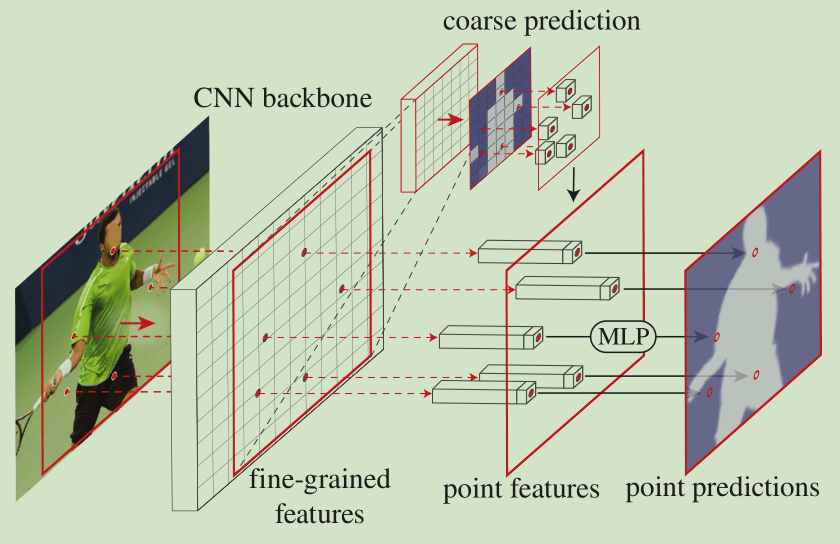
首先是每个点的特征表示。将两种不同的特征(细粒度特征和粗预测特征)拼接作为每个点的特征表示。个人理解这些点是从粗预测中选择得到,然后映射到细粒度特征图中,如上图。细粒度特征图是原图尺寸,对每一个映射的点采用双线性插值得到对应点的细粒度特征,提取出的是多通道单个点的特征,细粒度特征具有物体的细节信息。粗预测特征对于实例分割来说是从RoI特征经过预测得到的K类别Mask中进行插值提取。粗预测特征提供更多的上下文信息,同时表达语义类别。最后拼接作为每个点的最终特征表示。
然后是Point Head。给定每个点的特征表示,采用MLP进行分割预测,预测点的类别标签。
最后看选择策略。如下图所示,预测阶段每一次迭代选择N个最不确定的点(比如置信度接近0.5的点)计算特征表示,然后预测标签。
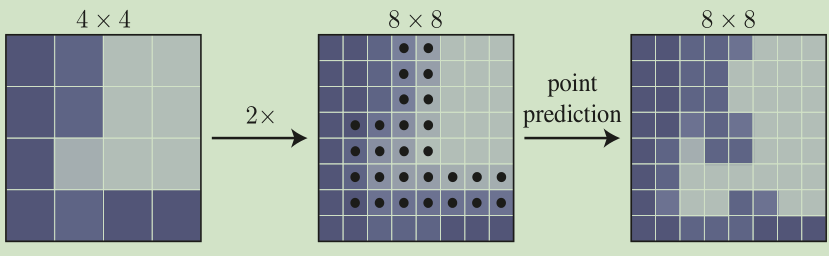
训练阶段的策略与预测阶段不同,如下图所示。有三个原则:(1)生成更多的点:以均匀分布取kN个点(k>1)。(2)关注于那些不确定的粗预测点,通过对kN个点进行插值并计算了一个针对特定任务的不确定性估计,然后选择最不确定的$\beta$N个点(3)剩下的$1-\beta$个点从均匀分布中选取。这种策略更偏重于那些不确定的区域,也就是物体轮廓。

实例分割实验
**粗预测head **改变了Mask R-CNN的Mask head。首先从FPN的P2层通过双线性插值的方法提取$14\times14$RoI特征,接着是$2\times 2$的卷积输出尺寸$7\times7$,最后两个1024隐含层生成$7\times7$的K个类别的Mask粗预测。
PointRend 拼接两部分特征:一个是从上述Mask粗预测特征插值提取的K维特征向量;另一个是从FPN的P2层插值提取的256维特征向量。使用3层隐含层进行预测,每一层又加上K维的粗预测特征作为补充。
训练阶段在粗预测特征中,根据各个点插值后的类别概率到0.5的距离进行选择,距离越小越不确定。损失是针对所有点的二值交叉熵之和。另外,训练阶段box和mask分支并行,预测时候串行,还发现训练时的串行不能提高性能。
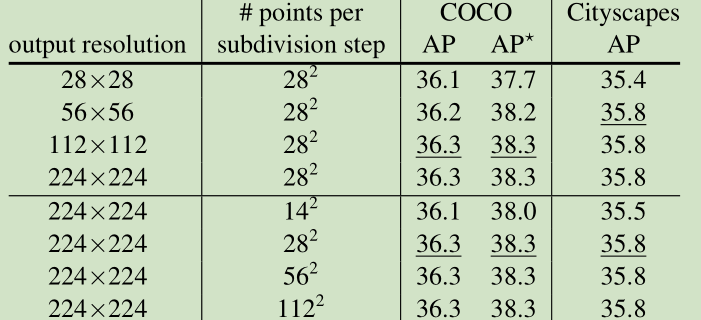
预测阶段对$7\times7$的预测细化5次至$224\times224$。选择点的策略根据各点预测值与0.5的差绝对值。

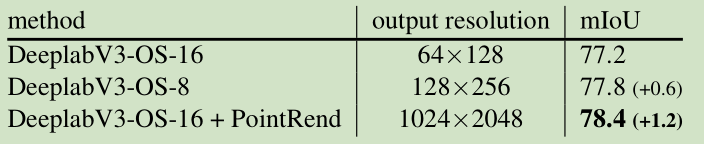
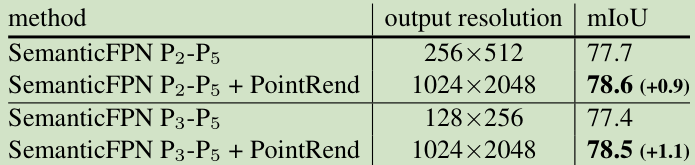
语义分割实验
在DeepLabV3和SematicFPN上做了实验,实现细节基本与实例分割差不多,粗预测特征和细粒度特征对应语义结果和从backbone中特征。有一些细节不同,N = 8096;预测和训练阶段的不确定性估计都采用相同的策略:根据最高置信度和第二置信度之间的插值进行选择点。