![]()
大学生创新创业项目-天津市级
The project was set up in TianJin Normal University. 2019-04
项目名称:智取乐食
项目介绍:
"智取乐食"利用RFID射频识别技术、称重传感器、大数据分析和数据挖掘技术,设计一款集Web端、微信小程序后台算法于一体的项目。实现
餐饮食品自动扣费、每日膳食推荐、个人饮食喜好设置、特色菜品推荐、食物销量预测等功能。项目有效缓解高校食堂食品浪费
现象严重,提高学生饮食质量,发挥人性化餐饮服务和科学合理节约的特色。
项目特点:
在软件上,使用微信小程序使用户使用更加便捷,利用大数据技术减少食物浪费并进行人性化推荐;
在硬件上,使用REID射频识别技术和称重传感器技术实现自动扣费方式;
在方式上,自动扣费方式减少学生结账时间进而提高食堂效率,减少人力成本;
使用技术:
RFID射频识别&称重传感器 前端 数据库 微信小程序 数据分析与挖掘 机器学习 深度学习
我的工作:数据分析与挖掘
1. 定义挖掘目标
针对餐饮行业的数据挖掘应用,可定义如下挖掘目标。
- 每日膳食推荐智能推荐。
- 基于餐饮大数据,对餐饮客户价值分析。
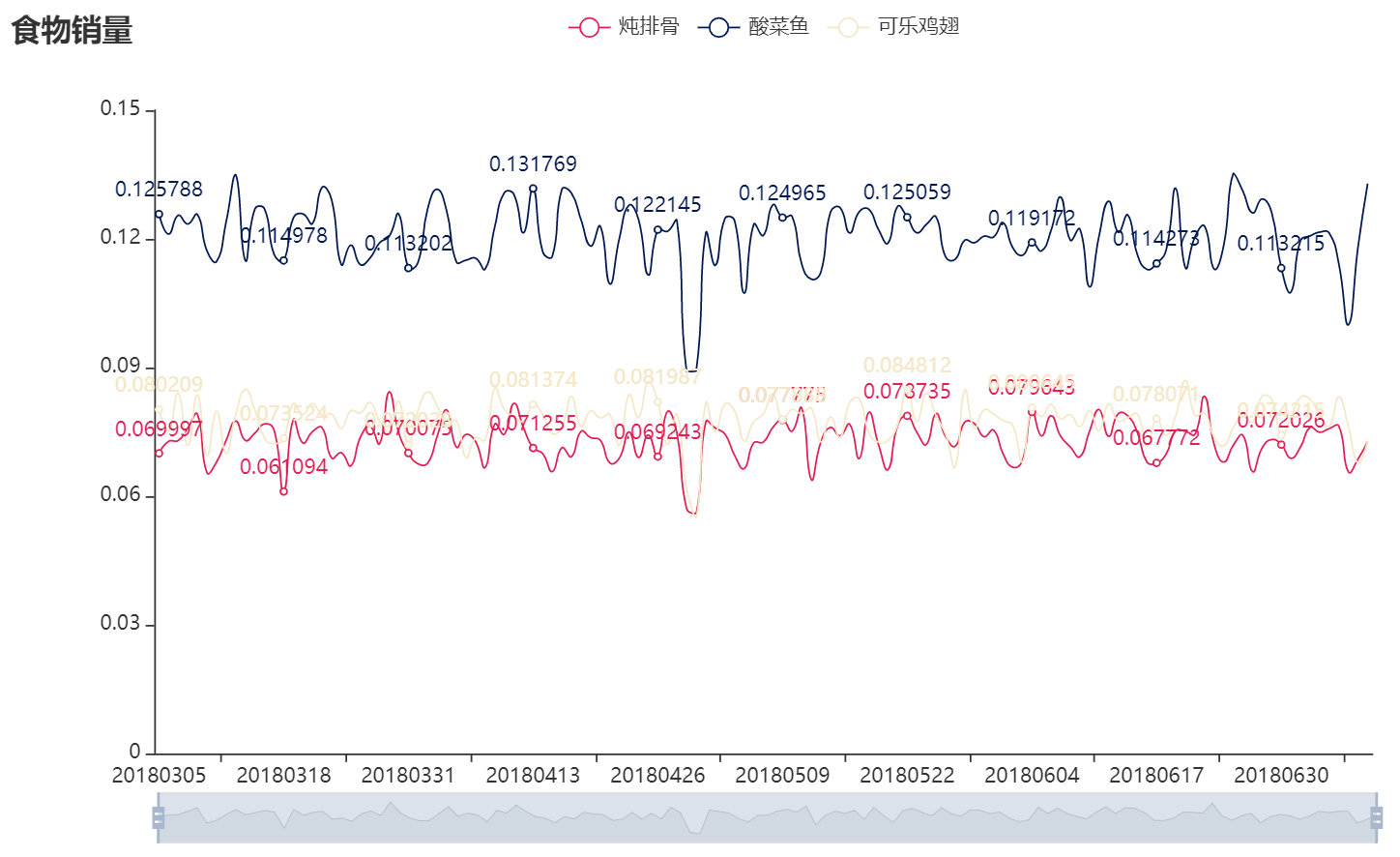
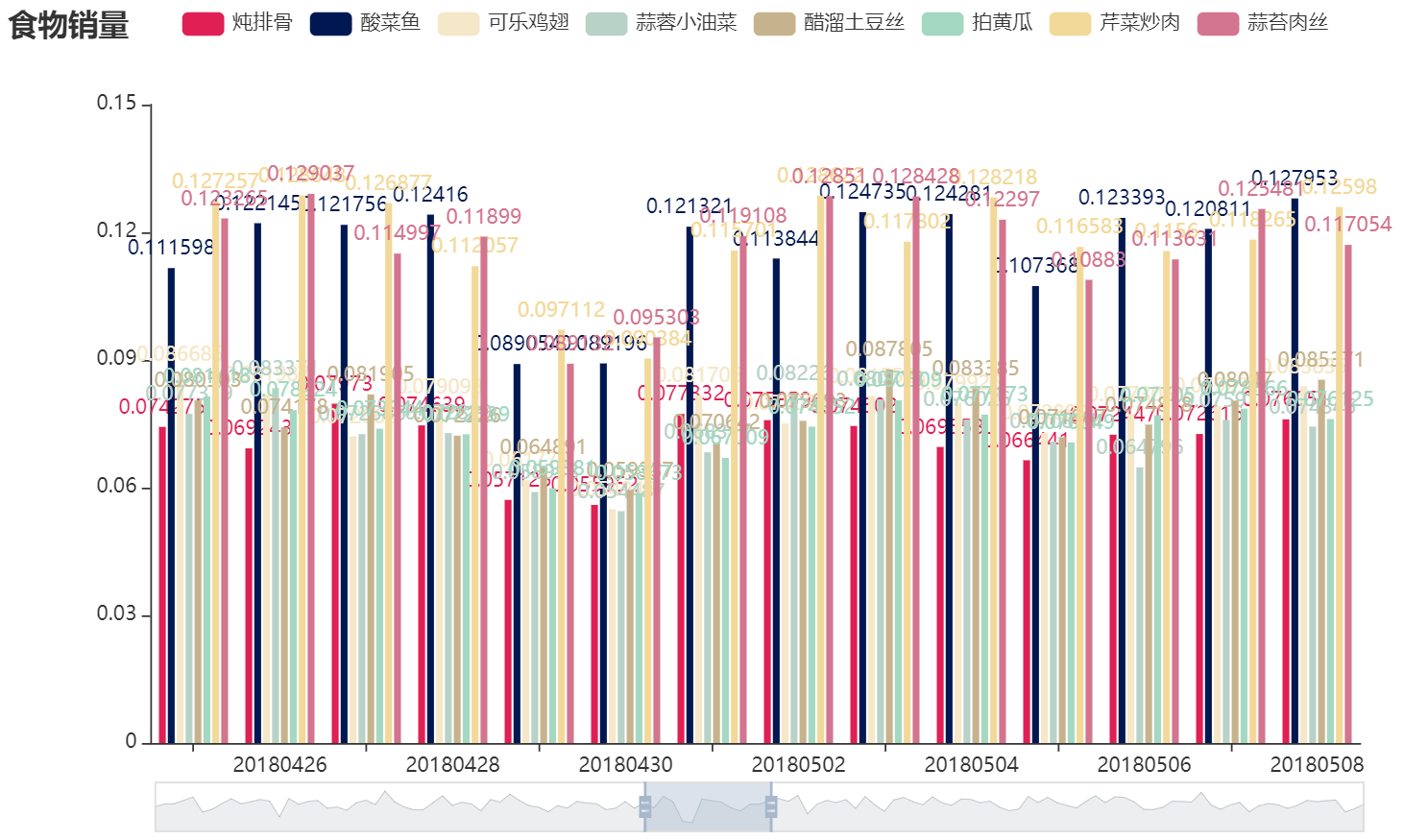
- 基于菜品历史销售情况,综合外部因素(节假日、气候、竞争对手等),对菜品销量进行趋势预测。
2. 数据取样
抽取数据的的标准,一是相关性、二是可靠性、三是有效性。
本项目中取样:
个人属性(/dataset/用户属性new.xls): 用户id 性名 性别 年龄 身高 体重 籍贯 口味1 口味2 忌口 喜爱食物类型1 喜爱食物类型2
交易记录(/dataset/交易记录.csv):用户id 食物id 消费单价 消费质量 消费金额 消费时间
3. 数据探索
当拿到一个样本数据集后,ta是否达到了我们原来设想的要求;样本中有没有什么明显的规律和趋势;有没有从未设想的数据状态;属性之间有什么相关性;ta们可区分成怎样的类别等,这都是要探索的内容。
挖掘模型的质量不会超过抽取样本的质量。数据探索和预处理的目的是为了保证样本数据的质量,从而为保证模型质量打下基础。
4. 数据预处理
由于采样数据中常常包含许多含有噪声、不完整、甚至不一致的数据,对数据挖掘所设计的数据对象必须进行预处理。
数据预处理主要包括:数据筛选、数据变量转换、缺失值处理、坏数据处理、数据标准化、主成分分析、属性选择、数据规约等。
个人属性(/dataset/用户属性new.xls)&交易记录(/dataset/交易记录.csv)为预处理后的文件。
5. 挖掘建模
样本抽取完成后,接下来要考虑的问题是:本次建模属于数据挖掘应用中的哪类问题(分类、聚类、关联规则、时序模式或智能推荐)选用哪种算法进行模型构建?
这一步是数据挖掘工作的核心环节。针对餐饮行业的数据挖掘应用,挖掘建模主要包括:
- 基于关联规则算法的动态菜品智能推荐
- 基于聚类算法的餐饮客户价值分析
- 基于分类与预测算法的菜品销量预测
以菜品销量为例,模型构建是对菜品历史销量,综合考虑了节假日、气候和竞争对手等采样数据轨迹的概括,ta反应的是采样数据内部结构的一般特征,并于该采样数据的具体结构基本吻合。模型的具体化就是菜品销量预测公式,公式可以产生与观测值有相似结构的输出,这就是预测值。
6. 模型评价
建模过程中会得出一系列分析结果,模型评价的目的之一就是从这些模型中自动找出最好的模型,另外就是要根据业务对模型进行解释和应用。

具体细节&展示
1.基于关联规则算法的动态菜品智能推荐
1.K-means
2.基于聚类算法的餐饮客户人群分析
1.K-means:将人群按食物喜好聚类为几类人群.
3.基于分类与预测算法的菜品销量预测
1.LSTM(长短期记忆网络)
2.Attention(注意力机制)