在计算机里,所有的数据结构本质上可以归为两类:数组和链表
数组的内存模型
1.一维数组
什么是数组?
在计算机科学中,数组可以被定义为是一组被保存在存储连续空间中,并且具有相同类型的数据元素的集合。而数组中的每一个元素都可以通过索引来进行访问。
例:以java语言中一个例子说明一下数组的内存模型,当定义了一个拥有5个元素的int数组后,看看内存是长什么样子?
int[] data = new int[5];
通过上面的声音,计算机会在内存中分配一段连续的空间给这个data数组。现在假设在一个32位上的机器上运行这段程序,java的int类型的数据占据了4个字节的空间,同时也假设计算机分配的地址是从0X80000000开始的,整个data数组在计算机内存中分配的模型如下图所示:
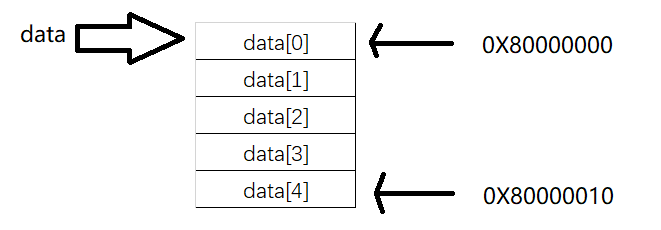
这种分配连续空间的内存模型同时也揭示了数组在数据结构中的另外一个特性,即随机访问(Random Access),随机访问这个概念在计算机科学中被定义为:可以用同等的时间访问到一组数据中的任意一个元素。这个特性除了和连续的内存空间模型有关以外,其实也和数组如何通过索引访问到特定的元素有关。
在计算机中,为什么在访问数组中的第一个元素时,程序一般都是表达成以下这样的:

data[0]
也就是说,数组的第一个元素是通过索引“0”来进行访问的,第二个元素是通过索引“1”来进行访问的,......,这种从0开始进行索引的编码的方式被称为“Zero-based Indexing”。当然了在计算机世界中,也存在着其他的编码方式,像Visual Basic中的某些函数索引采用1-based Indexing的,也就是说第一个元素是通过索引“1”来获取的,像这种方式就不多说了。等以后有时间慢慢研究。
为什么数组的第一个元素要用过索引“0”来进行访问呢?原因就在于获取数组元素的方式是按以下的公式来进行获取的:
base_address + index(索引) * data_size(数据类型大小)
索引在这里可以看做是一个偏移量(Offset),还是以上面的例子来进行说明:
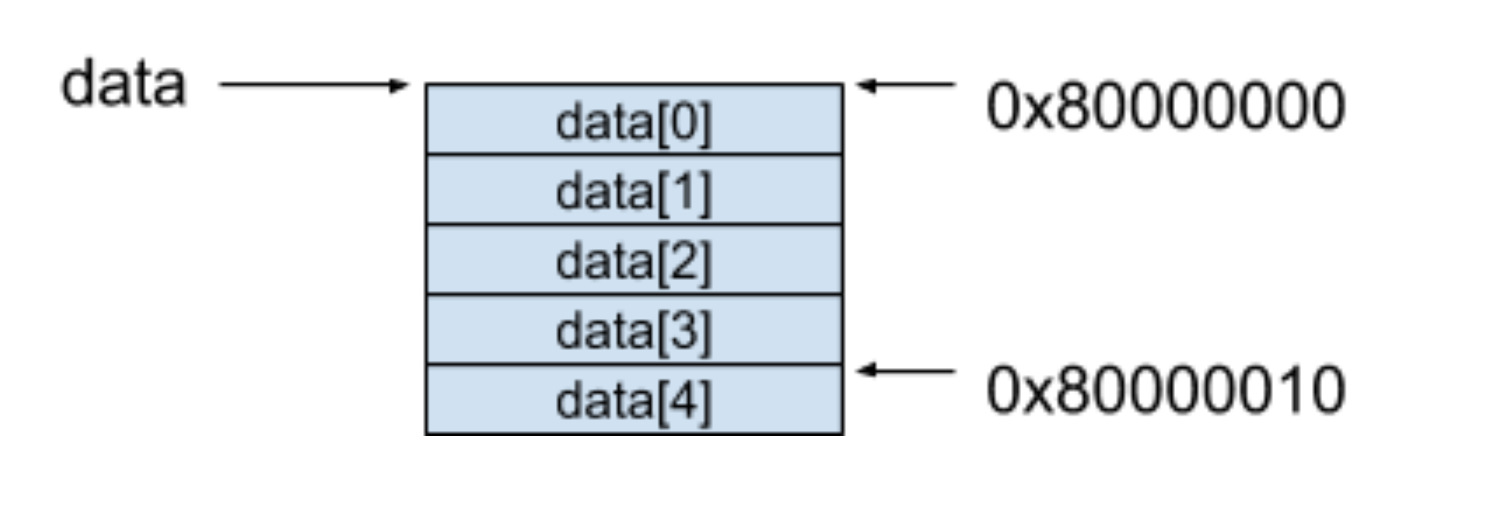
data这个数组被分配到的起始地址是0X80000000,是因为int类型数据占据了4个字节的空间,如果我们要访问第五个元素data[4]的时候,按照上面的公式,只需要取得0X80000000 + 4 * 4 = 0X80000010这个地址的内容就可以了。随机访问的背后原理其实也就是利用这个公式达到了同等的时间访问到一组数据中的任意元素。
2.二维数组
上面所提到的数组是属于一维数组的范畴,我们平时可能还会听到一维数组的其他叫法,例如向量(Vector)或者表(Table)。因为在数学上,二维数组可以很好的用来表达矩阵(Matrix)这个概念,所以很多时候我们又会将矩阵或者二维数组这种称呼交替使用。
如果我们按照下面的方式声明一个二维数组:
int[][] data = new int[2][3];
在面试中我们知道了数组的起始地址,在基于上面的二维数组声明的前提下,data[0][1] 这个元素的内存地址是多少呢?标准答案其实是“无法确定”,什么?标准答案是无法确定,别着急,因为这个问题的答案其实和二维数组在内存中的寻址方式有关。而这其实涉及到计算机内存到底是以行优先(Row-Major Order)还是以列优先(Column-Major Order)存储的。
假设现在有一个二维数组,如下图所示:
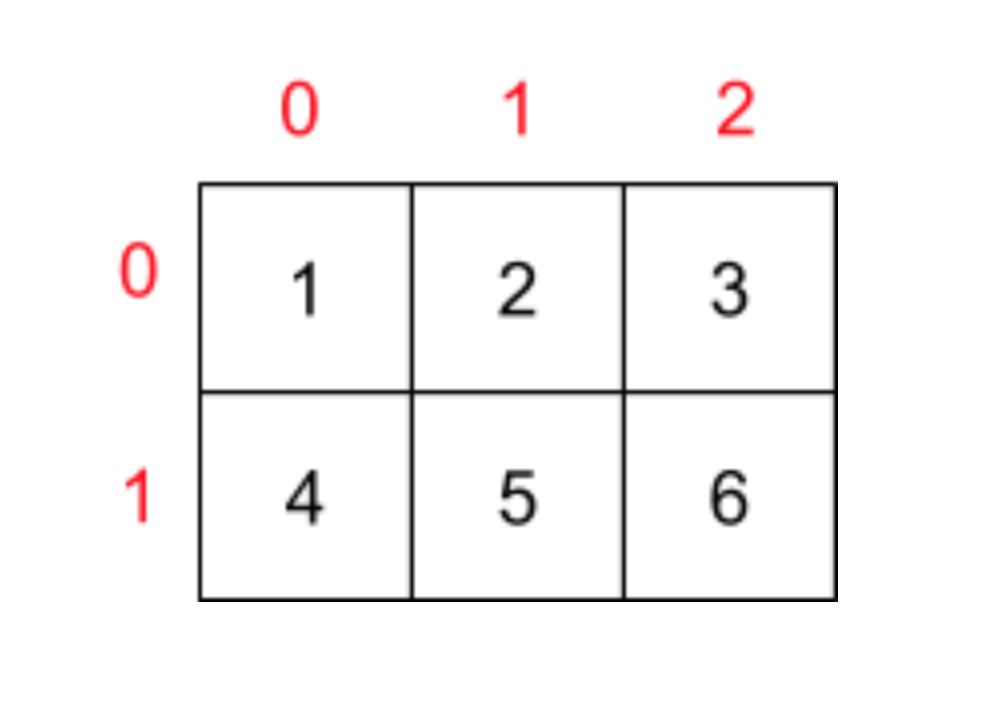
下面我们就这看看行优先或列优先造成的内存模型会造成什么样的区别:
(1)行优先
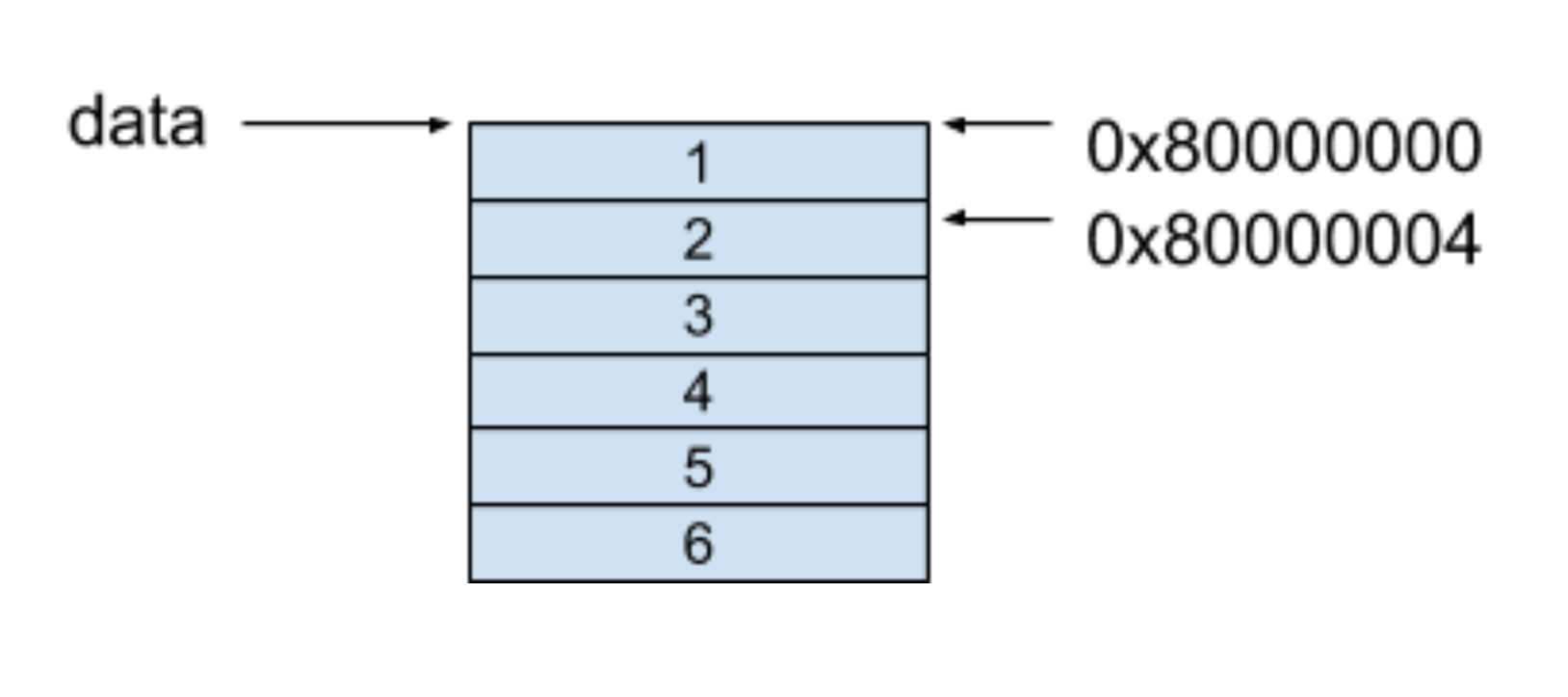
行优先的内存模型保证的每一行的每个相邻元素都保存在了相邻的连续空间中,对于上面的例子,这个内存模型如下图所示,假设起止地址是0X80000000:
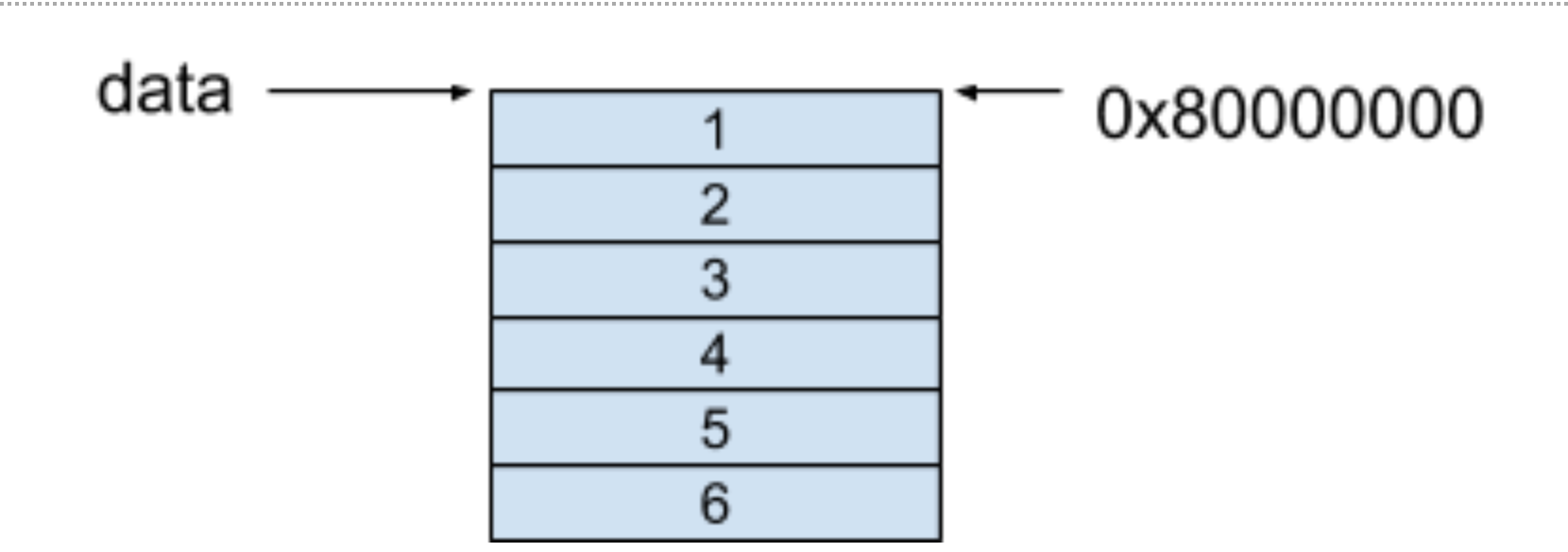
可以看到,在二维数组的每一行中,每个相邻的元素都保存在了相邻的连续内存里。
在以行优先存储的内存模型中,假设我们要访问data[i][j]里的元素,获取数组的方式是按照以下公式进行获取的:
base_address + data_size * (i * number_of_column + j)
回到一开始的问题里,当我们访问data[0][1]这个值时,可以套用上面的公式,其得到的值就是我们要找的0X80000004地址的值,也就是2。
0x80000000 + 4 x (0 x 3 + 1) = 0x80000004
(2)列优先
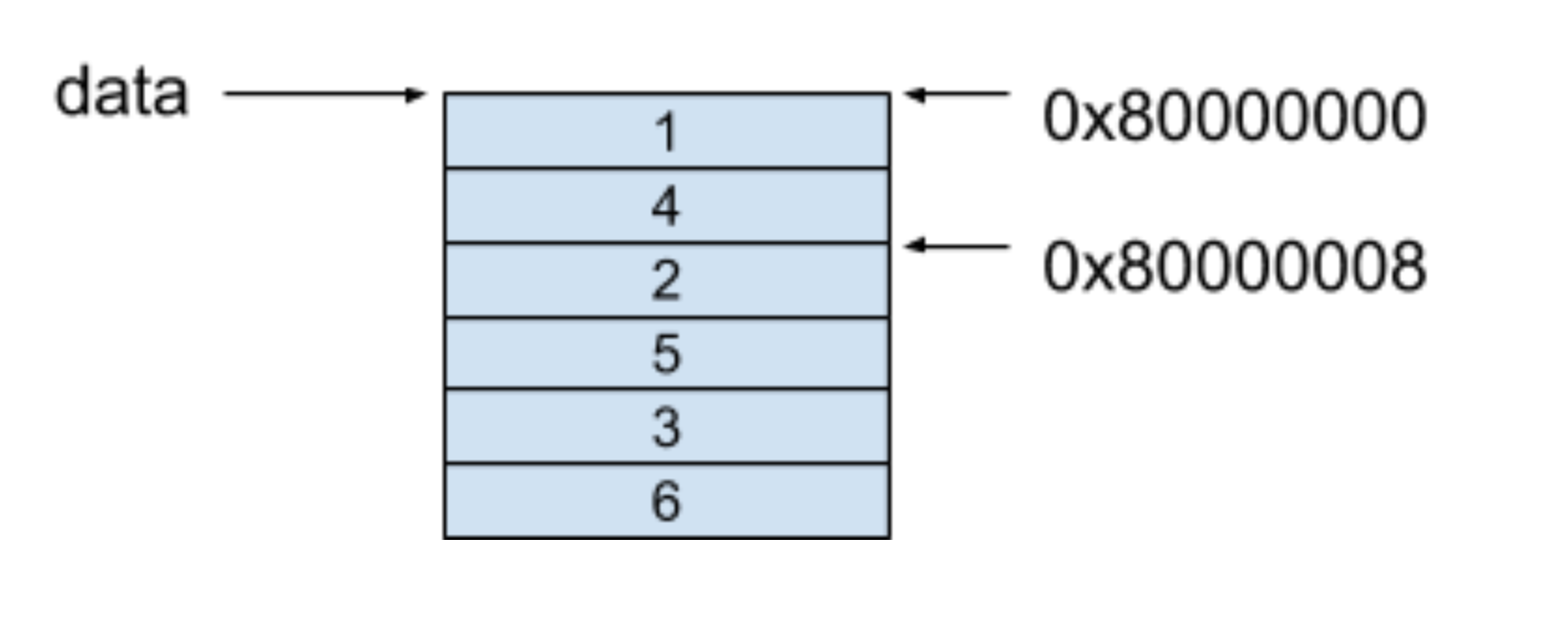
列优先的内存模型保证了每一列的每个相邻元素都保存在了相邻的连续内存中,对于上面的例子,这个二维数组的内存模型如下图所示:

可以看到,在二维数组的每一列中,每个相邻的元素都保存在了相邻的连续的内存中。
在以列优先存储的内存模型中,假设我们要访问data[i][j]里的元素,获取数组元素的方式是按照一下公式获取的:
base_address + data_size * (i + number_of_row * j)
当我们访问data[0][1]这个值时,可以套用上面的公式,其得到的值就是我们要找的0x80000008地址的值:
0x80000000 + 4 * (0 + 2 * 1) = 0x80000008
所以回到一开始那个问题里,行优先还是列优先存储方式会造成data[0][1]元素的内存地址不一样。
3.多维数组
多维数组其实本质上和前面介绍的一维数组和二维数组是一样的,如果我们按照下面的方式来声明一个三位数组:
int[][][] data = new int[2][3][4];
则可以把这个数组想象成两个int[3][4]这样的二维数组,对于多维数组则可以以此类推,下面把行优先和列优先的内存寻址方式列出来:
假设声明一个data[S1][S2][S3]...[Sn]的多维数组,如果要访问data[D1][D2][D3]...[Dn]的元素,内存寻址计算方式按照如下方式寻址:
行优先:
base_address + data_size * (Dn + Sn * (Dn - 1 + Sn - 1 * (Dn - 2 + Sn - 2 * (... + S2 * D1 )... )))
列优先:
base_address + data_size * (D1 + (S1 * (D2 + S2 * (D3 + S3 * (... + Sn - 1 * Dn)...))))
cpu在读取内存数据的时后,通常会有一个cpu缓存策略,也就是说再cpu读取程序指定地址的数值时,cpu会把它地址相邻的一些数据一并读取,并放到更高一级的缓存中,比如L1或者L2缓存。当数据存放到这种缓存上的时候,读取的速度有可能会比直接从内存上读取的速度快10倍以上。
在高级语言中常用的C/C++和Objective-C都是行优先的内存模型,而Fortran或者Matlab是列优先的内存模型。
“高效”的访问与“低效”的插入删除
从前面的的数组内存模型学习中,我们知道了访问一个数组的元素是随机访问方式,只需要按照上面讲到的寻址方式来获取相应位置的数值便可,所以访问数组元素的复杂度是O(1)。
对于保存基本类型(Primitive Type)数组来说,它们的内存大小在一开始就已经确定好了,我们称他为静态数组(Static Array)。静态数组的大小是无法改变的,所以我们无法对这种数组进行插入和删除操作。但是在使用高级语言的时候,比如java,我们知道java中的ArrayList这种Collection提供了像add和remove这样的API来进行插入和删除操作,这种数组可称之为动态数组(Dynamic Array)。
我们一起来看看add和remove函数在java Open-jdk11中的源码,一起分析他们的时间复杂度:
在java Connection中,底层的数据结构其实还是使用的数组,一般在初始化的时候会分配一个比我们在初始化时设定好的大小更大的空间,以方便以后进行增加元素的操作。
假设所有的元素都保存在elementData[]这个数组中,add函数的主要时间复杂度来源于以下源码片段:
1.add(int index,E element)函数源码:
首先来看看add(int index,E element)这个函数的源码:
public void add(int index,E element){
rangeCheckForAdd(index);
modCount++;
final int s;
Object[] elementData;
if((s = size) == (elementData = this.element).length){
elementData = grow();
}
System.arraycopy(elementData,index,elementData,index +1,s - index);
elementData[index] = element;
size = s + 1;
}
可以看到add函数调用了一个System.arraycopy的函数进行内存操作,s在这里代表了ArrayList的size,当我们调用add函数的时候,函数在实现的过程中到底发生了什么?我们来看一个例子。
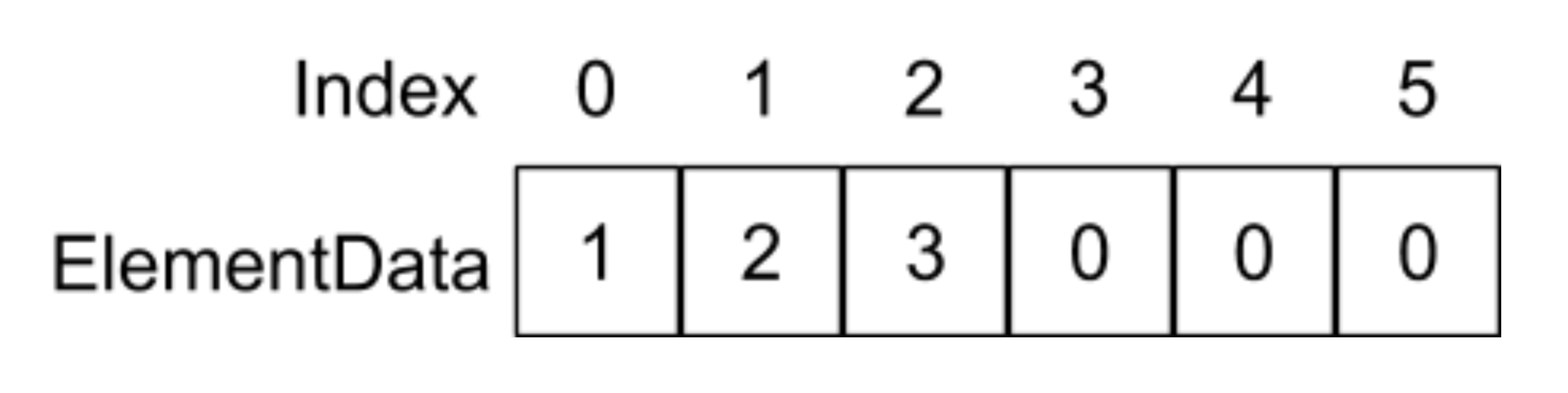
假设elementData里面存放着以下元素:
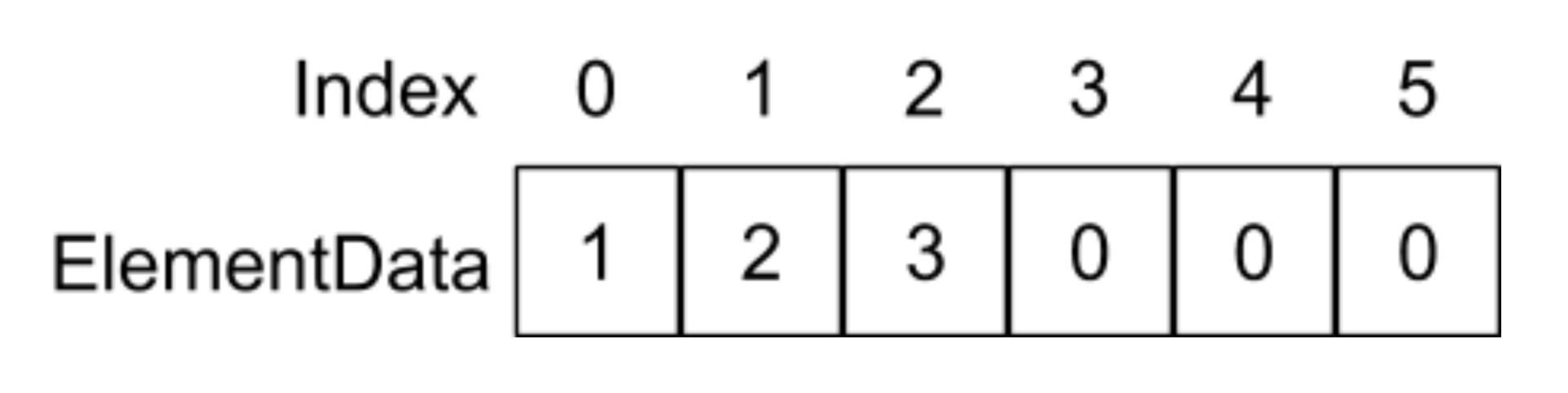
当我们调用的add(1,4)函数,也就是在index为1的地方插入4这个元素,在add函数中则会执行System.arraycopy(elementData,1,elementData,2,6 - 2)语句,它的意思是将重elementData数组index为1的地址开始,复制往后的4个元素到elementData数组为2的地址位置,如下图所示:
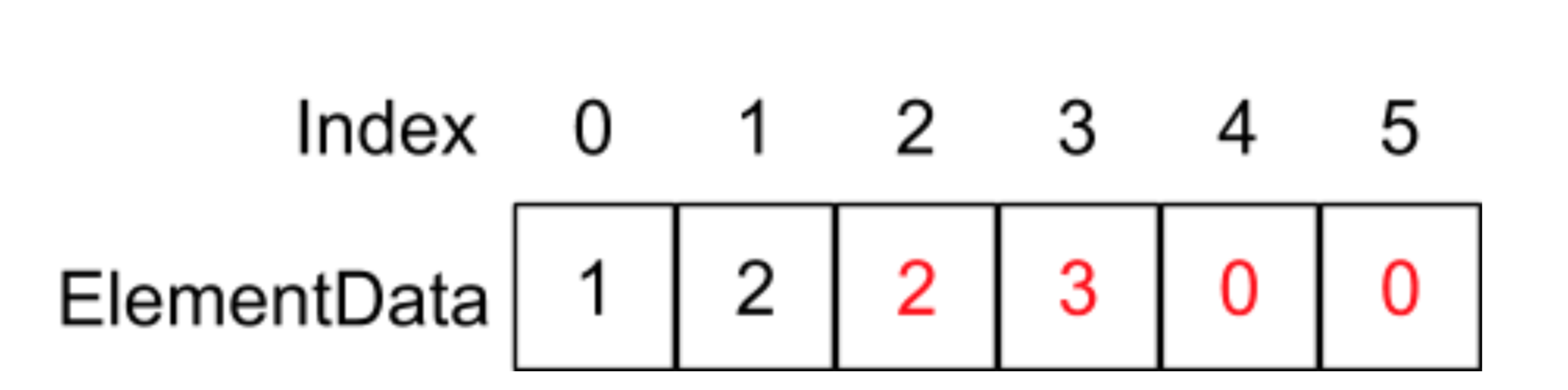
红色部分代表执行完System.arraycopy函数的结果,最后执行elementData[1] = 4;这条语句:
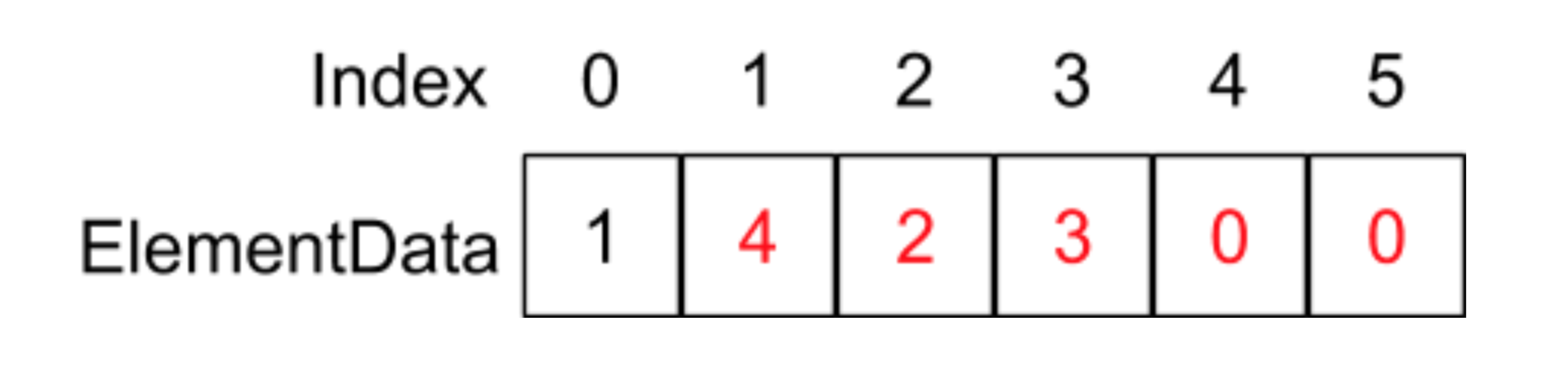
因为这里涉及到每个元素的复制,平均下来的时间复杂度相当于O(n)。
2.remove(int index)函数源码:
1 public E remove(int index){
2 Objects.checkIndex(index,size);
3 final Object[] es = elementData;
4
5 @SuppressWarnings("unchecked") E oldValue = (E) es[index];
6 fastRemove(es,index);
7
8 return oldValue; 9 } 10 11 private void fastRemove(Object[] es,int i){ 12 modCount++; 13 final int newSize; 14 if((newSize = size -1) > i){ 15 System.arraycopy(es,i+1,es,i,newSize - i); 16 } 17 es[size = newSize] = null; 18 }
这里的newSize指原来的elementData的size - 1,当我们调用remove(1)会发生什么呢?我们还是以下面的例子来解释。
如果调用remove(1)函数,也就是删除在index为1这个地方的元素,在remove函数中则会执行System.arraycopy(elementData,2,elementData,1,2)语句,它的意思是将从elementData数组index为2的地址开始,复制后面的两个元素到elementData数组到index为1的地址位置,如下图所示:
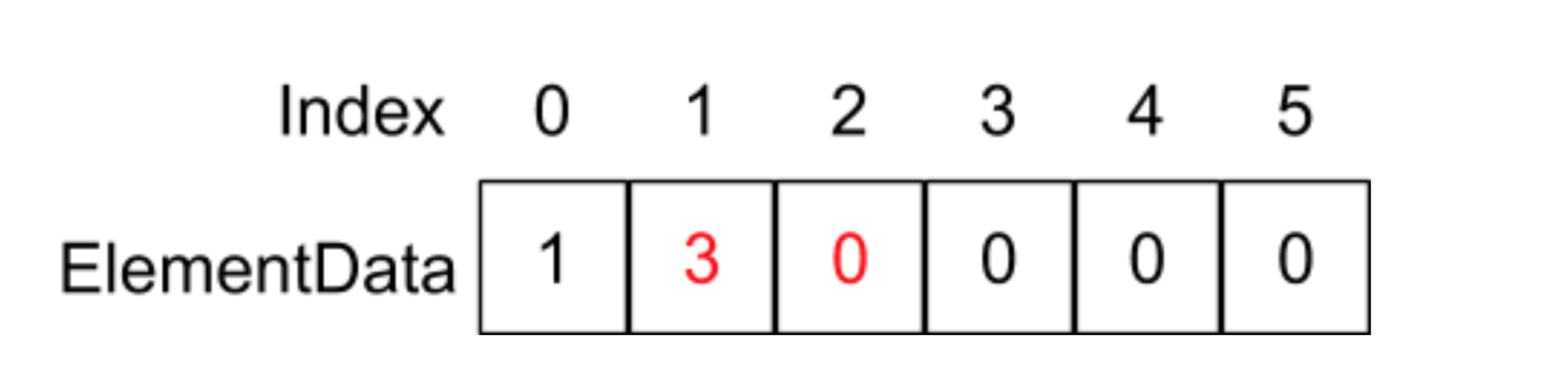
因为这里同样涉及到每个元素的复制,平均下来时间复杂度相当于O(n)。
心得:
这是我学数据结构的第一节课内容,因为基础太薄弱,看完视频后,感觉老师在讲的时候什么都明白,然后回来再看老师的笔记还是一头雾水,于是乎就把老师的笔记一个字一个字的打入了博客当中,这些除了图片之外其他完全是手打的,只为增强记忆力和理解力,打完了之后对里面的内容掌握率感觉还是不高,我会继续学习,把我所学到的知识全部写入我的博客中,供大家学习和交流。(根据蔡元楠老师讲解的数据结构精讲整理此笔记)