Oracle数据库简单介绍
对象关系型数据库
重点:一致性+性能
一致性优于性能
处理模型:C/S模型
Client:用户和用户进程
Server:服务器进程,实例,数据库本身
概念:实例 instance 后台进程+共享内存 用于管理和控制数据库
数据库 database 物理文件的集合,为实例提供数据,(三类文件)数据文件,控制文件,日志文件,参数文件等
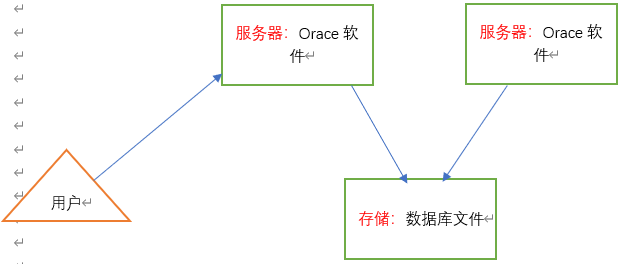
数据库服务器 database server 软件+实例+数据库
Oracle软件+Oracle数据库
软件放在服务器本地,数据库存放在存储上
实例
Oracle数据库启动后首先在内存中划分一片空间,并启动一些进程,而内存和进程统称为Oracle数据库实例,数据库关闭后,实力也就会被关闭。
一个数据库可以对应多个实例,但一般都是双数的,1:2/1:4等等,用户可以通过连接到实例去访问数据库,可以实现负载均衡,提高并发等,而这种结构叫做Oracle的RAC技术
连接:从客户端到oracle实例的一条物理路径(网络连接、IPC机制连接)
会话:会话是一个逻辑实体,存在于实例中
进程:指定一个实例在操作系统级别能同时运行的进程数,包括后台进程和服务器进程(前台进程),一个前台进程可能同时对应多个会话,因此通常sessions的值大于processes的值。
数据库用户
sys:超级用户,最高权限,用于维护系统信息和管理实例
只能以SYSDBA或SYSOPER角色登录
system:oracle默认管理员,拥有DBA权限,用来管理Oracle数据库的用户,权限和存储等
scott:oracle普通示例用户
灵活体系结构(OFA)
组织大量软件
简化常规管理任务
在多个Oracle数据库之间实现轻松切换
相应地管理数据库扩展
帮助消除空闲空间碎片
三类文件
(1)控制文件 .ctl
整个数据库的物理结构信息,其中包括数据库文件的数量、文件存放的位置、重做日志文件的数量和位置等
数据库当前运行的状态信息
(2)数据文件 .dbf
数据库实实在在的所有数据(表信息),控制文件比较小,数据文件比较大
(3)重做日志文件 .log
对数据库文件的所有操作(修改)/每一个数据块的修改信息/数据的变化过程
三、Oracle实例
数据库启动后,就会生成一个实例(内存+进程=Oracle实例)
用户一般通过oracle实例来访问数据库
四、Oracle实例与数据库比例:1:1 1:n ,一般都是成双数的1:2/1:4/1:6/1:8……
五、RAC技术:负载均衡
当有100个用户连接数据库的时候,其中50个用户连接一个实例,50个用户连接另一个实例。
六、体系结构
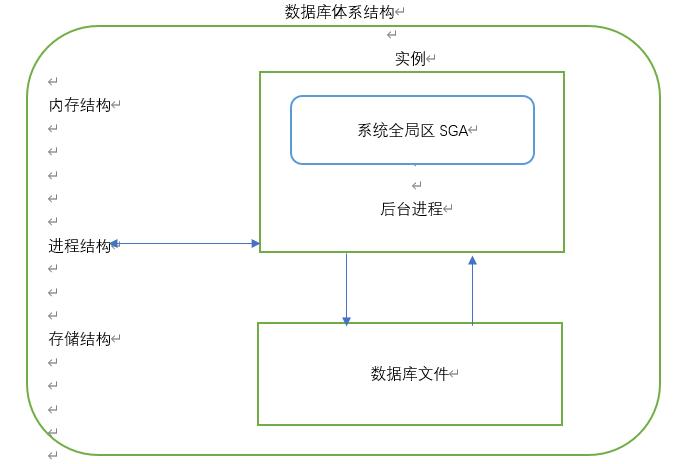
- 内存结构
内存结构包括:SGA和PGA(共享和进程)
SGA:系统全局区System Global Area/Shared Global Area
由所有服务器进程(前台进程)和后台进程共享
SGA包括六大pool(池)
(1) Shared Pool 共享池
(2) Database Bufffer cache 数据库缓冲区 高速缓存
(3) Redulog Buffer 重做日志缓冲区
(4) Streams池
(5) 大型池(Large Pool)
(6) Java Pool
PGA:程序全局区 Program Global Area
进程有自己的进程空间,进程空间来自于PGA,进程的公有信息存放在SGA上,私有信息放在PGA上。
数据库启动后会有很多进程,有两大类:前台进程(服务器进程)和后台进程
用户访问数据库(如图)
当用户访问数据时,首先会从连接池里随机选择一条连接,然后应用服务器会产生一个SQL访问语句,通过选择的随机连接传送给数据库。
当数据库接到访问的SQL语句后,将访问的数据通过连接返回给应用服务器,然后服务器通过wed界面呈现给客户端。
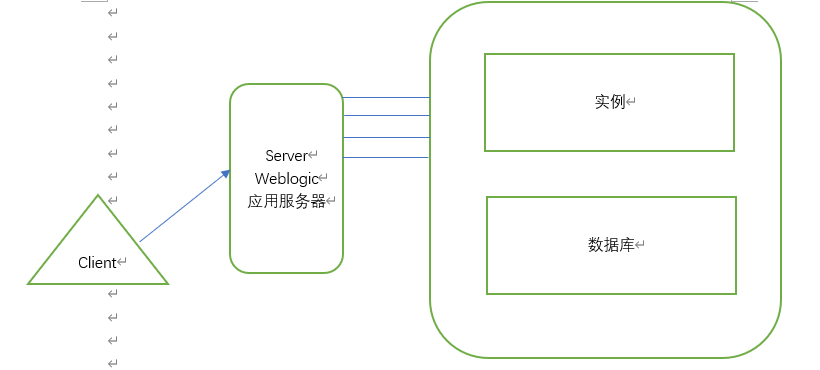
(1) 用户访问应用服务器
(2) 服务器生成连接池,随机选择连接
大量的SQL语句会通过连接池进入数据库
数据库解析执行SQL语句获取数据返回给客户
2.进程结构
a) 用户进程 在数据库用户请求连接到Oracle服务器时启动
b) 服务进程 可以连接到Oracle实例,他在用户建立会话时会启动
c) 后台进程 在启动Oracle实例时启动
什么是服务器进程?前台进程----服务器进程
例子:ps -ef | grep ora ----查看oracle相关进程
Oracle jiagulun(DESCRIPTION=(LOCAL=YES))(ADDPRESS=(PROTOCOL=beq))
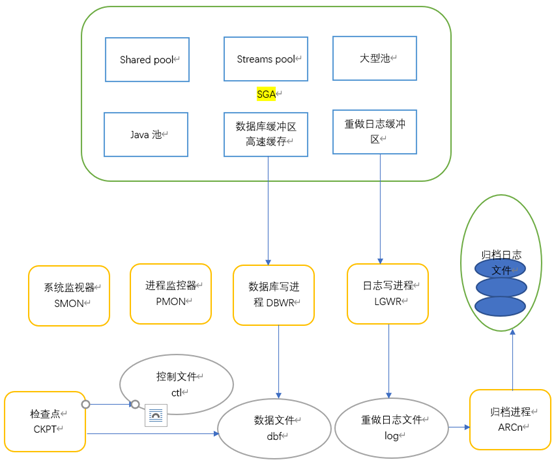
Oracle实例管理
五大进程:(1)check point
(2)SMON (System Monitor)
(3) PMON (Process Monitor)
(4)数据库写进程
(5)日志写进程
实例管理如下图所示
SQL语句执行过程
(1) 客户端输入SQL语句
(2) SQL语句有server process通过网络送达数据库实例
(3) Server Process接受SQL语句,首先将SQL有进步进行解析,生成执行计划,然后执行这个执行计划
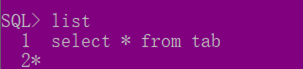
List---可以查看执行过的sql语句
Server Process 首先会判断SQL的语法问题,之后会检验所要访问的表对应的权限问题,权限问题包括输入的sql语句的用户对sql语句中涉及的表和视图有没有权限,除此之外,还要检查是否存在这个表或者视图,还会判断sql语句应该如何执行。
一条SQL语句是有多种执行方案的,Server Process需要从多种执行方案中选择一个最优的执行方案,而执行计划在整个过程中,需要访问很多对象(数据)。
SQL语句执行:1.解析:需要消耗很多资源,CPU资源、IO资源、内存资源等,最主要消耗的是CPU资源。如果两个用户执行相同的语句操作,如果A用户执行完成后生成缓存,当B用户也执行时就可以直接读缓冲区。
而缓存的数据存放在-----Shared Pool中
所以,Server Process拿到SQL语句时,首先会到SharedPool进行查询,看是否有该语句的缓存。如果Server Pool缓存的话,Server Process会找到相同的SQL语句以及相对应的执行计划再执行。
Server Process:先找,再解析。
Shared Pool作用:缓存SQL语句以及SQL语句对应的执行计划
shared pool的访问和修改工作都是Server Process进行的
SQL语句执行后需要取数据,表数据在dbf文件中
Server Process根据执行计划去执行,执行计划从dbf中取数据然后返回给用户