1.前言
看完咕泡Jack前辈的有关hashMap的视频(非宣传,jack自带1.5倍嘴速,高效),收益良多,所以记录一下学习到的东西。
2.基础用法
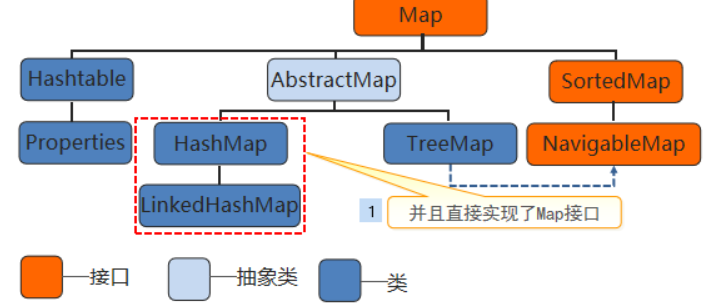
对应源码:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable { ... }
HashMap的基础用法:https://blog.csdn.net/lzx_cherry/article/details/98947819
3.存储方式
(1)HashMap key、value被put后的存储方式:
在JDK1.7及其之前都是用的 数组+链表 的方式,JDK1.8之后存储方式优化成了 数组+链表+红黑树 的方式。
(JDK1.8后,如果单链表存储的长度大于8则转换为红黑树存储,采用这样的改善有利于解决hash冲突中链表过长引发的性能下降问题)
(2)图解
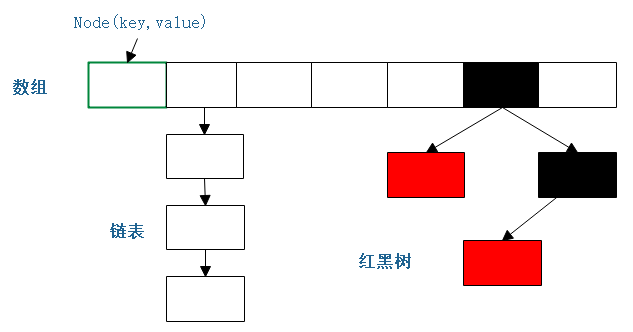
<1>存储单元 Node
图中的每一个格子代表每一个Node对象。Node的信息主要包含它的存储位置,key,value,如果在链表中则会有下一个Node的信息,如果存储在红黑树中则包含红黑树的相关信息。
Node的数据结构 伪代码:
Node[] table; 数组
class Node{ Node next; } 链表
TreeNode(left, right, parent, boolean flag = red| black) 红黑树
HashMap源码中Node的代码:
/** * Basic hash bin node, used for most entries. (See below for * TreeNode subclass, and in LinkedHashMap for its Entry subclass.) */ static class Node<K,V> implements Map.Entry<K,V> { //通过hash算法得出的存储位置 final int hash; //key final K key; //value V value; //链表的下个Node Node<K,V> next;
...
}
HashMap源码中TreeMap的代码(建议之前先了解红黑树的原理):
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { TreeNode<K,V> parent; // red-black tree links TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; // needed to unlink next upon deletion boolean red;
... }
<2>存储过程
根据HashMap的数据结构,可以大致推断出它的存储过程。
a.先创建一个数组
b.计算出存储key value的Node的位置
c.如果hash冲突了,判断冲突数目的长度决定使用链表还是红黑树结构
d.数组不够需要进行扩容
下面对存储过程进行细致的分析。
1.计算出存储key value的Node的位置
先分析这个有助于前提的理解,这也是理解存储过程一个比较基础重要的内容。
计算出Node的位置,就是需要得到Node在数组中的整型数下标,但是前提是不超出数组的大小。HashMap数组的大小可以采用默认值,也可以自行规定,这边我们采用默认的值16进行分析。
首先,要保证是个整型数,最好还是和key value有关联的,所以最好的方式就是通过key.hashCode()。其次,我们需要保证Node的index大小在0~15之间。所以我们可以先进行一个取 余判断,判断: 整型数%16 = [ 0 , 15 ]。
分析取余:
例如一个数字1,hashCode的值为49,那么取余的操作就为 49 % 16 = 1。但是这样的取模方式还可以进行优化,49的10进制整型数转化为32位二进制:
0000 0000 0000 0000 0000 0000 0011 0001 % 16 = 1
对16进行取余,其实效果就相当于对(16-1)进行与操作:0000 0000 0000 0000 0000 0000 0011 0001 & 0111,因为与操作时候与的时候,最后四位的范围是[0,15],如果大于15的话,
就进位了,这样可以更有效控制整形数的范围。
0000 0000 0000 0000 0000 0000 0011 0001
0 1111 &操作 (数组大小 - 1)
————————————————————————————————————————————————
0001(结果)
最终返回的结果就是Node在数组中的位置index了。index如果相同的话就会产生位置冲突,这时候就需要链表和红黑树数据结构,但这样会使得我们去获取key value变得更加耗时。所以我 们需要尽量保证index就是Node的位置不要太容易就出现重复的情况。
从上的与过程中我们可以看出,能决定Node位置取决在两个相与的数(暂称为key1和key2),这两个数的后4位决定了Node的位置,如果要保证hash不冲突的话,就要先分析他们。
与操作,一方为0就结果为0,key2的最后四位值如果一个为0的话,无论key1对应的是什么,结果都是0,这样极其容易导致冲突,所以我们要尽量保证key2除了最高为0外。其他位置都1。
例如:01111(15)、011111(31)、0111111(63),不难看出key2的值,其实就是2的n次幂-1。所以我们需要尽量保证数组的大小为2的n次幂。
但是即便保证了后四位都为1的话,毕竟只有4位,4位进行与操作,还是很容易出现一个重复情况,对于这种情况,HashMap采用了异或(xor)操作( a⊕b = (¬a ∧ b) ∨ (a ∧¬b) )。
具体操作,将32位的二进制数字一分为二,左边16位的高16位为一份,右边的低16位为另一份。两者进行异或运算,降低重复的可能性。
如:
高16位 低16位
0101 0101 0010 1001 | 0001 0001 0001 0110
其实这就是HashMap中的hash算法,源码:
static final int hash(Object key) { int h;
//如果key为null则返回0,如果不为null则返回key的hashCode高低16位异或运算的结果 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
如果再重复就只能形成链表和红黑树了。
2.创建数组
如果采用默认的大小的话,默认的数组大小为16。源码:
/** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16