本书第8章是The ML4T Workflow – From Model to Strategy Backtesting,本章集成了机器学习交易工作流的各个构建模块,并从端到端角度介绍了由机器学习算法驱动的交易策略的设计、模拟和评估机器学习驱动的交易策略的过程。详细地演示了如何使用backtrader和Zipline库准备、设计、运行和评估回测。前几章我们已经学过了zipline,这章更像一个总结应用,东西不是特别多。
上面提到了端到端,端到端就是:输入是原始数据,输出是最后的结果
端到端(end-to-end)的含义_lxy_Alex的博客![]() https://blog.csdn.net/happyhorizion/article/details/100607429
https://blog.csdn.net/happyhorizion/article/details/100607429
目录
5.1 Calendars and the Pipeline 让拟合更稳健
5.3 The Pipeline API:对ML信号进行回测
首先,什么是回测:
基于归纳历史市场规律的策略,就需要让策略在历史环境中模拟交易,评估性能。回测是根据历史数据来验证交易策略的可行性和有效性的过程,希望用回测结果预测该策略在未来的收益率。 计算策略在历史数据可以实现的盈利能力、风险度、可靠性等,来预测策略未来的表现。回测的基本理论是,任何在过去有效的策略在未来都可能有效,相反,任何在过去无效的策略在未来也可能无效。
1 如何回测

- 获取和准备市场数据、基本面数据和其他数据
- 处理数据调整时间,计算阿尔法因子和特征工程
- 设计机器学习模型、调整参数和评估机器学习模型以生成交易信号
- 根据这些预测的信号,应用规则来选择要投资的资产
- 根据资产配置等原理,调整投资组合环境中的单个头寸的大小,使得投资组合最优化,生成Target Portfolio
- 使用历史市场数据,模拟所触发的结果交易
- 评估结果位置的表现
2 回测中的陷阱及如何避免
2.1 数据正确
- 前视偏误:用未来的信息来确定今天的交易信号。比如说用当日的最高价格来决定当日的买入信号。但实盘里这种信息是不可能取得的。
- 幸存者偏差:选股中,只选当时存在的股票,而没有把退市的股票也加入到选股库里。
- 异常值控制:我们可以通过winsorize缩尾或者截尾,控制异常值,(缩尾就是所有大于上临界值的值全等于上临界值,所有小于下临界值的值全等于下临界值;截尾就是直接去掉极端值)。这里的难点在于确定真正不能代表所分析时期的异常值,而不是去掉作为当时市场环境组成部分的任何极端值。
- 样本期选择:如果样本数据不能反映当前(和可能的未来)环境,那么回测将不能产生推广到未来的具有代表性的结果。在波动性或成交量方面,未能包含足够的数据点,或包含过多或过少的极端历史事件,就很难产生可以推广的结果。我们可以使用包含重要市场现象的样本周期或生成反映相关市场特征的合成数据,来解决这个问题。
2.2 模拟正确
- 未能Mark to Market盯市,模型可能开始的时候表现很好,但后面表现变差;解决方法:绘制随时间变化的性能图或计算(滚动)风险指标,比如风险价值VaR或者Sortino Ratio
- 对交易的可行性、成本或市场影响的不切实际的假设;没有交易对手的情况下假设卖空的策略,或低估交易规模较大或交易流动性较差资产的交易(下滑)对市场的影响,或由于经纪人费用而产生的成本。解决方法可以是限制流动性,设置一些市场参数模拟现实情况流动性较差的资产交易对价格的影响。
- 错误的信号和交易执行时机,类似于前视偏误,模拟可能会对什么时候接收信号并根据信号进行交易做出不切实际的假设。例如,当交易只能在下一个开盘价进行时,信号可能从收盘价格计算出来,而这两个价格可能有很大不同。当我们使用收盘价来评估性能时,回测结果将不能代表现实的未来结果。解决办法是 写程序的时候:认真确认信号到达、交易执行和性能评估的顺序。
2.3 统计正确:数据窥视、避免过度拟合
数据窥视(data-snooping)是指从数据中发现统计上显著但实际并不存在的关系,是金融分析里面非常普遍和严重的一个问题。在金融分析中,因为我们可以对同一个数据集进行无数次的实证研究,如果有足够的时间、足够的尝试和足够的想象力,我们可以不需要考虑经济上的合理性而直接寻找金融变量统计上的关系,这样我们几乎能从任何数据集中推断出任何规律。通过数据窥探,我们可以让数据分析结果更显著来支持自己的立场,但往往让实验无法重复,没法用来预测未来。
2.3.1 what is backtest overfitting
Backtest Overfitting:通过调整参数让模型在历史数据上跑出很高的夏普比,真的实盘能赚钱很难。回测过拟合的定义:根据历史表现在候选池中选出的最佳策略在未来排名处于下半区。样本外的夏普比率的期望比样本内的夏普比率小。E[SR_OOS]<SR_IS (IS表示样本内,OOS表示样本外)。

回测出的SR在未来数据中衰减得厉害,原因有很多,市场pattern变化、模型方差太高等等。但这里我们只考虑策略选择导致的过拟合,举个例子,比如我选择的策略,虽然未来的期望收益没有那么好,甚至大家都亏得厉害,但是如果我在历史回测中选择的表现最好的、夏普比率最高的策略,在未来依然是其中表现最好的策略,那么这次回测就算是成功的。如果选出的夏普比率最高的策略在未来表现垫底,就说明做回测导致我亏了更多钱,还不如随机选一只策略。
因为多做实验会增加发现高SR的概率,所以要把标准提高:比如,一次实验SR=2,就认为策略有效,做了十次实验就要求SR=3,这时SR=2的策略被认为是随机性导致的。类似的方法还有限制住总的尝试次数,要求拉长回测时间等等。这些调整阈值的办法能且只能解决多重测试带来的回测过拟合。
2.3.2 Why backtest overfitting
- 只要我做的实验足够多,总能找到在历史数据上表现良好的策略。multiple testing多重测试会造成结果假阳性。关于多次检验提高假阳性风险的,作者没有具体介绍,但是贴了好几篇论文。
- 从历史数据到未来金融数据,市场环境改变。但策略可能只是非常好地契合了历史数据的“真实模型”。
2.3.3 最小回测长度(真的没太懂)
投资者应要求避免选择,在给定的样本内试验次数下实现一定的SR,但样本外SR的期望为零的策略。例如,作者计算得出,2年的每日回测数据不支持关于超过7种策略的结论。5年的数据不支持关于超过45种策略的结论。
2.3.4 最优停止时间
在尽可能短的时间内选择一个接近最佳的方案,同时最小化假阳性的风险。参考秘书问题的最优停止理论的解,这里有一个ucla的最优停止问题的课程链接。Local page (ucla.edu)
回测过拟合交互式示例![]() http://datagrid.lbl.gov/backtest/
http://datagrid.lbl.gov/backtest/
2.4 代码举例:Deflated Sharpe Ratio
Bailey和Prado(2014)提出DSR,以计算在控制多重检验的膨胀效应、非正常收益率和较短样本长度的情况下,SR在统计上具有显著性的概率。
SR夏普比率:我们之前假设策略的年度回报率是正态分布的。μ和σ通常是未知的,我们用历史回报来估计它们。因此,我们通常计算的夏普比率不是真正的SR,它是一个估计值,并且作为每个估计值,它都会有其方差和置信水平。由于实际上,我们能获取到的回报率数据是有限的,得到的回报率序列的分布可能不完全符合概率分布,计算出的夏普比率也是不准确的。虽然偏度和峰度不会影响夏普比的点估计,但它极大地影响了其置信带,从而影响了其统计显著性。
PSR概率夏普比率:它舍弃了收益率是正态分布的假设,并将夏普比率的置信度加入了其中。PSR的含义是,夏普比率大于基准值(一般基准值会取0)的概率。(PSR考虑了样本长度和的前四阶矩收益分布。参考论文证明了,它的原因是短样本与非正态收益分布样本的膨胀效应。)

本质上说,DSR是一种PSR,其中拒绝阈值经过调整以反映试验的多样性。

这里的gamma3是三阶中心矩偏度,gamma4是峰度,

N是独立试验的次数,SR0hat计算的时候考虑了独立实验次数的影响,
我觉得就是这样,不知道对不对:SR是最简单的,PSR考虑了估计SR的时候,分布的偏度和峰度,DSR在PSR的基础上有考虑了多重检验造成的误差。
https://www.davidhbailey.com/dhbpapers/deflated-sharpe.pdf
3 回测引擎如何工作
简单地说,回溯测试引擎迭代历史价格(和其他数据),将当前值传递给算法,接收返回的订单,并跟踪结果位置及其值。在实践中,创建上面描述的ML4T工作流的真实而稳健的模拟有许多需求。向量化方法和事件驱动方法之间的区别说明了真实交易环境的忠实再现如何增加了显著的复杂性。
3.1 向量化的回测 versus 事件驱动回测
本书写了一个向量回测的ipynb,后面介绍的bactrader和zipline都是事件驱动的回测。
向量化的回测是评估策略的最基本方法。它只是将表示目标仓位规模的信号向量与投资期限的回报向量相乘,以计算周期表现。使用一些简单的技术因素,我们预测了最近美元交易量最高的100只股票第二天的收益(详见第七章,线性模型-从风险因素到收益预测)。我们将用一个非常简单的策略将预测转化为信号:在任何一个交易日,我们将做多10个最高的正面预测,做空最低的10个负面预测。如果正面或负面的预测更少,我们就会持有更少的多头或空头头寸。
3.2 代码示例:一个简单的向量化回测
4 Backtrader:用于本地回测的灵活工具
backtrader文档![]() https://www.backtrader.com/docu/
https://www.backtrader.com/docu/
backtrader是由Daniel Rodriguez于2015年开发的一个Python第三方库,用于本地回溯测试,有很好的文档。cerebro是backtrader的核心,backtrader是事件驱动的回测框架,基于元编程的技术,把数据都处理成line数据线,
5 zipline:Quantopian 旗下的可伸缩回测
Quantopian, Inc. (github.com)![]() https://github.com/quantopian
https://github.com/quantopian
Quantopian aimed to create a crowd-sourced hedge fund by letting freelance quantitative analysts develop, test, and use trading algorithms to buy and sell securities. In November 2020, Quantopian announced it will shut down after having operated for 9 years.(Quantopian致力于创建一个众包对冲基金,让自由量化分析师开发、测试和使用交易算法来买卖证券。2020年11月,运营9年的Quantopian宣布关闭。)
Quantopian公司关停之后,代码放在GitHub上,但是鉴于没人维护?(在其他帖子看到Q公司许诺会一直维护)本书作者Stefan Jansen维护了ziplinie-reloaded
zipline-reloaded · PyPI![]() https://pypi.org/project/zipline-reloaded/Zipline适用于在数千个证券的规模下运行,每个证券都可以与大量的指标相关联。例如,它比backtrader在回溯测试过程中施加了更多的结构,通过消除向前看的偏差来确保数据质量,并在执行回溯测试时优化计算效率。(第四章、第五章已经介绍过Quantopian旗下zipline、Alphalens、pyfolio几个包了,可以回看一下)
https://pypi.org/project/zipline-reloaded/Zipline适用于在数千个证券的规模下运行,每个证券都可以与大量的指标相关联。例如,它比backtrader在回溯测试过程中施加了更多的结构,通过消除向前看的偏差来确保数据质量,并在执行回溯测试时优化计算效率。(第四章、第五章已经介绍过Quantopian旗下zipline、Alphalens、pyfolio几个包了,可以回看一下)
打开上面链接,里面有zipline的一个quickstart
5.1 Calendars and the Pipeline 让拟合更稳健
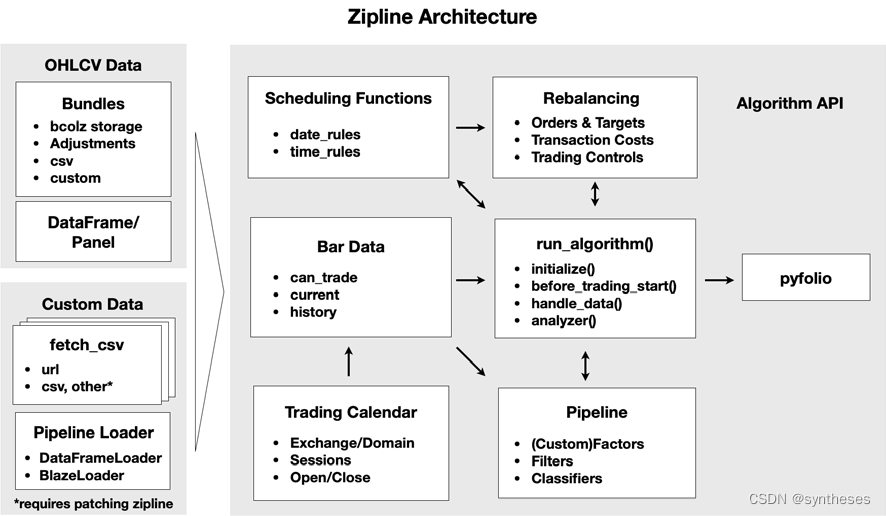
有助于实现可伸缩性和可靠性目标的主要特性是:存储OHLCV市场数据的数据包,其中包含对分割和股息的动态调整,反映全球交易所的操作时间的交易日历,以及强大的Pipeline API(见下图)。(OHLCV是市场数据的集合形式,分别代表开盘、高位、低位、收盘和成交量。)
Welcome to bcolz’s documentation! — bcolz 1.2.0 documentation
Bundles:实时调整的时间点数据
5.2 获取自己的分钟数据的bundle
5.3 The Pipeline API:对ML信号进行回测
5.4 如何在回测过程中训练模型
包含很多金融指标的talib资源库:TA-Lib : Technical Analysis Library - Home