elasticsearch kibana + 分词器安装详细步骤
一、准备环境
系统:Centos7
JDK安装包:jdk-8u191-linux-x64.tar.gz
ES安装包:elasticsearch-7.2.0-linux-x86_64.tar.gz,下载地址
Kibana安装包:kibana-7.2.0-linux-x86_64.tar.gz,下载地址
IK分词器安装包:elasticsearch-analysis-ik-7.2.0.zip,下载地址
目前准备两个节点做节点规划,分别是
192.168.56.105、192.168.56.106
首先需要将JAVA环境安装完毕,目前的ES版本使用的是1.9版本的JDK,但是在安装包中已经包含了1.9的版本,所以我们自己可以使用1.8的,最终ES检测是否安装了1.9版本的,如果没有安装则使用自己安装包内的JDK。
#分别在两台机器上创建用户和用户组,这里每台机器上创建两个用户,后面涉及到单台机器多节点安装直接使用,如果只是单台机器单节点安装,每台建一个用户就行,主要是起到一个隔离作用,而且ES不能通过root用户启动
$ groupadd elastic
$ useradd -g elastic elastic1
$ useradd -g elastic elastic2
$ passwd elastic1
$ passwd elastic2
#关闭防火墙,禁止开机启动
$ systemctl stop firewalld
$ systemctl disable firewalld二、每台机器单节点集群
在做当前类型的安装的时候只使用elastic1用户,后面需要单机安装多节点的时候才用elastic2用户
#我是安装在/opt目录 分别对两台机器做如下操作
root@localhost$ tar -zxvf elasticsearch-7.2.0-linux-x86_64.tar.gz
root@localhost$ mv elasticsearch-7.2.0 elasticsearch-7.2.0-elastic1
#设置目录属于elastic1用户elastic用户组
root@localhost$ chown -R elastic1:elastic elasticsearch-7.2.0-elastic1
如上内容设置完成之后,进行配置ES,在进行配置之前:
192.168.56.105节点作为master
192.168.56.106节点作为slave1
master(105)节点 config/elasticsearch.yml文件配置:
#集群名称
cluster.name: es_cluster
#节点角色名称
node.name: master
#当前主机Host
network.host: 192.168.56.105
#http端口
http.port: 9200
#tcp端口
transport.tcp.port: 9300
#是否为master节点
node.master: true
#是否作为数据节点
node.data: true
#这里是跨域相关内容的配置
http.cors.enabled: true
http.cors.allow-origin: "*"
#这里代表的是当前服务器上运行几个节点的ES实例
node.max_local_storage_nodes: 1
#符合master要求的节点,目前就只有一个,ES是自己内部实现了高可用的,所以可以多master
cluster.initial_master_nodes: ["192.168.56.105"]
#日志存储位置(不配置默认在安装包路径)
path.logs: /opt/elastic1/logs
#数据存储位置(不配置默认在安装包路径)
path.data: /opt/elastic1/dataslave1(106)节点 config/elasticsearch.yml文件配置:
cluster.name: es_cluster
node.name: slave1
network.host: 192.168.56.106
http.port: 9200
transport.tcp.port: 9300
node.data: true
http.cors.enabled: true
http.cors.allow-origin: "*"
node.max_local_storage_nodes: 1
#这里填写的是master节点的IP和TCP端口,有多少master填多少个,主要是用来做心跳检测和数据交互
discovery.seed_hosts: ["192.168.56.105:9300"]
path.logs: /opt/elastic1/logs
path.data: /opt/elastic1/data如果在真实项目中还需要设置节点堆栈内存,默认是1G
config/jvm.options
-Xms1g
-Xmx1g设置内存的时候根据自己情况设置,但是最好别超过32G,我在真实项目中设置的是31G因为超过的话会存在大内存问题,会造成内存资源浪费。
如上内容设置完成之后可以进行启动测试,启动的时候需要切到指定用户去启动,因为ES不能使用root启动,并且启动的时候很可能会报错,报错看下面解决办法,需要设置一些系统参数
# 终端启动运行
$ ./bin/elasticsearch
# 后台启动运行
$ ./bin/elasticsearch -d三、每台机器多节点集群
每台机器上安装2个ES节点(两个ES实例)相关配置方式,目前规划
192.168.56.105
elastic1:masterelastic2:slave2
192.168.56.106
elastic1:slave1elastic2:slave2
根据上面的操作,准备好相关的包,并且设置好相关的权限,设置完成之后进行配置,目前是两台机器,四个ES节点(实例)
相关配置:
在进行相关配置的时候可以直接从另外一个slave节点copy一份配置文件来进行修改
192.168.56.105-master(elaster1):config/elasticsearch.yml
#只需要修改每台机器上能够部署的节点数就可以,其他的和上面的配置相同
node.max_local_storage_nodes: 2192.168.56.105-slave2(elaster2):config/elasticsearch.yml
cluster.name: es_cluster
#修改节点名称
node.name: slave2
network.host: 192.168.56.105
#这里需要修改端口,不能和master节点冲突
http.port: 9201
#这里需要修改端口,不能和master节点冲突
transport.tcp.port: 9301
node.data: true
http.cors.enabled: true
http.cors.allow-origin: "*"
#将机器能够部署的节点数进行修改
node.max_local_storage_nodes: 2
#这里填写的是master节点的IP和TCP端口,有多少master填多少个,主要是用来做心跳检测和数据交互
discovery.seed_hosts: ["192.168.56.105:9300"]
path.logs: /opt/elastic2/logs
path.data: /opt/elastic3/data192.168.56.106-slave1(elaster1):config/elasticsearch.yml
# 根据上面的配置修改机器能够部署的节点数,其他参数不变
node.max_local_storage_nodes: 2192.168.56.106-slave2(elaster2):config/elasticsearch.yml
cluster.name: es_cluster
#修改节点名称
node.name: slave2
#修改节点ip
network.host: 192.168.56.106
#这里需要修改端口,不能和master节点冲突
http.port: 9201
#这里需要修改端口,不能和master节点冲突
transport.tcp.port: 9301
node.data: true
http.cors.enabled: true
http.cors.allow-origin: "*"
#将机器能够部署的节点数进行修改
node.max_local_storage_nodes: 2
#这里填写的是master节点的IP和TCP端口,有多少master填多少个,主要是用来做心跳检测和数据交互
discovery.seed_hosts: ["192.168.56.105:9300"]
path.logs: /opt/elastic2/logs
path.data: /opt/elastic3/data如上内容配置完成之后进行各个节点的启动,启动的时候不同节点需要使用不同用户进行启动,这样能保证程序的隔离性,包括在停进程的时候也是,如果都启动完成了,可以通过root账户进行jps命令进行检查实例是否存在两个。
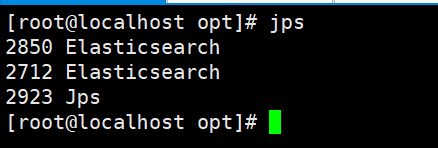
105-elastic1$ ./bin/elasticsearch -d
105-elastic2$ ./bin/elasticsearch -d
106-elastic1$ ./bin/elasticsearch -d
106-elastic2$ ./bin/elasticsearch -d
#关闭es,直接kill 进程,当然最好是到指定用户下进行kill这样能够区分,不容易混淆注:其实单台机器装多个节点只需要注意同一机器上的节点端口不要重复就行,其他的配置和横向扩展没区别
四、kibana安装和分词器安装
安装Kibana
$ tar -zxvf kibana-7.2.0-linux-x86_64.tar.gz
kibana只是一个客户端,主要是方便自己管理和查看ES集群状态,并且提供了一些数据分析的功能,数据查询工具,索引管理以及监控等功能,所以装在一台机器上就行,目前就装在192.168.56.105机器上,可以设置为和master节点相同的用户和用户组也可以直接用elastic1
kibana-7.2.0-linux-x86_64/config/kibana.yml配置
#当前kibana所提供服务的节点地址
server.host: "192.168.8.108"
#服务名称
server.name: "yourkibana"
#连接的ES集群,连接master就行
elasticsearch.hosts: ["http://192.168.8.108:9200"]
#设置请求超时时间,默认是30000
elasticsearch.requestTimeout: 90000配置完成之后启动验证是否成功
#现在终端启动,看看日志有没有报错的,没有的话再后台启动
$ ./bin/kibana
$ nohup ../bin/kibana &访问Kibana
默认访问的端口是5601,地址是自己配置的地址,我这里是http://192.168.56.105:5601
Elasticsearch安装中文分词插件:
安装IK中文分词插件,将下载好的分词包安装解压然后放入到ES/plugin目录就可以了,但是在安装的时候要注意看版本之间的联系,刚开始的时候我使用的是7.5版本的分词器,安装的时候版本不兼容,后面下载了7.2版本的
$ yum install -y unzip
$ unzip -d ik elasticsearch-analysis-ik-7.2.0.zip
$ cp -r ik/ elasticsearch-7.2.0-elastic1/plugins/
$ cp -r ik/ elasticsearch-7.2.0-elastic2/plugins/
$ scp -r ik/ 192.168.56.106:/opt/elasticsearch-7.2.0-elastic1/plugins/
$ scp -r ik/ 192.168.56.106:/opt/elasticsearch-7.2.0-elastic2/plugins/
#登录到不同的节点去修改对应的ik文件夹的权限
$ chown -R elastic1:elastic /opt/elasticsearch-7.2.0-elastic1/plugins/上面操作完成后,重启集群,然后验证是否能够进行正常的中文分词

如上图所示,能够对中文进行正确的分词,说明分词器安装成功
五、启动错误问题及解决办法
ERROR: [3] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[3]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
解决办法:
编辑/etc/security/limits.conf,追加以下内容
* soft nofile 65536
* hard nofile 65536当前内容设置完成之后需要重新登录才能生效
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决办法:
编辑文件/etc/sysctl.conf,追加一下内容:
vm.max_map_count=655360编辑完成之后保存,并执行sysctl -p命令
[3]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
解决办法:
出现上面两个错误说明没有在配置文件中配置好ES,需要配置上面中括号中的参数,具体的配置根据节点角色定,该问题一般不会遇到
[4]: max number of threads [2048] for user [tongtech] is too low, increase to at least [4096]
解决办法:
编辑文件/etc/security/limits.d/20-nproc.conf,修改文件中的数值
* soft nproc 65535
root soft nproc unlimited以上内容修改完成之后启动ES,查看ES是否能够正常启动成功
Likely root cause: java.nio.file.AccessDeniedException: /opt/elasticsearch-7.2.0-elastic1/config/elasticsearch.keystore
出现这个错误说明没有权限,看下confg/elasticsearch.keystore文件是否拥有相关权限,如果么有权限,则进行设置
root@localhost$ chown -R elastic1:elastic elasticsearch.keystore