1.1、数据由来
一些数据平台和政府企业公开的数据,这些数据基本上在企业级应用中没啥大的作用。
真正有用的数据还是需要爬虫工程师来爬去。
1.2、什么是爬虫
1、爬虫的定义
脚本,程序--->自动抓取万维网上信息的程序。
2、爬虫的分类
- 通用爬虫
- 聚焦爬虫
3、爬虫的作用
- 解决冷启动的问题。
搜索引擎的根基。做搜索引擎,必须使用爬虫。
- 帮助机器学习建立知识图谱。
- 机器学习最终的是训练集。训练集可以靠爬虫爬去
可以制作比较软件。
1.3、爬虫工程师的发展历程
1、初级工程师
- web 前端的知识: HTML、CSS、JavaSc1ipt、 DOM、 DHTML 、Ajax、jQuery、json 等;
- 正则表达式, 能提取正常一般网页中想要的信息,比如某些特殊的文字, 链接信息, 知道什么是懒惰, 什么是贪婪型的正则;
- 会使用 XPath 等获取一些DOM 结构中的节点信息;
- 知道什么是深度优先, 广度优先的抓取算法, 及实践中的使用规则;
- 能分析简单网站的结构, 会使用urllib或requests 库进行简单的数据抓取。
在解决web项目问题时,流程如下:
前端---> javascript---> python---> sql查询--->数据库
2、中级工程师
了解什么是Hash,会简单地使用MD5,SHA1等算法对数据进行Hash一遍存储
熟悉HTTP,HTTPS协议的基础知识,了解GET,POST方法,了解HTTP头中的信息,包括返回状态码,编码,user-agent,cookie,session等
能设置user-agent进行数据爬取,设置代理等
知道什么事Request,什么事response,会使用Fiddler等工具抓取及分析简单地网络数据包;对于动态爬虫,要学会分析ajax请求,模拟制造post数据包请求,抓取客户端session等信息,对于一些简单的网站,能够通过模拟数据包进行自动登录。
对于一些难搞定的网站学会使用phantomjs+selenium抓取一些动态网页信息
并发下载,通过并行下载加速数据爬取;多线程的使用。
多线程就是利用计算机的cpu,使cpu的利用变高,使程序运行速度加快。
3、高级工程师
- 能够使用Tesseract,百度AI,HOG+SVM,CNN等库进行验证码识别。
- 能使用数据挖掘技术,分类算法等避免死链。
- 会使用常用的数据库进行数据存储,查询。比如mongoDB,redis;学习如何通过缓存避免重复下载的问题。
- 能够使用机器学习的技术动态调整爬虫的爬取策略,从而避免被禁IP封禁等。
- 能使用一些开源框架scrapy,scrapy-redis等分布式爬虫,能部署掌控分布式爬虫进行大规模数据爬取。
1.4、搜索引擎
1、搜索引擎的定义
搜索引擎就是运行一些策略和算法,从互联网上获取网页信息,并将这些信息做一些处理之后保存起来,再为用户提供检索服务的一种程序,系统。
2、搜索引擎的组成
主要组成就是通用爬虫。
3、通用爬虫
通用爬虫的定义
就是将互联网上的网页【整体】爬去下来,保存到本地的程序。搜索引擎可以获取所有网页的原因
搜索引擎通过不同url将所有网页都保存到了本地。
探索引擎搜索url来源:
- 新网站会主动向搜索引擎提交自己的网址。
- 在其他网站上设置的外链会被搜索引擎加入到url队列。
- 搜索引擎和dns解析商合作,如果有新网站注册,搜索引擎就可以获取网址。
4、搜索引擎的工作过程
- (1)使用通用爬虫来抓取网页
- (2)数据的存储。
先将网页内容进行一定的去重操作,最后才保存。 - (3)预处理
- 提取出文字
- 中文分词。
- 消除噪音(广告,导航栏,版权声明文字。)
- 索引处理。
- (4)设置网站排名,为用户提供检索服务。
5、通用爬虫的缺陷:
(1)只能爬取原网页,但是一般网页中90%的内容都是无用的。
(2)不能满足不同行业、不同人员的不同需求。
(3)只能获取文字,不能获取视频,音频,文件等内容。
(4)只能通过关键字查询,无法支持语义查询。
6、聚焦爬虫:
在实施网页抓取时,会对内容进行筛选,尽量保证之抓取与需求相关的数据。
1.5、爬虫的准备工作
1、robots协议
定义:网络爬虫排除标准
作用:告诉搜索引擎哪些可以爬哪些不能爬。
2、sitemap:网站地图,可以帮助我们了解一个网站的结构。
3、估算网站的大小
site:www.taobao.com
1.6、Http和Https
1、什么是http协议?
是一种规范。--->约束发布和接受html页面的规范。
2、http协议的端口号:80
https端口:443
3、http协议的特点:
(1)基于应用层的协议。
(2)无连接
在http1.0之前每次发送http都是单独连接,自从http1.1之后,只需设置一个请求头Connection,就可以做到一个长连接。
(3)无状态。
http协议不记录状态,每次请求,如果想要到之前请求的内容,必须单独发送。为了解决这种问题,产生一种技术,就叫cookie和session。
4、url:统一资源定位符
(1)作用
用来定位互联网上的任意资源的位置。
(2)为什么url可以用来定位任意资源?
http://127.0.0.1:8000/index.html
scheme:htttp协议
netloc:网络地址(127.0.0.1)
互联网上定位一个计算机,主要是通过ip:port。
path:资源在服务器的相对路径。
url包含的netloc可以定位到任何计算机,进入计算机后通过path就可以找到想要的资源。
(3)url中的特殊符号。
?:问号后面是get请求的请求参数。
&:多个get请求参数拼接使用&
#: 锚点--->帮助我们访问这个链接时,页面可以定位锚点位置。
注意:在爬虫中,当我们爬去的url有锚点时,记得删掉。
(4)python的urllib下的parse模块可以帮助我们解析一个url
from urllib import parse
url = 'https://localhost:9999/bin/index.html?usename=zhangsanY&password=123#bottom'
parse_result = parse.urlparse(url)
print(parse_result)
print(parse_result.netloc)
print(parse_result.path)
运行结果:
ParseResult(
scheme='https',
netloc='localhost:9999',
path='/bin/index.html',
params='',
query='usename=zhangsanY&password=123',
fragment='bottom')
localhost:9999
/bin/index.html5、http的工作过程:
(1)地址解析:客户端解析出url的每一个部分
(2)分装http请求数据包
(3)封装tcp数据包,通过三次握手建立tcp连接。
(4)客户端发送请求
(5)服务器发送响应。
(6)关闭tcp连接
6、http的工作过程有几下几点要特别注意:
1、我们在浏览器中输入一个url,先要经过前三步,而不是直接发送请求的。
2、要明白客户端请求和服务器响应所在的位置。
7、当我们在浏览器中输入一个url,客户端是如何加载出整个页面的?
(1)客户端解析url,封装数据包,建立连接,给服务发送请求。
(2)服务从数据包中解析出客户端想要获取的页面,比如index.html,就把该页面按层封装成对应数据包传递给客户端。客户端在解析数据包,拿到对应index.html页面。
(3)客户端检查该index.html页面中是否有静态资源,比如js文件,image文件,css文件,如果有,在分别从服务器上请求获取这些资源。
(4)客户端获取到所有资源之后,按照html的语法,将index.html完整的显示出来。
8、客户端请求
- (1)组成:
- 请求行:包括协议版本号,地址,请求方法
- 请求头
- 空行
- 请求数据
(2)重要的请求头:
- User-Agent:客户端标识。
- accept:允许传入的文件类-
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8
Referer:表示产生请求的网页来自于那个网页。
防盗链:新浪现在所有的网页都设置一个判断流程,在请求新闻页面时,先查看referer这个头是不是表示我们新浪网站,如果是,就说明访问路劲正确,才给数据,如过不是,就是盗用,直接不给数据。- cookie:有些网页如果你用request模块无法获取数据,同事他返回的内容一般有cookie这个单词,此时就表示你需要在请求的过程中封装cookie头;在登录的过程中,cookie的作用也很大。
- content-type:post请求的数据类型。
- content-length:post请求的请求数据的长度。
x-requested-with:xmlhttprequest--xhr---》当我们发送一个ajax接口数据,想要获取数据内容,必须封装这个头,这个头就表示这个请求是一个ajax。
9、服务器响应
(1)组成:
- 状态行:http协议版本、状态码
- 响应头
- 空行
- 响应正文:如果请求一个html页面,响应正文就是这个html文件的内容。
(2)响应头:
- content-type:返回数据类型,告诉客户端,返回的资源类文件的类型是什么。
(3)状态码
1XX->100~199:表示服务器成功接受部分请求,还需要发剩余请求才能处理整个过程。
2XX:表示服务器成功接受请求并已经处理完整个过程。
200 ok3XX:为了完成请求,客户端必须进一步细化请求。
如果请求资源已经移动到其他位置,常用就是302重定向。
304使用缓存资源。4XX:客户端请求错误。404-服务器无法找到请求内容。
403-服务器拒绝访问,权限不够5XX:服务器发生错误。
502服务器发生错误。
500,请求未完成,服务器遇到不可知问题。如果遇到面试题,请求说出常见的状态码?
回答思路应该是,先说出分类,在列举几个。
https://blog.csdn.net/qq_35689573/article/details/82120851
1.7、Hash算法
1.定义
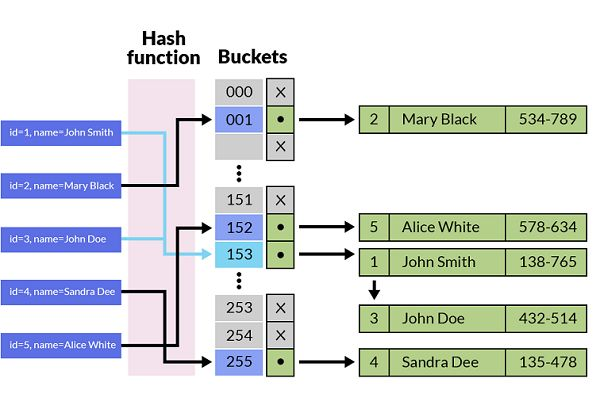
Hash :散列,通过关于键值(key)的函数,将数据映射到内存存储中一个位置来访问。这个过程叫做Hash,这个映射函数称做散列函数,存放记录的数组称做散列表(Hash Table),又叫哈希表。
简单地说,它是密码学中的一个重要的函数,一般以 表示 。这个函数可以将任意一段数据(一般称这段数据为“消息”)压缩成固定长度的字符串(一般称输出的字符串为“摘要”)。哈希函数需要满足下述条件:
- 确定性:哈希函数的算法是确定性算法,算法执行过程不引入任何随机量。这意味着相同消息的哈希结果一定相同。
- 高效性:给定任意一个消息m,可以快速计算
- 目标抗碰撞性:给定任意一个消息m1,很难找到另一个消息m2,使得
- 广义抗碰撞性:很难找到两个消息m0不等于m1的情况下,使得
2、优点
先分类,再查找,通过计算,缩小范围,加快查找速度3、 Hash的作用
数字签名:给数据打指纹
比如我们下载一个文件,文件的下载过程中会经过很多网络服务器、路由器的中转,如何保证这个文件就是我们所需要的呢?我们不可能去一一检测这个文件的每个字节,也不能简单地利用文件名、文件大小这些极容易伪装的信息,这时候,我们就需要一种指纹一样的标志来检查文件的可靠性,这种指纹就是我们现在所用的Hash算法(也叫散列算法)。
密码存储
在用户进行网站登录时,如果服务器直接存储用户密码,则如果服务器被攻击者所攻击,用户的密码就会遭到泄露。最典型的事件就是CSDN的密码明文存储事件了。为了解决这个问题,服务器可以仅存储用户密码的哈希结果。当用户输入登录信息后,服务器端可以计算密码的哈希结果,并与存储的哈希结果进行对比,如果结果相同,则允许用户登录。由于服务器不直接存储用户密码,因此即使服务器被攻击者攻击,用户的密码也不会被泄露。这也是为什么我们在使用【找回密码】功能时,服务器直接请求输入新的密码,而不是把原始密码发送给我们。
4.hash算法的特性
正向快速:给定明文和 hash 算法,在有限时间和有限资源内能计算出 hash 值。
逆向困难:给定(若干) hash 值,在有限时间内很难(基本不可能)逆推出明文。
输入敏感:原始输入信息修改一点信息,产生的 hash 值看起来应该都有很大不同。
冲突避免:很难找到两段内容不同的明文,使得它们的 hash 值一致(发生冲突)。
即对于任意两个不同的数据块,其hash值相同的可能性极小;对于一个给定的数据块,找到和它hash值相同的数据块极为困难。所以因为他的不可逆性,hash算法常常用来给一些信息加密,因为这种不可逆性,你不仅不可能根据一段通过散列算法得到的指纹来获得原有的文件,也不可能简单地创造一个文件并让它的指纹与一段目标指纹相一致。
5.hash算法(了解)
(1)直接定值法:取Key或者Key的某个线性函数值为散列地址。
(2)数字分析法:需要知道Key的集合,并且Key的位数比地址位数多,选择Key数字分布均匀的位。
Hash(Key) 取六位:
列数 : 1 (2) 3 (4) 5 (6) (7) 8 (9) 10 11 12 (13)
key1: 5 2 4 2 7 5 8 5 3 6 5 1 3
key2: 5 4 4 8 7 7 7 5 4 8 9 5 1
key3: 3 1 5 3 7 8 5 4 6 3 5 5 2
key4: 5 3 6 4 3 2 5 4 5 3 2 6 4
其中(2、4、6、7、9、13) 这6列数字无重复,分布较均匀,取此六列作为Hash(Key)的值。
Hash(Key1) :225833
Hash(Key2):487741
Hash(Key3):138562
Hash(Key4):342554
(3)平方取中法:取Key平方值的中间几位作为Hash地址。
(4)折叠法:将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后 取这几部分的叠加和(舍去进位)作为哈希地址。 当Key的位数较多的时候数字分布均匀适合采用这种方案.
(5)随机数法:伪随机探测再散列。
具体实现:建立一个伪随机数发生器,Hash(Key) = random(Key). 以此伪随机数作为哈希地址。
(6)除留余数法:取关键字被某个除数 p 求余,得到的作为散列地址。
即 H(Key) = Key % p;
6.Hash有哪些流行的算法
目前流行的 Hash 算法包括 MD5、SHA-1 和 SHA-2。
- MD4(RFC 1320)是 MIT 的 Ronald L. Rivest 在 1990 年设计的,MD 是 Message Digest 的缩写。其输出为 128 位。MD4 已证明不够安全。
- MD5(RFC 1321)是 Rivest 于1991年对 MD4 的改进版本。它对输入仍以 512 位分组,其输出是 128 位。MD5 比 MD4 复杂,并且计算速度要慢一点,更安全一些。MD5 已被证明不具备”强抗碰撞性”。
SHA (Secure Hash Algorithm)是一个 Hash 函数族,由 NIST(National Institute of Standards and Technology)于 1993 年发布第一个算法。目前知名的 SHA-1 在 1995 年面世,它的输出为长度 160 位的 hash 值,因此抗穷举性更好。SHA-1 设计时基于和 MD4 相同原理,并且模仿了该算法。SHA-1 已被证明不具”强抗碰撞性”。
为了提高安全性,NIST 还设计出了 SHA-224、SHA-256、SHA-384,和 SHA-512 算法(统称为 SHA-2),跟 SHA-1 算法原理类似。SHA-3 相关算法也已被提出。
7、何谓Hash算法的「碰撞」
如果两个key通过hash函数处理之后得到的散列值相同,这种情况就叫做散列算法的碰撞(collision)。
现代散列算法所存在的理由就是,它的不可逆性能在较大概率上得到实现,也就是说,发现碰撞的概率很小,这种碰撞能被利用的概率更小。
7.1MD5碰撞案例
import hashlib
# 两段HEX字节串,注意它们有细微差别
a = bytearray.fromhex("0e306561559aa787d00bc6f70bbdfe3404cf03659e704f8534c00ffb659c4c8740cc942feb2da115a3f4155cbb8607497386656d7d1f34a42059d78f5a8dd1ef")
b = bytearray.fromhex("0e306561559aa787d00bc6f70bbdfe3404cf03659e744f8534c00ffb659c4c8740cc942feb2da115a3f415dcbb8607497386656d7d1f34a42059d78f5a8dd1ef")
# 输出MD5,它们的结果一致
print(hashlib.md5(a).hexdigest())
print(hashlib.md5(b).hexdigest())
这样的例子还有很多。因此,MD5在数年前就已经不被推荐作为应用中的散列算法方案,取代它的是SHA家族算法,也就是安全散列算法(Secure Hash Algorithm,缩写为SHA)。
7.2 SHA家族算法以及SHA1碰撞
SHA家族算法的种类很多,有SHA0、SHA1、SHA256、SHA384等等,它们的计算方式和计算速度都有差别。其中SHA1是现在用途最广泛的一种算法。包括GitHub在内的众多版本控制工具以及各种云同步服务都是用SHA1来区别文件,很多安全证书或是签名也使用SHA1来保证唯一性。长期以来,人们都认为SHA1是十分安全的,至少大家还没有找到一次碰撞案例。
hash在知乎上的一遍经典文章:https://www.zhihu.com/question/56234281/answer/148349930