一、爬虫介绍
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
- 总之
只要是浏览器能做的事情,原则上,爬虫都能够做
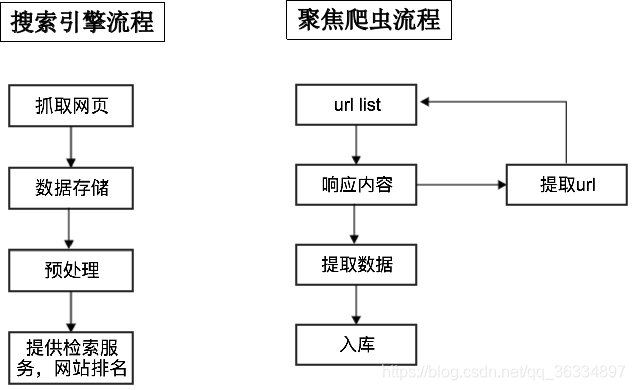
二、分类
-
通用爬虫
通常指搜索引擎的爬虫 -
聚焦爬虫
针对特定网站的爬虫 -
流程
三、通用搜索引擎局限性 -
通用搜索引擎所返回的网页里90%的内容无用。
-
图片、音频、视频多媒体的内容通用搜索引擎无能为力
-
不同用户搜索的目的不全相同,但是返回内容相同
四、ROBOTS协议
网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。 -
例如
https://www.taobao.com/robots.txt
五、HTTP和HTTPS -
HTTP
超文本传输协议 ,默认端口号:80 -
HTTPS
HTTP + SSL(安全套接字层),默认端口号:443 -
状态码
200:成功
302:临时转移至新的url
307:临时转移至新的url
404:not found
500:服务器内部错误 -
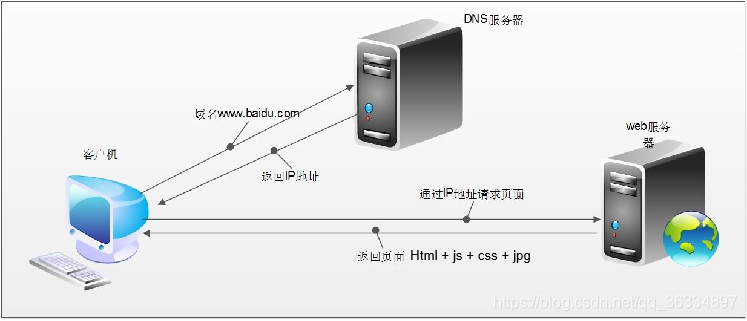
浏览器发送HTTP请求的过程
六、str和bytes之间的相互转化 -
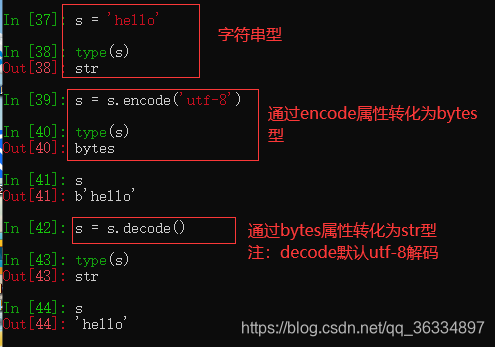
str 使用encode方法转化为 bytes
-
bytes通过decode转化为str