1 import numpy as np 2 import matplotlib.pyplot as plt 3 from sklearn.linear_model import LinearRegression 4 from sklearn.datasets import make_regression 5 from sklearn.model_selection import train_test_split 6 7 X,y = make_regression(n_samples=100,n_features=2,n_informative=2,random_state=38) 8 X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=8) 9 lr = LinearRegression().fit(X_train,y_train) 10 11 print('lr.coef_:{}'.format(lr.coef_[:])) 12 print('lr.intercept_:{}'.format(lr.intercept_)) 13 14 # X,y = make_regression(n_samples=50,n_features=1,n_informative=1,noise=50,random_state=1) 15 # 16 # reg = LinearRegression() 17 # reg.fit(X,y) 18 # z = np.linspace(-3,3,200).reshape(-1,1) 19 # plt.scatter(X,y,c='b',s=60) 20 # plt.plot(z,reg.predict(z),c='k') 21 22 23 # X = [[1],[4],[3]] 24 # y = [3,5,3] 25 # lr = LinearRegression().fit(X,y)#线性模型拟合这两个点 26 # z = np.linspace(0,5,20)#画出两个点以及函数 27 # plt.scatter(X,y,s=80) 28 # plt.plot(z,lr.predict(z.reshape(-1,1)),c='k') 29 # plt.title('Straight Line') 30 # plt.show() 31 #print('y = {:,.3f}'.format(lr.coef_[0]),'x','+{:,.3f}'.format(lr.intercept_)) 32 #拟合数据时,求线性方程的系数 33 # print('直线的系数为:{:,.2f}'.format(reg.coef_[1])) 34 # print('直线的截距是:{:,.2f}'.format(reg.intercept_)) 35 print('训练集得分:{:,.2f}'.format(lr.score(X_test,y_test)))
以上是线性模型的一些基础部分的知识,分割数据集,求得分等,以及包括求线性函数的参数等基础知识
在依次执行代码后获得到如下的图
线型回归的图:
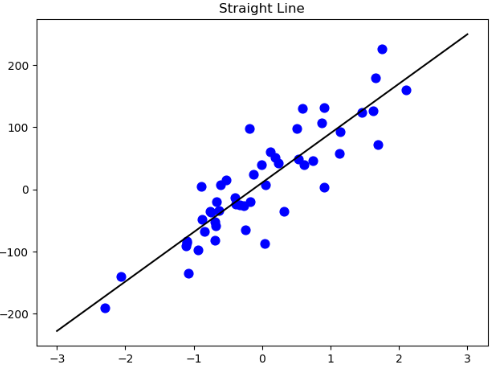
通过运行上面的代码可以发现,训练集和测试集的得分均为1.00,当然这说明了模型的高度拟合,但是这也是因为没有在我们的数据中加入影响因素noise导致的,在实际的数据集中会有各种因素的影响,
那就加入noise再进行测试吧。
1 import numpy as np 2 import matplotlib.pyplot as plt 3 from sklearn.linear_model import LinearRegression 4 from sklearn.datasets import make_regression 5 from sklearn.model_selection import train_test_split 6 from sklearn.datasets import load_diabetes 7 X,y = load_diabetes().data,load_diabetes().target 8 X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=8) 9 lr = LinearRegression().fit(X_train,y_train) 10 print('训练集得分:{:,.2f}'.format(lr.score(X_train,y_train))) 11 print('测试集得分:{:,.2f}'.format(lr.score(X_test,y_test)))
在对上述代码进行运行后,可以发现训练集和测试集间的得分间存在一定的差异,这是因为模型过拟合导致的。在实际应用的过程中会采用伊西俄方法来避免过拟合。
存在三种情况:(1)欠拟合,(2)拟合(也是我们所追求的)(3)过拟合(这种情况比欠拟合更加麻烦)