结论:蒸馏是个好方法。
模型压缩/蒸馏在论文《Model Compression》及《Distilling the Knowledge in a Neural Network》提及,下面介绍后者及使用keras测试mnist数据集。
蒸馏:使用小模型模拟大模型的泛性。
通常,我们训练mnist时,target是分类标签,在蒸馏模型时,使用的是教师模型的输出概率分布作为“soft target”。也即损失为学生网络与教师网络输出的交叉熵(这里采用DistilBert论文中的策略,此论文不同)。
当训练好教师网络后,我们可以不再需要分类标签,只需要比较2个网络的输出概率分布。当然可以在损失里再加上学生网络的分类损失,论文也提到可以进一步优化。
如图,将softmax公式稍微变换一下,目的是使得输出更小,softmax后就更为平滑。
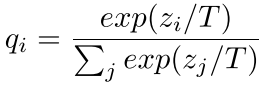
论文的损失定义

本文代码使用的损失为p和q的交叉熵
代码测试部分
1,教师网络,测试精度99.46%,已经相当好了,可训练参数858,618。
# 教师网络 inputs=Input((28,28,1)) x=Conv2D(64,3)(inputs) x=BatchNormalization(center=True,scale=False)(x) x=Activation('relu')(x) x=Conv2D(64,3,strides=2)(x) x=BatchNormalization(center=True,scale=False)(x) x=Activation('relu')(x) x=Conv2D(128,5)(x) x=BatchNormalization(center=True,scale=False)(x) x=Activation('relu')(x) x=Conv2D(128,5)(x) x=BatchNormalization(center=True,scale=False)(x) x=Activation('relu')(x) x=Flatten()(x) x=Dense(100)(x) x=BatchNormalization(center=True,scale=False)(x) x=Activation('relu')(x) x=Dropout(0.3)(x) x=Dense(10,activation='softmax')(x) model=Model(inputs,x) model.compile(optimizer=optimizers.SGD(momentum=0.8,nesterov=True),loss=categorical_crossentropy,metrics=['accuracy']) model.summary() model.fit(X_train,y_train,batch_size=128,epochs=30,validation_split=0.2,verbose=2) # 重新编译后,完整数据集训练18轮,原始16轮后开始过拟合,训练集变大后不易过拟合,这里增加2轮 model.fit(X_train,y_train,batch_size=128,epochs=18,verbose=2) model.evaluate(X_test,y_test)# 99.46%
2,学生网络,测试精度99.24%,可训练参数164,650,不到原来的1/5。
# 定义温度 tempetature=3 # 学生网络 inputs=Input((28,28,1)) x=Conv2D(16,3)(inputs) x=BatchNormalization(center=True,scale=False)(x) x=Activation('relu')(x) x=Conv2D(16,3)(x) x=BatchNormalization(center=True,scale=False)(x) x=Activation('relu')(x) x=Conv2D(32,5)(x) x=BatchNormalization(center=True,scale=False)(x) x=Activation('relu')(x) x=Conv2D(32,5,strides=2)(x) x=BatchNormalization(center=True,scale=False)(x) x=Activation('relu')(x) x=Flatten()(x) x=Dense(60)(x) x=BatchNormalization(center=True,scale=False)(x) x=Activation('relu')(x) x=Dropout(0.3)(x) x=Dense(10,activation='softmax')(x) x=Lambda(lambda t:t/tempetature)(x)# softmax后除以温度,使得更平滑 student=Model(inputs,x) student.compile(optimizer=optimizers.SGD(momentum=0.9,nesterov=True),loss=categorical_crossentropy,metrics=['accuracy']) # 使用老师和学生概率分布结果的软交叉熵,即除以温度后的交叉熵 student.fit(X_train,model.predict(X_train)/tempetature,batch_size=128,epochs=30,verbose=2)
最后测试一下
student.evaluate(X_test,y_test/tempetature)# 99.24%
3,继续减少参数,去除Dropout和BN,前期卷积使用步长,精度98.80%。参数72,334,大约原来的1/12。
# 定义温度 tempetature=3 # 学生网络 inputs=Input((28,28,1)) x=Conv2D(16,3,activation='relu')(inputs) # x=BatchNormalization(center=True,scale=False)(x) # x=Activation('relu')(x) x=Conv2D(16,3,strides=2,activation='relu')(x) # x=BatchNormalization(center=True,scale=False)(x) # x=Activation('relu')(x) x=Conv2D(32,5,activation='relu')(x) # x=BatchNormalization(center=True,scale=False)(x) # x=Activation('relu')(x) x=Conv2D(32,5,activation='relu')(x) # x=BatchNormalization(center=True,scale=False)(x) # x=Activation('relu')(x) x=Flatten()(x) x=Dense(60,activation='relu')(x) # x=BatchNormalization(center=True,scale=False)(x) # x=Activation('relu')(x) # x=Dropout(0.3)(x) x=Dense(10,activation='softmax')(x) x=Lambda(lambda t:t/tempetature)(x)# softmax后除以温度,使得更平滑 student=Model(inputs,x) student.compile(optimizer=optimizers.SGD(momentum=0.9,nesterov=True),loss=categorical_crossentropy,metrics=['accuracy']) student.fit(X_train,model.predict(X_train)/tempetature,batch_size=128,epochs=30,verbose=2) student.evaluate(X_test,y_test/tempetature)# 98.80%