类似文章:
Keras实现预训练网络VGG16迁移学习——CIFAR10分类【80行代码训练&预测&评估】
一、保存模型
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.core import Dense
# 数据集
(X_train, y_train), (X_test, y_test) = mnist.load_data() # 读取并划分MNIST训练集、测试集
X_train = X_train.reshape(len(X_train), -1) # 二维变一维
X_test = X_test.reshape(len(X_test), -1)
X_train = X_train.astype('float32') # 转为float类型
X_test = X_test.astype('float32')
X_train = (X_train - 127) / 127 # 灰度像素数据归一化
X_test = (X_test - 127) / 127
y_train = np_utils.to_categorical(y_train, num_classes=10) # 独热编码。如原来为5,转换后[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
y_test = np_utils.to_categorical(y_test, num_classes=10)
# 定义模型
model = Sequential() # Keras序列模型
model.add(Dense(20, input_shape=(784,), activation='relu')) # 添加全连接层(隐藏层),隐藏层数20层,激活函数为ReLU
model.add(Dense(10, activation='sigmoid')) # 添加输出层,结果10类,激活函数为Sigmoid
print(model.summary()) # 模型基本信息
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) # 编译模型
# 训练
model.fit(X_train, y_train, epochs=20, batch_size=64, verbose=1, validation_split=0.05) # 迭代20次
# 评估
loss, accuracy = model.evaluate(X_test, y_test)
print('Test loss:', loss)
print('Accuracy:', accuracy)
# 保存
model.save('mnistmodel.h5')
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 20) 15700
_________________________________________________________________
dense_2 (Dense) (None, 10) 210
=================================================================
Total params: 15,910
Trainable params: 15,910
Non-trainable params: 0
_________________________________________________________________
Test loss: 0.2107365175232291
Accuracy: 0.938
可以看到保存了一个.h5文件

二、预测
import random
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.models import load_model
# 数据集
(_, _), (X_test, y_test) = mnist.load_data() # 划分MNIST训练集、测试集
# 随机数
index = random.randint(0, X_test.shape[0])
x = X_test[index]
y = y_test[index]
# 显示该数字
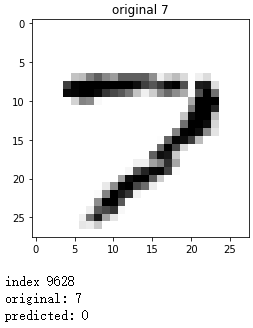
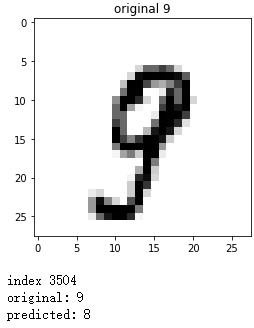
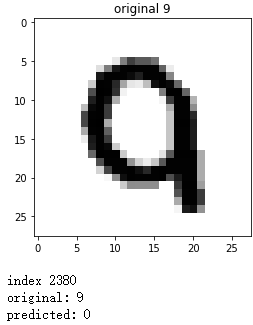
plt.imshow(x, cmap='gray_r')
plt.title("original {}".format(y))
plt.show()
# 加载
mymodel = load_model('mnistmodel.h5')
# 预测
x.shape = (1,784)#变成[[]]
# x = x.flatten()[None] # 也可以用这个
predict = mymodel.predict(x)
predict = np.argmax(predict)#取最大值的位置
print('index:', index)
print('original:', y)
print('predicted:', predict)

index 8991
original: 0
predicted: 0
三、参考文献
- Numpy 改变数组维度的几种方法 - m0_37586991的博客 - CSDN博客 https://blog.csdn.net/m0_37586991/article/details/79758168
- Keras-2 Keras Mnist - 记录学习的过程 - CSDN博客 https://blog.csdn.net/weiwei9363/article/details/78570390
四、IPython
import random
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.models import load_model
# 数据集
(_, _), (X_test, y_test) = mnist.load_data() # 划分MNIST训练集、测试集
# 加载模型
mymodel = load_model('mnistmodel.h5')
# 随机数
index = random.randint(0, X_test.shape[0])
x = X_test[index]
y = y_test[index]
# 显示该数字
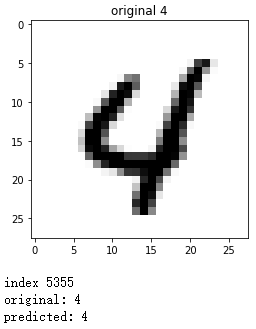
plt.imshow(x, cmap='gray_r')
plt.title("original {}".format(y))
plt.show()
# 预测
x.shape = (1,784)#变成[[]]
predict = mymodel.predict(x)
predict = np.argmax(predict)#取最大值的位置
print('index', index)
print('original:', y)
print('predicted:', predict)
正确预测:
错误预测: