Numpy基本操作:


1 # Author:K 2 import numpy as np 3 t = np.random.randint(1, 20, (5, 6)).astype(float) 4 print(t) 5 print('='*30) 6 7 # 取行 8 print(t[1]) 9 print('='*30) 10 11 # 取多行 12 print(t[1:3]) 13 print('='*30) 14 15 # 取列 16 print(t[:, 1]) 17 print('='*30) 18 19 # 取多列 20 print(t[:, 1:3]) 21 print('='*30) 22 23 # 按给定范围取多行多列 24 print(t[1:3, 2:4]) 25 print('='*30) 26 27 # 行交换 28 print(t) 29 print('*'*100) 30 t[[1, 3], :] = t[[3, 1], :] 31 print(t) 32 33 # 取多个值组成数组 34 print(t[[1, 2], [3, 4]]) # 取t[1, 3] t[2, 4] 组成数组 35 print(t[1, 3], t[2, 4]) 36 print('='*30) 37 38 # 按列求平均值,得出来的数组的个数与原来数组列数一致 39 t1 = np.average(t, axis=0) 40 print(t1) 41 print('='*30) 42 43 # 按行求平均值,得出来的数组的个数与原来数组行数一致 44 t2 = np.average(t, axis=1) 45 print(t2) 46 print('='*30) 47 48 # 将t中大于10的数赋值为nan 49 t[t > 10] = np.nan 50 print(t) 51 print('='*30) 52 53 # 三元运算符 54 t = np.where(t > 5, 10, 0) # 将t中大于5的数替换成10,其余的替换成0 55 print(t) 56 print('='*30) 57 58 # 布尔索引 59 t[t > 0] = 5 60 print(t) 61 print('='*30) 62 63 # 裁剪 64 t = t.clip(2, 4) # 将小于2的替换成2,大于4的替换成4,若不在这区间内,则不变 65 print(t) 66 print('='*30) 67 68 # 转置,三种调用方式都行 69 print(t.T) 70 print(t.transpose()) 71 print(t.swapaxes(0, 1)) 72 print('='*30) 73 74 75 def modify_nan(array_demo): 76 """ 77 将数组中为nan的值赋值为某一列的均值 78 :param array_demo: 传入一个包含nan值的数组 79 :return: 返回一个不包含nan值的数组,其中nan的值被替换成均值 80 """ 81 for i in range(array_demo.shape[1]): # 按列数遍历数组 82 # 获取临时列 83 temp_col = array_demo[:, i] # 浅拷贝,temp_col修改的话,对应的array_demo也会改 84 # 判断这一列中有没有nan值 85 if np.count_nonzero(temp_col != temp_col) != 0: # 统计数组非0的个数,若不等于0,说明有nan 86 # 取出不为nan的值 87 temp_not_nan_col = temp_col[temp_col == temp_col] 88 # 求当前不为nan的值的均值 89 mean_num = temp_not_nan_col.mean() 90 # 选中当前列为nan的位置,将均值赋给nan 91 temp_col[np.isnan(temp_col)] = mean_num 92 return array_demo 93 94 95 t = modify_nan(t) 96 print(t) 97 print('='*30)
用散点图绘制喜欢数和评论数的关系:
1 # Author:K 2 """ 3 用散点图绘制英国的喜欢数和评论数的关系 4 """ 5 import numpy as np 6 from matplotlib import pyplot as plt 7 8 plt.rcParams['font.sans-serif'] = ['SimHei'] 9 10 uk_data_path = r'E:\PythonProjects\data analysis\DataAnalysis-master\day03\code\youtube_video_data\GB_video_data_numbers.csv' 11 12 uk_data = np.loadtxt(uk_data_path, delimiter=',', dtype=int) # 设置dtype参数,让数据不以科学计数法输出;参数unpack若为True,则转置,默认为False 13 14 # 去除喜欢数大于150000的数据 15 uk_data = uk_data[uk_data[:, 1] <= 150000] 16 # 去除评论数大于20000的数据 17 uk_data = uk_data[uk_data[:, -1] < 20000] 18 19 uk_comments = uk_data[:, -1] # 评论数 20 uk_likes = uk_data[:, 1] # 喜欢数 21 22 # 绘制散点图 23 plt.figure(figsize=(20, 8), dpi=80) 24 plt.scatter(uk_likes, uk_comments) 25 26 # 设置x,y轴坐标 27 plt.xlabel('喜欢数', size=15) 28 plt.ylabel('评论数', size=15) 29 plt.title('喜欢数和评论数的关系', size=17) 30 31 # 保存图形 32 plt.savefig('./loadtxt_scatter.png') 33 plt.show()
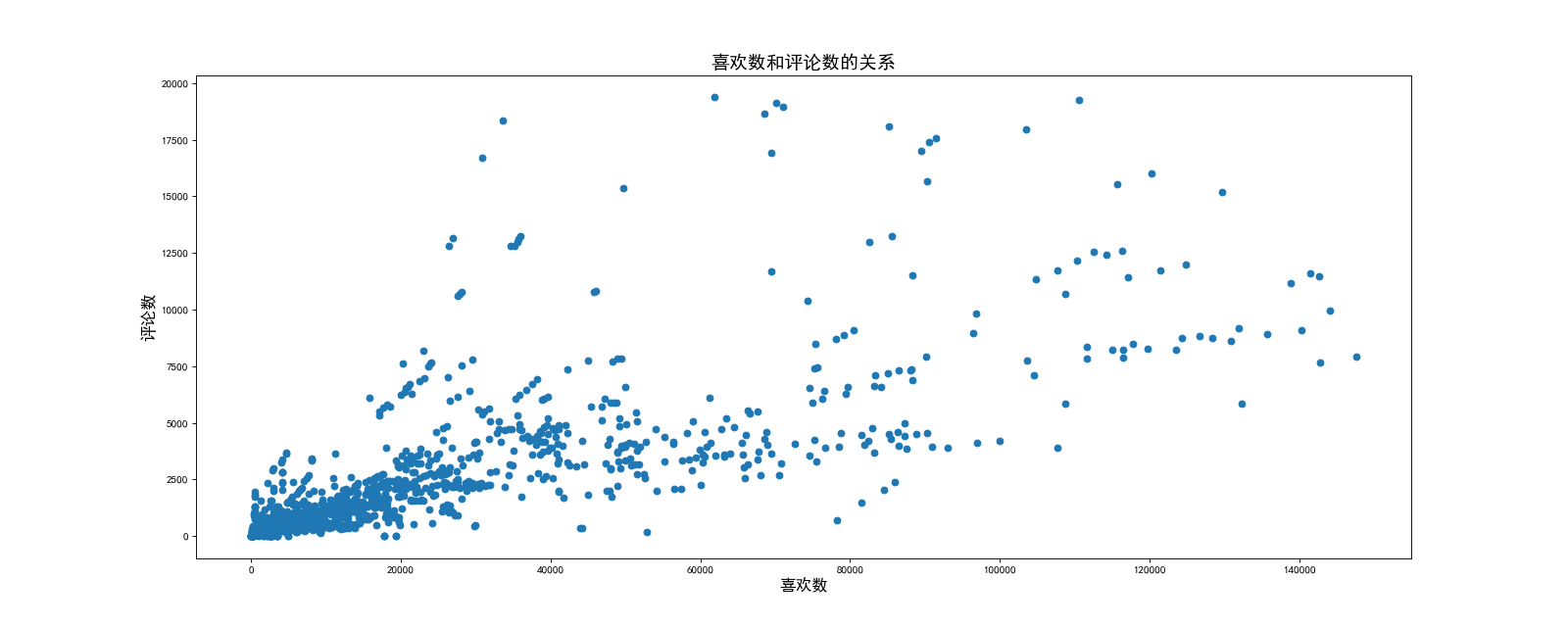
为美国评论数绘制直方图:
1 # Author:K 2 """ 3 为美国评论数绘制直方图 4 """ 5 6 import numpy as np 7 from matplotlib import pyplot as plt 8 9 # 解决中文显示问题 10 plt.rcParams['font.sans-serif'] = ['SimHei'] 11 12 us_data_path = r'E:\PythonProjects\data analysis\DataAnalysis-master\day03\code\youtube_video_data\US_video_data_numbers.csv' 13 14 us_data = np.loadtxt(us_data_path, delimiter=',', dtype=int) # 设置dtype参数,让数据不以科学计数法输出;参数unpack若为True,则转置,默认为False 15 16 us_comments = us_data[:, -1] # 取出评论数 17 # 去掉大于50000的数 18 us_comments = us_comments[us_comments <= 5000] 19 20 # 绘制直方图 21 plt.figure(figsize=(20, 8), dpi=80) 22 d = 50 23 bins = (us_comments.max() - us_comments.min()) // d 24 plt.hist(us_comments, bins) 25 26 # 设置x,y轴坐标 27 plt.xlabel('评论数', size=15) 28 plt.title('评论数分布', size=17) 29 30 # 保存图形 31 plt.savefig('./loadtxt_hist.png') 32 33 plt.show()
数组拼接实例
扫描二维码关注公众号,回复:
7953713 查看本文章

1 # Author:K 2 """ 3 现在希望把之前案例中两个国家的数据方法一起来研究分析, 4 同时保留国家的信息(每条数据的国家来源),应该怎么办 5 """ 6 7 import numpy as np 8 9 us_data_path = r'E:\PythonProjects\data analysis\DataAnalysis-master\day03\code\youtube_video_data\US_video_data_numbers.csv' 10 uk_data_path = r'E:\PythonProjects\data analysis\DataAnalysis-master\day03\code\youtube_video_data\GB_video_data_numbers.csv' 11 12 us_data = np.loadtxt(us_data_path, delimiter=',', dtype=int) 13 uk_data = np.loadtxt(uk_data_path, delimiter=',', dtype=int) 14 15 # 对us_data添加最后一列,全为0 16 us_data = np.hstack((us_data, np.zeros((us_data.shape[0], 1)))).astype(int) 17 # 对uk_data添加最后一列,全为1 18 uk_data = np.hstack((uk_data, np.ones((uk_data.shape[0], 1)))).astype(int) 19 20 # 拼接us_data 和 uk_data 21 data = np.vstack((us_data, uk_data)) 22 23 print(us_data) 24 print('*'*100) 25 print(uk_data) 26 print('*'*100) 27 print(data)