1.对json数组和json对象的操作
在python中,一个 Json 对象里面包含了很多信息,那么如何从这些数据中拿到我们想要的呢?
在之前的
python对象与json格式的数据类型转化
一文中已经说明如何操作一个json对象,本文是再补充一个常见的还有处理 Json 数组 的。
python 的 json 模块有两个主要的函数。
1.python 对象转化为 json格式:
json.dumps()
2.将json数据转化为python对象:
json.loads()
就是:
1 import json 2 Json.dumps() # 将字典或列表转为josn格式的字符串 3 Json.loads() # 将json格式字符串转化为python对象 4 Json.dump() # 将字典或列表转为json字符串并且写入到文件中 5 Json.load() # 从文件中读取json格式字符串转化为python对象
总之记住:
(带s的都是对string操作,不带s就是对txt之类的文件操作。)
再不明白的,具例子:
源码:
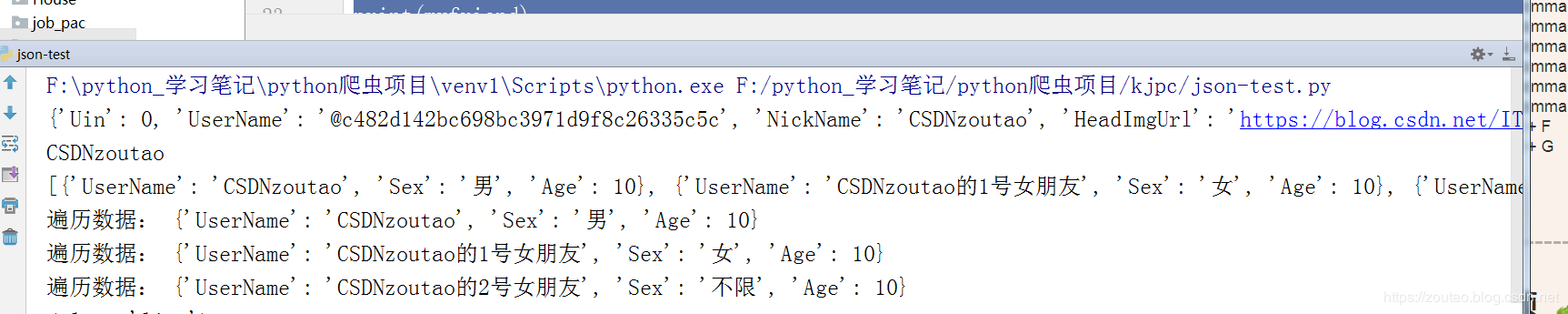
1 """ 2 一、第一部分为: Json格式与python对象的相互转换 3 """ 4 5 import json 6 7 # 普通的json单列表 8 jsondata = ''' 9 { 10 "Uin":0, 11 "UserName":"@c482d142bc698bc3971d9f8c26335c5c", 12 "NickName":"CSDNzoutao", 13 "HeadImgUrl":"https://blog.csdn.net/ITBigGod", 14 "DisplayName":"ZouTao", 15 "ChatRoomId":0, 16 "KeyWord":"che", 17 "EncryChatRoomId":"", 18 "IsOwner":0 19 } 20 ''' 21 22 myfriend = json.loads(jsondata) # json转化字典对象 23 print(myfriend) 24 # 转为字典以后,就可以根据key来获取各种字段数值了 25 name = myfriend.get('NickName') 26 print(name) 27 # json.dumps(name) #将python对象转化为json 28 29 # 常见的还有 Json 数组-嵌套型 30 Json_doc=''' 31 { 32 "MemberList": [{ 33 "UserName": "CSDNzoutao", 34 "Sex": "男", 35 "Age":10 36 }, 37 { 38 "UserName": "CSDNzoutao的1号女朋友", 39 "Sex": "女", 40 "Age":10 41 }, 42 { 43 "UserName": "CSDNzoutao的2号女朋友", 44 "Sex": "不限", 45 "Age":10 46 }] 47 } 48 ''' 49 50 myfriends = json.loads(Json_doc) 51 memberList = myfriends.get('MemberList') # 得到list对象-包含字典数据 52 print(memberList) 53 54 # 用个 for 循环就能轻而易举的获取数据 55 for x in memberList: 56 print('遍历list数据:',x)
图示:
2.python读写各类txt,csv,html,xls文件的工具类
以上面的那个json格式字符串和python对象为输入数据memberList。
python读写各类txt,csv,html,xls文件的方式:
源码:
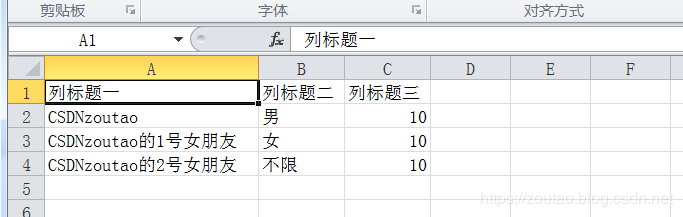
1 ''' 2 二、第二部分为: python读写各类txt,csv,html,xls文件的方式 3 ''' 4 5 # 保存为txt文件 6 def output_txt(result): 7 print('数据类型为:',type(result)) # <class 'dict'> 8 with open('result.txt','a',encoding='utf-8') as f: 9 f.write(json.dumps(result,ensure_ascii=False)+'\n') # 将字典或列表转为josn格式的字符串 10 11 # 读取txt文件 12 with open("result.txt", "r", "utf-8") as f: 13 # 为a+模式时,因为为追加模式,指针已经移到文尾,读出来的是一个空字符串。 14 ftext = f.read() # 一次性读全部成一个字符串 15 ftextlist = f.readlines() # 一次性读全部,但每一行作为一个子句存入一个列表 16 fline = f.readline() # 或者只读取1行 17 print(ftextlist,fline) 18 f.close() # 关闭文件 19 ## 总结:以后读写文件都使用with open语句,不要再像以前那样用f = open()这种语句了! 20 21 22 # 保存为html文件 23 def output_html(memberList): 24 print(type(memberList)) # <class 'list'> 25 fout = open('result.html', 'w', encoding='utf-8') 26 fout.write('<html>') 27 fout.write('<meta charset=utf-8') 28 fout.write('<body>') 29 fout.write('<table>') 30 31 # Python 默认编码格式是: Ascii 32 for data in memberList: # result=list,data={} 33 fout.write('<tr>') 34 fout.write('<hr>') 35 fout.write('<td>%s</td>' % data['UserName']) 36 fout.write('<td>%s</td>' % data['Sex']) 37 fout.write('<hr>') 38 fout.write('</tr>') 39 fout.write('</table>') 40 fout.write('</body>') 41 fout.write('</html>') 42 fout.close() 43 44 # 保存为csv文件 45 def output_csv(datalist): 46 print(type(datalist)) # <class 'list'> 47 import csv 48 # 准备好存储数据的csv文件 49 csv_file = open("result.csv", 'w', newline='', encoding='utf-8-sig') # 解决中文乱码问题 50 writer = csv.writer(csv_file) 51 writer.writerow(['列标题一', '列标题二', '列标题三']) 52 for data in datalist: 53 writer.writerow([data['UserName'], data['Sex'],data['Age']]) 54 csv_file.close() 55 56 #用reder读取csv文件 57 with open('result.csv','r') as csvFile: 58 reader = csv.reader(csvFile) 59 for line in reader: 60 print(line) 61 62 # 保存为xls文件 63 def output_xls(datalist): 64 print(type(datalist)) # <class 'list'> 65 import xlwt 66 # #创建工作簿 67 workbook = xlwt.Workbook(encoding='utf-8') 68 # 创建sheet 69 sheet = workbook.add_sheet(u'sheet1',cell_overwrite_ok=True) 70 head = ['名字', '性别', '年龄'] # 定义表头 71 # worksheet.write()函数写入第一行列名,参数分别表示行、列、数据、数据格式。 72 for h in range(len(head)): 73 sheet.write(0, h, head[h]) # 生成第0行标题 74 75 # 填入数据(第1行0列开始填数) 76 row = 1 77 for product in datalist: # 列表里面存了字典 78 sheet.write(row , 0, product['UserName']) 79 sheet.write(row , 1, product['Sex']) 80 sheet.write(row , 2, product['Age']) 81 row += 1 82 workbook.save('result.xls') 83 84 # 读取excel数据 85 import xlrd 86 data = xlrd.open_workbook('result.xls') # 打开xls文件 87 table = data.sheets()[0] # 打开第一张表 88 nrows = table.nrows # 获取表的行数 89 for i in range(nrows): # 循环逐行打印 90 if i == 0: # 跳过第一行 91 continue 92 print(table.row_values(i)) 93 94 95 # 示例调用 96 if __name__ == '__main__': 97 98 # memberList是一个列表,里面嵌入字典 99 output_html(memberList) 100 output_csv(memberList) 101 output_xls(memberList) 102 103 for result in memberList: 104 #print('筛选后的最终数据为:',result) 105 output_txt(result) # 生成器对象一遍历出来就是字典。
生成的各类文件数据:

提醒!!! 以后在读写txt文件时,都使用with open语句,不要再像以前那样用f = open()这种语句了!