python文件读写:
读文件:
文件内容如右图:

file.read()方法返回的是整个文件的内容,type是str类型
file.readline()方法返回的是文件一行的内容(首行),type也是str类型
file.readlines()返回的是list类型, 并且文件的每一行是list中元素,每行最后都有一个'\n'换行符。list类型可遍历(Iterator)
逐行读取 for line in file: 返回的line是字符串类型,file 来自 with open(filename ) as file 这里的file
filename = 'C:\\users\\CaptainT\\Desktop\\word.txt'
with open(filename) as ff:
contents = ff.read()
# .rstrip() 删除字符串尾部的空白, 包括空格和换行,rstrip 是剥去,去除的意思
print(contents.rstrip())输出如右图

注意:下面的形式与上面的写法等价。但是with open( )会在操作完成之后自动close文件,免得下面这种方式每次都是手动close。
filename = 'C:\\users\\CaptainT\\Desktop\\word.txt'
file = open(filename)
contents = file.read()
print(contents.rstrip())
file.close()写文件:
file.write(str) 写一行。
file.writelines(list) 写多行,list中元素的需要时str,否则报错。并且每写一个元素需要换行的话,需要添加换行符。
ss = "I love python"
ask = 'And what about you?'
pardon = 'You must be also love Python.^_^'
filename = 'C:\\users\\CaptainT\\Desktop\\word.txt'
with open(filename, "w") as fo: # 'w'覆盖写
fo.write(ss + '\n')
with open(filename, "a") as fo: # 'a'追加写,只能写文件
fo.write(ask + '\n')
with open(filename, "a+") as fo: # 'a+'追加读写的方式打开文件,即这种方式也可以读文件
fo.write(pardon + '\n')此时文件内容为:

CSV模块:
持续更新....
pandas文件操作:
read_csv: 从文件,URL,文件型对象中加载带分隔符的数据。默认分割符为逗号
read_table:从文件,URL,文件型对象中加载带分隔符的数据。默认分隔符为制表符("\t")
源文件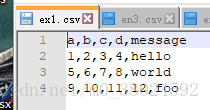
import pandas as pd
df = pd.read_csv('C:\\Users\\CaptainT\\Desktop\\ex1.csv')
df| a | b | c | d | message | |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 5 | 6 | 7 | 8 | world |
| 2 | 9 | 10 | 11 | 12 | foo |
#也可以用read_table,但是需要制定分隔符为逗号
df2 = pd.read_table('C:\\Users\\CaptainT\\Desktop\\ex1.csv', sep=',') # 指定分隔符
df2| a | b | c | d | message | |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | hello |
| 1 | 5 | 6 | 7 | 8 | world |
| 2 | 9 | 10 | 11 | 12 | foo |
若文件没有标题行(表头),读入方法有两个:1)让pandas分配默认列名,2)自己定义列名。内容如图

pd.read_csv("C:\\Users\\CaptainT\\Desktop\\en4.csv", header=None)| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1 | jin | yuz |
| 1 | 2 | meng | wei |
| 2 | 3 | dong | yanl |
| 3 | 4 | sun | lu |
| 4 | 5 | deng | xingw |
pd.read_csv("C:\\Users\\CaptainT\\Desktop\\en4.csv", names=['id', 'first_name', 'name'])| id | first_name | name | |
|---|---|---|---|
| 0 | 1 | jin | yuz |
| 1 | 2 | meng | wei |
| 2 | 3 | dong | yanl |
| 3 | 4 | sun | lu |
| 4 | 5 | deng | xingw |
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
我们可以使用 list() 转换来输出列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
zip([iterable, ...]) # 一个或多个迭代器([iterable, ...]) # 一个或多个迭代器a = [1,2,3]
b = [4,5,6]
c = [4,5,6,7,8]
zipped =zip(a,b) # 打包为元组的列表 ,zipped为可迭代的对象
print([_ for _ in zipped]) # [(1, 4), (2, 5), (3, 6)]
print(list(zip(a,b))) # [(1, 4), (2, 5), (3, 6)]
zip(a,c) # 元素个数与最短的列表一致
print([_ for _ in zip(a,c)]) # [(1, 4), (2, 5), (3, 6)]
print(list(zip(a,c))) # [(1, 4), (2, 5), (3, 6)]
ss1, ss2 = zip(*zip(a,b)) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
print(tuple(ss1)) # (1, 2, 3)
print(list(ss2)) # [4, 5, 6]操作json文件 -- 注意中文的编码问题
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于ECMAScript的一个子集。 JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C、C++、Java、JavaScript、Perl、Python等)。这些特性使JSON成为理想的数据交换语言。易于人阅读和编写,同时也易于机器解析和生成(一般用于提升网络传输速率)。
JSON在python中分别由list和dict组成。
json 和 pickle -- 用于序列化的两个模块:
- json: 用于字符串和python数据类型间进行转换
- pickle: 用于python特有的类型和python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
json dumps把数据类型转换成字符串 dump把数据类型转换成字符串并存储在文件中 loads把字符串转换成数据类型 load把文件打开从字符串转换成数据类型
json是可以在不同语言之间交换数据的,而pickle只在python之间使用。json只能序列化最基本的数据类型,josn只能把常用的数据类型序列化(列表、字典、列表、字符串、数字、),比如日期格式、类对象!josn就不行了。而pickle可以序列化所有的数据类型,包括类,函数都可以序列化。
事例:
dumps:将python中的 字典 转换为 字符串
import json
test_dict = {'希尔排序': {'实体描述': 'null', '实体概念': [], '实体关系': []}}
print(test_dict)
print(type(test_dict))
# dumps 将数据转换成字符串
# 加上ensure_ascii=False是防止显示的不是中文,而是中文编码
json_str = json.dumps(test_dict, ensure_ascii=False)
print(json_str)
print(type(json_str))返回结果如下:
{'希尔排序': {'实体描述': 'null', '实体概念': [], '实体关系': []}}
<class 'dict'>
{'希尔排序': {'实体描述': 'null', '实体概念': [], '实体关系': []}}
<class 'str'>
loads: 将 字符串 转换为 字典
new_dict = json.loads(json_str)
print(new_dict)
print(type(new_dict))
#返回结果如下:
# {'希尔排序': {'实体描述': 'null', '实体概念': [], '实体关系': []}}
# <class 'dict'>dump: 将 python字典(dict)类型 写入json文件中
with open('E:\\EduKG\\test.json', 'w', encoding='UTF-8') as f:
json.dump(new_dict, f, ensure_ascii=False) # 同理,此处是避免编码问题
print('Writing done...')结果如下:


load: 读取文件内容,并转换成 dict类型
with open('E:\\EduKG\\test.json', 'r', encoding='UTF-8') as f:
load_dict = json.load(f)
print(load_dict)
print(type(load_dict))
xlrd模块 -- python操作Excel
excel原内容:
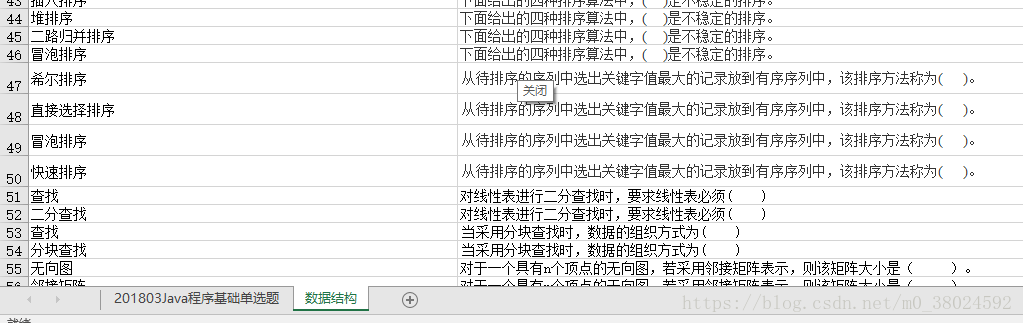
import xlrd
import json
def handle():
data_dict = {}
file = 'E:\\课程知识图谱\\知识图谱测试题.xls'
data = xlrd.open_workbook(file) # 打开xls文件
table = data.sheets()[1] # 打开第二张表
rows = table.nrows # 获取表的行数
line = table.ncols # 获取表的列数 -- column
table_list = data.sheet_names() # 返回所有的sheet表单的名字, list形式
sheet2 = data.sheet_by_name('数据结构') # 此处的sheet2和上面第7行的table是同一个表单
sheet3 = data.sheet_by_index(1) # sheet2 sheet3 和 table 均是同一个表单
print(sheet2.row_values(0)) # 返回第一行的内容
print(sheet3.col_values(0)) # 返回第一列的内容
print(table_list)
print(line)
print(rows)
for i in range(rows):
mid = table.row_values(i)
for j in range(len(mid)):
mid[j] = mid[j].strip()
if mid[0] not in data_dict.keys():
data_dict[mid[0]] = [] # 字典的value是个list,下面往list里面添加内容用append
data_dict[mid[0]].append(mid[1:4])
else:
data_dict[mid[0]].append(mid[1:4])
# print('<br>'.join(mid[1:]))
# print(mid[1:4])
# for k, v in data_dict.items():
# print(k, v)
# print(len(data_dict))
with open('E:\\EduKG\\exercise.json', 'w', encoding='UTF-8') as f: # 写成json文件
json.dump(data_dict, f, ensure_ascii=False)
print('Write done...')
if __name__ == '__main__':
print('...')
handle()