(1)QuickSort
快速排序是图灵奖得主 C. R. A. Hoare 于 1960 年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
分治法的基本思想是:将原问题分解为若干个规模更小但结构与原问题相似的子问题。递归地解这些子问题,然后将这些子问题的解组合为原问题的解。
利用分治法可将快速排序的分为三步:
- 在数据集之中,选择一个元素作为”基准”(pivot)。
- 所有小于”基准”的元素,都移到”基准”的左边;所有大于”基准”的元素,都移到”基准”的右边。这个操作称为分区 (partition) 操作,分区操作结束后,基准元素所处的位置就是最终排序后它的位置。
- 对”基准”左边和右边的两个子集,不断重复第一步和第二步,直到所有子集只剩下一个元素为止。
- 分区是快速排序的主要内容,用伪代码可以表示如下:
|
1
2
3
4
5
6
7
8
9
10
|
function partition(a, left, right, pivotIndex)
pivotValue := a[pivotIndex]
swap(a[pivotIndex], a[right]) // 把 pivot 移到結尾
storeIndex := left
for i from left to right-1
if a[i] < pivotValue
swap(a[storeIndex], a[i])
storeIndex := storeIndex + 1
swap(a[right], a[storeIndex]) // 把 pivot 移到它最後的地方
return storeIndex // 返回 pivot 的最终位置
|
首先,把基准元素移到結尾(如果直接选择最后一个元素为基准元素,那就不用移动),然后从左到右(除了最后的基准元素),循环移动小于等于基准元素的元素到数组的开头,每次移动 storeIndex 自增 1,表示下一个小于基准元素将要移动到的位置。循环结束后 storeIndex 所代表的的位置就是基准元素的所有摆放的位置。所以最后将基准元素所在位置(这里是 right)与 storeIndex 所代表的的位置的元素交换位置。要注意的是,一个元素在到达它的最后位置前,可能会被交换很多次。
一旦我们有了这个分区算法,要写快速排列本身就很容易:
|
1
2
3
4
5
6
|
procedure quicksort(a, left, right)
if right > left
select a pivot value a[pivotIndex]
pivotNewIndex := partition(a, left, right, pivotIndex)
quicksort(a, left, pivotNewIndex
-1)
quicksort(a, pivotNewIndex+
1, right)
|
实例分析
举例来说,现有数组 arr = [3,7,8,5,2,1,9,5,4],分区可以分解成以下步骤:
首先选定一个基准元素,这里我们元素 5 为基准元素(基准元素可以任意选择):
|
1
2
3
|
pivot
↓
3 7 8 5 2 1 9 5 4
|
将基准元素与数组中最后一个元素交换位置,如果选择最后一个元素为基准元素可以省略该步:
|
1
2
3
|
pivot
↓
3 7 8 4 2 1 9 5 5
|
-
从左到右(除了最后的基准元素),循环移动小于基准元素 5 的所有元素到数组开头,留下大于等于基准元素的元素接在后面。在这个过程它也为基准元素找寻最后摆放的位置。循环流程如下:
循环 i == 0 时,storeIndex == 0,找到一个小于基准元素的元素 3,那么将其与 storeIndex 所在位置的元素交换位置,这里是 3 自身,交换后将 storeIndex 自增 1,storeIndex == 1:
12345pivot↓3 7 8 4 2 1 9 5 5↑storeIndex循环 i == 3 时,storeIndex == 1,找到一个小于基准元素的元素 4:
12345┌───────┐ pivot↓ ↓ ↓3 7 8 4 2 1 9 5 5↑ ↑storeIndex i交换位置后,storeIndex 自增 1,storeIndex == 2:
12345pivot↓3 4 8 7 2 1 9 5 5↑storeIndex循环 i == 4 时,storeIndex == 2,找到一个小于基准元素的元素 2:
12345┌───────┐ pivot↓ ↓ ↓3 4 8 7 2 1 9 5 5↑ ↑storeIndex i交换位置后,storeIndex 自增 1,storeIndex == 3:
12345pivot↓3 4 2 7 8 1 9 5 5↑storeIndex循环 i == 5 时,storeIndex == 3,找到一个小于基准元素的元素 1:
12345┌───────┐ pivot↓ ↓ ↓3 4 2 7 8 1 9 5 5↑ ↑storeIndex i交换后位置后,storeIndex 自增 1,storeIndex == 4:
12345pivot↓3 4 2 1 8 7 9 5 5↑storeIndex循环 i == 7 时,storeIndex == 4,找到一个小于等于基准元素的元素 5:
12345┌───────────┐ pivot↓ ↓ ↓3 4 2 1 8 7 9 5 5↑ ↑storeIndex i交换后位置后,storeIndex 自增 1,storeIndex == 5:
12345pivot↓3 4 2 1 5 7 9 8 5↑storeIndex -
循环结束后交换基准元素和 storeIndex 位置的元素的位置:
|
1
2
3
4
5
|
pivot
↓
3 4 2 1 5 5 9 8 7
↑
storeIndex
|
那么 storeIndex 的值就是基准元素的最终位置,这样整个分区过程就完成了。
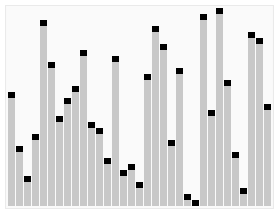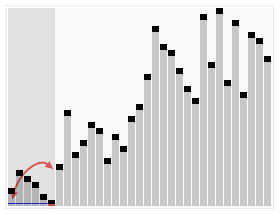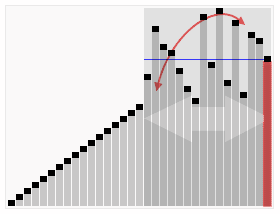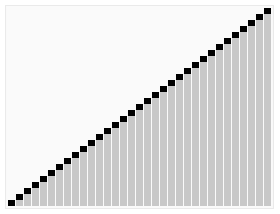
引用维基百科上的一张图片:

实现代码:
#include<stdio.h> #include<string.h> #include<algorithm> using namespace std; int Compare(const void *a,const void *b) { return *(int*)a-*(int*)b; } int main() { int array[100],i,n; while(scanf("%d",&n)!=EOF) { for(i=0;i<n;i++) scanf("%d",&array[i]); qsort(array,n,sizeof(int),Compare); for(i=0;i<n;i++) printf("%d ",array[i]); printf("\n"); } }
(2)MergeSort
归并排序(Merge Sort)与快速排序思想类似:将待排序数据分成两部分,继续将两个子部分进行递归的归并排序;然后将已经有序的两个子部分进行合并,最终完成排序。其时间复杂度与快速排序均为O(nlogn),但是归并排序除了递归调用间接使用了辅助空间栈,还需要额外的O(n)空间进行临时存储。从此角度归并排序略逊于快速排序,但是归并排序是一种稳定的排序算法,快速排序则不然。
首先考虑下如何将将二个有序数列合并。这个非常简单,只要从比较二个数列的第一个数,谁小就先取谁,取了后就在对应数列中删除这个数。然后再进行比较,如果有数列为空,那直接将另一个数列的数据依次取出即可。
//将有序数组a[]和b[]合并到c[]中 void MemeryArray(int a[], int n, int b[], int m, int c[]) { int i, j, k; i = j = k = 0; while (i < n && j < m) { if (a[i] < b[j]) c[k++] = a[i++]; else c[k++] = b[j++]; } while (i < n) c[k++] = a[i++]; while (j < m) c[k++] = b[j++]; }
可以看出合并有序数列的效率是比较高的,可以达到O(n)。
解决了上面的合并有序数列问题,再来看归并排序,其的基本思路就是将数组分成二组A,B,如果这二组组内的数据都是有序的,那么就可以很方便的将这二组数据进行排序。如何让这二组组内数据有序了?
可以将A,B组各自再分成二组。依次类推,当分出来的小组只有一个数据时,可以认为这个小组组内已经达到了有序,然后再合并相邻的二个小组就可以了。这样通过先递归的分解数列,再合并数列就完成了归并排序。
//将有二个有序数列a[first...mid]和a[mid...last]合并。 void mergearray(int a[], int first, int mid, int last, int temp[]) { int i = first, j = mid + 1; int m = mid, n = last; int k = 0; while (i <= m && j <= n) { if (a[i] <= a[j]) temp[k++] = a[i++]; else temp[k++] = a[j++]; } while (i <= m) temp[k++] = a[i++]; while (j <= n) temp[k++] = a[j++]; for (i = 0; i < k; i++) a[first + i] = temp[i]; } void mergesort(int a[], int first, int last, int temp[]) { if (first < last) { int mid = (first + last) / 2; mergesort(a, first, mid, temp); //左边有序 mergesort(a, mid + 1, last, temp); //右边有序 mergearray(a, first, mid, last, temp); //再将二个有序数列合并 } } bool MergeSort(int a[], int n) { int *p = new int[n]; if (p == NULL) return false; mergesort(a, 0, n - 1, p); delete[] p; return true; }
归并排序的效率是比较高的,设数列长为N,将数列分开成小数列一共要logN步,每步都是一个合并有序数列的过程,时间复杂度可以记为O(N),故一共为O(N*logN)。因为归并排序每次都是在相邻的数据中进行操作,所以归并排序在O(N*logN)的几种排序方法(快速排序,归并排序,希尔排序,堆排序)也是效率比较高的。
(3)Insertion Sort
它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
代码实现:
#include <iostream> #include <vector> using namespace std; template <typename T> void InsertionSort( vector<T> &nums){ for( int i = 1; i < nums.size(); i++ ){ T temp = nums[i]; int j; for( j = i-1; j >= 0 && nums[j] > temp; j-- ){ nums[j+1] = nums[j]; //对应3 } nums[j+1] = temp; //4.5 } } int main(){ vector<int> nums{11,5,29,1,34,4,12,24,40,5,35,17}; cout<<" Before Sort:" ; for( auto m: nums){ cout << m <<" "; } cout<<endl; InsertionSort( nums ); cout<< " After Sort:"; for( auto m: nums){ cout << m <<" "; } cout<<endl; }
特点:
1.插入排序是一种稳定的排序
2.对于最好的情况,即原数据是已排序的,则插入排序一共只需要进行n-1次的比较操作
3.对于最坏的情况,即数据是降序的,在这种情况下,一共需要进行1+2+3....(n-1)即n(n-1)/2次比较操作和n(n-1)/2 + (n-1)次赋值操作,所以总的时间复杂度是O(n2)
4.在C++的STL中,插入排序作为快排的补充,用于少量元素的排序,通常为8个或以下。