文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 沂水寒城
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
在机器学习、数据挖掘领域里面,接触到数据处理分析的人来说,数据探索是非常重要的一部分工作,而数据可视化会成为数据分析工程师完成数据探索工作的有力工具。本文主要是介绍一款我日常使用较多的可视化利器Yellowbrick,这是一款基于sklearn+matplotlib模块构建的更加高级的可视化工具,能够更加方便地完成很多数据探索、分词与展示工作。
学习使用一个模块最好的方式就是学习它提供的API,下面先给出来几个比较好的参考地址:
1)官方文档地址(英文)
https://www.scikit-yb.org/en/latest/
2)官方文档地址(中文)
http://www.scikit-yb.org/zh/latest/
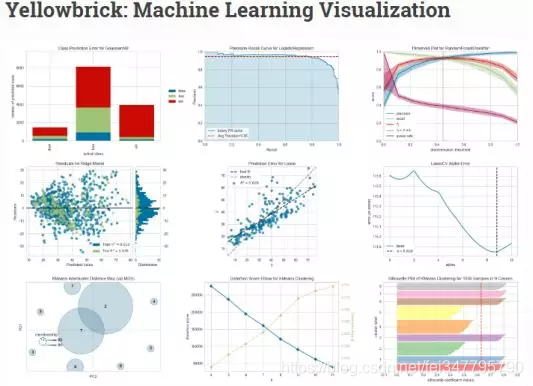
Yellowbrick是由一套被称为"Visualizers"组成的可视化诊断工具组成的集合,其由Scikit-Learn API延伸而来,对模型选择过程其指导作用。总之,Yellowbrick结合了Scikit-Learn和Matplotlib并且最好得传承了Scikit-Learn文档,对你的模型进行可视化!

想要了解Yellowbrick就必须先了解Visualizers,它是estimators从数据中学习得的对象,其主要任务是产生可对模型选择过程有更深入了解的视图。从Scikit-Learn来看,当可视化数据空间或者封装一个模型estimator时,其和转换器(transformers)相似,就像"ModelCV" (比如RidgeCV,LassoCV)的工作原理一样。Yellowbrick的主要目标是创建一个和Scikit-Learn类似的有意义的API。
Yellowbrick中最受欢迎的visualizers包括:

如此强大的可视化工具,安装方式却很简单,使用下面的命令:
pip install yellowbrick
如果需要升级最新版本的则可以使用下面的命令:
pip install –u yellowbrick
安装完成后,我们就可以进行使用了。该模块提供了几个常用的可用于实验使用的数据集,如下所示:
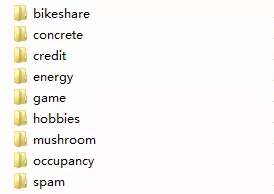
进入到对应数据集文件夹下面,都会有三个文件,对于bikeshare如下:

其中:bikeshare.csv为数据集文件,如:

Meta.json为字段元信息文件,如:
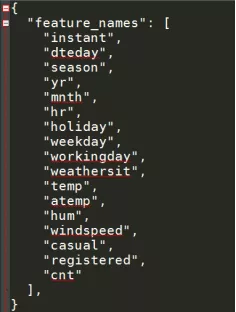
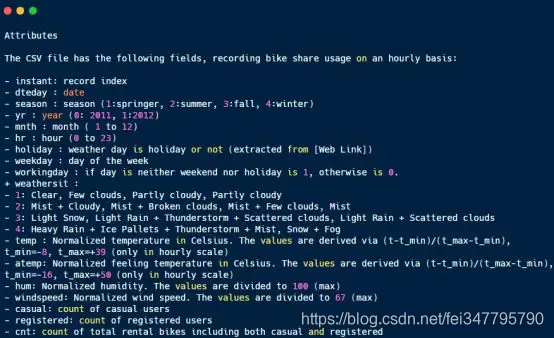
README.md为介绍说明文件,如:
基于共享单车数据集,简单的数据分析工作实现如下:
1 def testFunc5(savepath='Results/bikeshare_Rank2D.png'): 2 ''' 3 共享单车数据集预测 4 ''' 5 data=pd.read_csv('bikeshare/bikeshare.csv') 6 X=data[["season", "month", "hour", "holiday", "weekday", "workingday", 7 "weather", "temp", "feelslike", "humidity", "windspeed" 8 ]] 9 y=data["riders"] 10 visualizer=Rank2D(algorithm="pearson") 11 visualizer.fit_transform(X) 12 visualizer.poof(outpath=savepath) 13 14 15 def testFunc6(savepath='Results/bikeshare_temperate_feelslike_relation.png'): 16 ''' 17 进一步考察相关性 18 ''' 19 data=pd.read_csv('bikeshare/bikeshare.csv') 20 X=data[["season", "month", "hour", "holiday", "weekday", "workingday", 21 "weather", "temp", "feelslike", "humidity", "windspeed"]] 22 y=data["riders"] 23 visualizer=JointPlotVisualizer(feature='temp', target='feelslike') 24 visualizer.fit(X['temp'], X['feelslike']) 25 visualizer.poof(outpath=savepath) 26 27 28 def testFunc7(savepath='Results/bikeshare_LinearRegression_ResidualsPlot.png'): 29 ''' 30 基于共享单车数据使用线性回归模型预测 31 ''' 32 data = pd.read_csv('bikeshare/bikeshare.csv') 33 X=data[["season", "month", "hour", "holiday", "weekday", "workingday", 34 "weather", "temp", "feelslike", "humidity", "windspeed"]] 35 y=data["riders"] 36 X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3) 37 visualizer=ResidualsPlot(LinearRegression()) 38 visualizer.fit(X_train, y_train) 39 visualizer.score(X_test, y_test) 40 visualizer.poof(outpath=savepath) 41 42 43 def testFunc8(savepath='Results/bikeshare_RidgeCV_AlphaSelection.png'): 44 ''' 45 基于共享单车数据使用AlphaSelection 46 ''' 47 data=pd.read_csv('bikeshare/bikeshare.csv') 48 X=data[["season", "month", "hour", "holiday", "weekday", "workingday", 49 "weather", "temp", "feelslike", "humidity", "windspeed"]] 50 y=data["riders"] 51 alphas=np.logspace(-10, 1, 200) 52 visualizer=AlphaSelection(RidgeCV(alphas=alphas)) 53 visualizer.fit(X, y) 54 visualizer.poof(outpath=savepath) 55 56 57 def testFunc9(savepath='Results/bikeshare_Ridge_PredictionError.png'): 58 ''' 59 基于共享单车数据绘制预测错误图 60 ''' 61 data=pd.read_csv('bikeshare/bikeshare.csv') 62 X=data[["season", "month", "hour", "holiday", "weekday", "workingday", 63 "weather", "temp", "feelslike", "humidity", "windspeed"]] 64 y=data["riders"] 65 X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3) 66 visualizer=PredictionError(Ridge(alpha=3.181)) 67 visualizer.fit(X_train, y_train) 68 visualizer.score(X_test, y_test) 69 visualizer.poof(outpath=savepath)
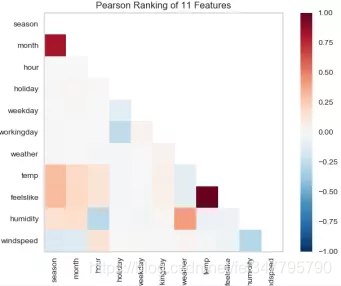
bikeshare_Rank2D.png特征相关性计算
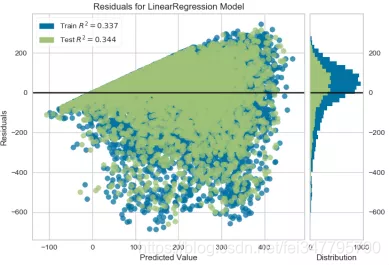
bikeshare_LinearRegression_ResidualsPlot.png使用线性回归模型预测
bikeshare_RidgeCV_AlphaSelection.png使用AlphaSelection特征选择
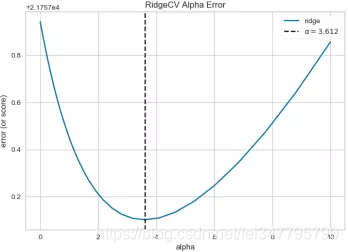
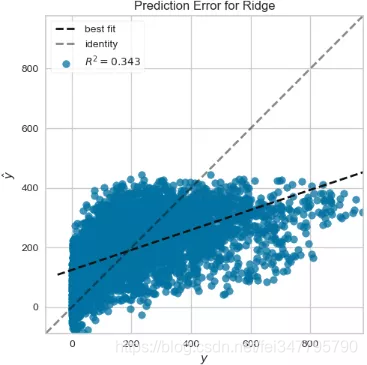
bikeshare_Ridge_PredictionError.png绘制预测错误图
除了可以直接对数据进行分析展示之外,Yellowbrick同样可以对文本数据进行处理分析,下面我们基于爱好数据集进行简单的使用说明,具体代码实现如下所示:
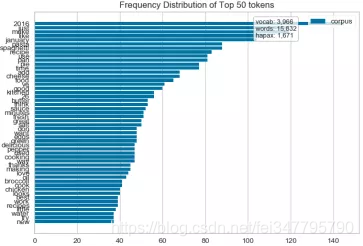
1 def hobbiesFreqDistVisualizer(): 2 ''' 3 文本可视化 4 Token 频率分布:绘制语料库中令牌的频率 5 t-SNE 语料库可视化:绘制更接近发现聚类的类似文档 6 ''' 7 corpus=load_corpus("data/hobbies") 8 vectorizer = CountVectorizer() 9 docs = vectorizer.fit_transform(corpus.data) 10 features = vectorizer.get_feature_names() 11 visualizer = FreqDistVisualizer(features=features) 12 visualizer.fit(docs) 13 visualizer.poof(outpath='text_hobbies_FreqDistVisualizer.png') 14 #去停用词 15 vectorizer = CountVectorizer(stop_words='english') 16 docs = vectorizer.fit_transform(corpus.data) 17 features = vectorizer.get_feature_names() 18 visualizer = FreqDistVisualizer(features=features) 19 visualizer.fit(docs) 20 visualizer.poof(outpath='text_hobbies_FreqDistVisualizer_stop_words.png') 21 22 23 def hobbiesFreqDistVisualizer2(): 24 ''' 25 探索 烹饪和游戏 两种爱好的频度分布 26 (报错:没有label,应该为corpus.target) 27 ''' 28 corpus=load_corpus("data/hobbies") 29 #烹饪爱好频度分布统计图 30 hobbies=defaultdict(list) 31 for text,label in zip(corpus.data,corpus.target): 32 hobbies[label].append(text) 33 vectorizer = CountVectorizer(stop_words='english') 34 docs = vectorizer.fit_transform(text for text in hobbies['cooking']) 35 features = vectorizer.get_feature_names() 36 visualizer = FreqDistVisualizer(features=features) 37 visualizer.fit(docs) 38 visualizer.poof(outpath='text_hobbies_cooking_FreqDistVisualizer.png') 39 #游戏爱好频度分布统计图 40 hobbies=defaultdict(list) 41 for text,label in zip(corpus.data, corpus.target): 42 hobbies[label].append(text) 43 vectorizer = CountVectorizer(stop_words='english') 44 docs = vectorizer.fit_transform(text for text in hobbies['gaming']) 45 features = vectorizer.get_feature_names() 46 visualizer = FreqDistVisualizer(features=features) 47 visualizer.fit(docs) 48 visualizer.poof(outpath='text_hobbies_gaming_FreqDistVisualizer.png') 49 50 51 def hobbiesTSNEVisualizer(): 52 ''' 53 t-SNE语料库可视化 54 T分布随机邻域嵌入,t-SNE。Scikit-Learn将此分解方法实现为sklearn.manifold.TSNE转换器。 55 通过使用来自原始维度和分解维度的不同分布将高维文档向量分解为二维。 通过分解为2维或3维, 56 可以使用散点图来显示文档。 57 ''' 58 corpus=load_corpus("data/hobbies") 59 tfidf = TfidfVectorizer() 60 docs = tfidf.fit_transform(corpus.data) 61 labels = corpus.target 62 tsne = TSNEVisualizer() 63 tsne.fit(docs, labels) 64 tsne.poof(outpath='text_hobbies_TSNEVisualizer.png') 65 #Don't color points with their classes 66 tsne = TSNEVisualizer(labels=["documents"]) 67 tsne.fit(docs) 68 tsne.poof(outpath='text_hobbies_TSNEVisualizer_nocolor.png') 69 70 71 def hobbiesClusterTSNEVisualizer(): 72 ''' 73 聚类应用 74 ''' 75 corpus=load_corpus("data/hobbies") 76 tfidf = TfidfVectorizer() 77 docs = tfidf.fit_transform(corpus.data) 78 clusters=KMeans(n_clusters=5) 79 clusters.fit(docs) 80 tsne=TSNEVisualizer() 81 tsne.fit(docs,["c{}".format(c) for c in clusters.labels_]) 82 tsne.poof(outpath='text_hobbies_cluster_TSNEVisualizer.png')
text_hobbies_FreqDistVisualizer.png
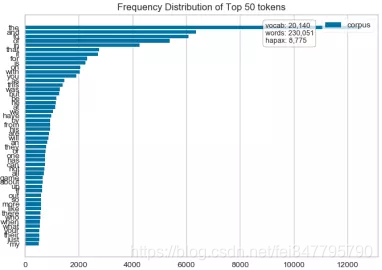
text_hobbies_FreqDistVisualizer_stop_words.png
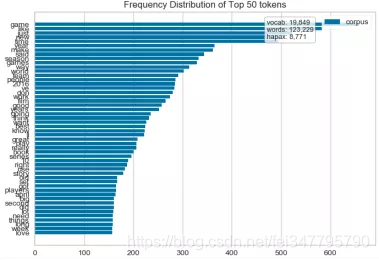
text_hobbies_cooking_FreqDistVisualizer.png